




- @qq_52128187
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
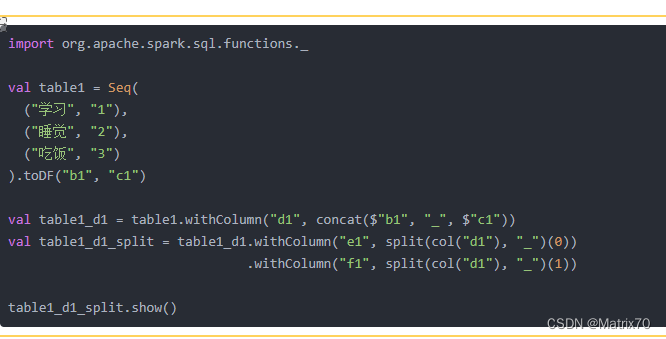
包含两列的DataFrame进行转换和拆分,我想实现的是将dataframe表table1中的字段b1与c1的内容使用下划线_连接起来列的名字为d1,比如比如学习_1,睡觉_2,吃饭_3,这是我的第一个需求;随后我想保留的是dataframe表table1中的字段d1中的数据比如学习_1,睡觉_2,吃饭_3,中的数据中_前后的数据分别作为两列e1,f1,
如果报主键冲突了,则group by 一下id,date,然后select 的时候加一个count(1) >1,语句如下。基本上对这个id的去重就ok,视情况而定,我的数据是建立在id这一列,id,对应的后续的其他数据都是一样的,所以我可以这么整。检查一下看看是否入库前删除了分区的数据,可能是重复数据入库的问题,如果不是这个那么继续排查。基本上我就是这么解决的。其他的暂时还没遇到过。我造了三条数据

MySQL数据库同步操作指南:将开发库与测试库分离时,通过Navicat工具实现表结构和数据同步。操作步骤包括:1.确保数据库连接正常且有权限;2.在Navicat中分别连接源库和目标库;3.使用工具栏的"数据传输"功能;4.配置源库和目标库;5.选择需要传输的表;6.点击开始执行同步。该方法适用于目标库表未创建时同步表结构和数据的需求。
本文总结了大表数据(日均五六千万)处理中的去重优化和资源调优经验。Hive入库阶段通过distinct()、dropDuplicates()、开窗函数等多重去重策略确保数据唯一性。Hive到Oracle迁移时发现NULL值导致主键冲突和资源不足问题,通过NULL值预处理和调整Executor配置(最终采用45G内存)解决。关键经验包括:早期处理NULL值、渐进式资源调优、多维度监控指标及详细文档记
本文总结了大表数据(日均五六千万)处理中的去重优化和资源调优经验。Hive入库阶段通过distinct()、dropDuplicates()、开窗函数等多重去重策略确保数据唯一性。Hive到Oracle迁移时发现NULL值导致主键冲突和资源不足问题,通过NULL值预处理和调整Executor配置(最终采用45G内存)解决。关键经验包括:早期处理NULL值、渐进式资源调优、多维度监控指标及详细文档记
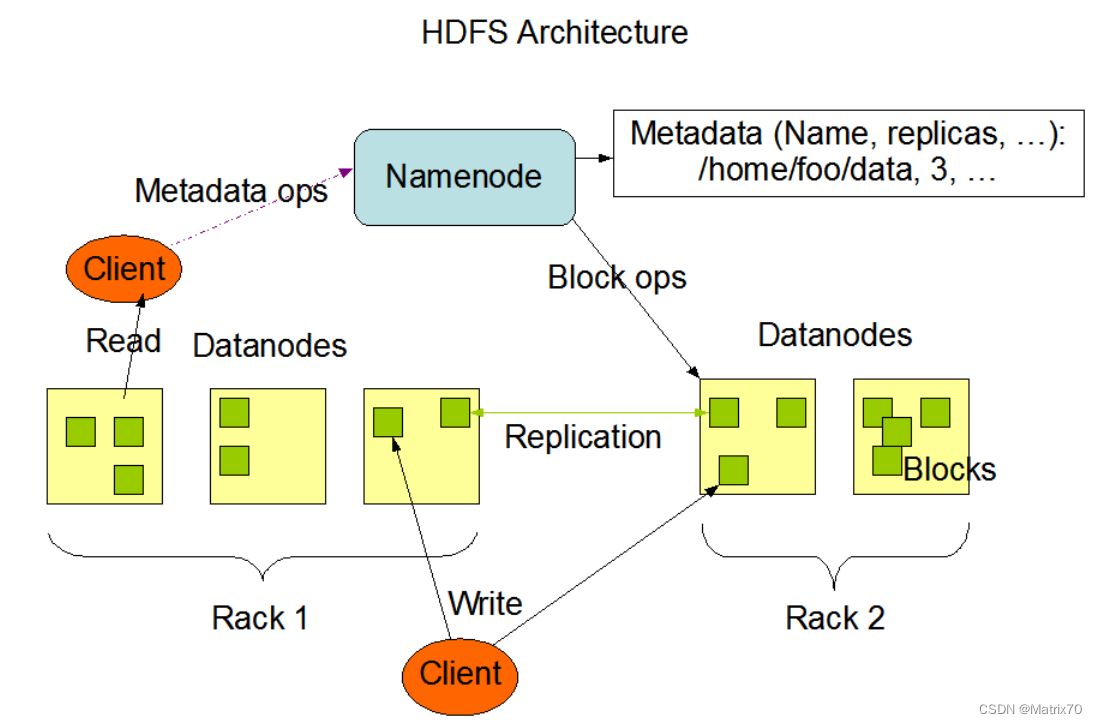
NameNode根据一定的策略选择可用的DataNode,并为文件的每个数据块分配一个主节点(Primary DataNode)和多个副本节点(Replica DataNode),NameNode返回文件的数据节点列表给客户端。5、客户端根据数据节点列表,将数据切分成数据块,并按照指定的策略将这些数据块依次写入各个DataNode的数据节点。主节点将数据块按照指定的格式进行存储,并将数据复制到副本
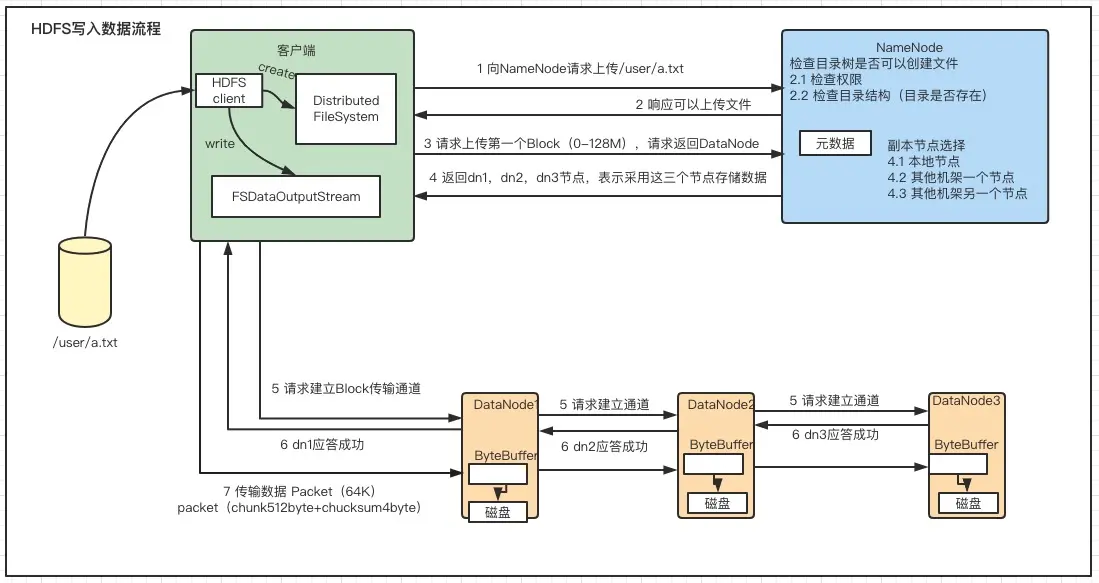
本篇博客参照hadoop官网,介绍HDFS的NN及DN,副本存放机制(机架感知策略),安全模式,文件系统元数据持久化(editlog,fsimage),HDFS健壮性,数据组织及存储空间的回收,重点介绍DataNode及NameNode及机架感知策略
我是用的是scala2.11.8,Spark3.2.0版本的,是不匹配的。Spark 3.2.0需要 Scala 2.12+,需要将项目编译为 Scala 2.12+ 才能使用 Spark 3.2.0。否则,需要使用 Spark 3.1.x 的版本和 Scala 2.11.x 的版本。下载并安装Hadoop的二进制文件,并将其解压缩到正确的目录中(例如,C:/Hadoop/)。由于scala版本与

这篇博客介绍的是HDFS的NameNode,DataNode,ZKFC,JournalNode的功能以及他们之间的联系。细节部分是Checkpoint机制(检查点)的原理,HA机制,ZKFC以及JournalNode在这里面起到的不可忽视的作用,蛮细的。
