




- @qq_50530107
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(4)更简洁的API:Spark提供了Scala、Java和Python等多种编程语言的API,而且相对于Hadoop MapReduce,Spark的API更加简洁易用,开发人员可以更快速地开发出复杂的分布式应用程序。、试述如下Spark的几个概念:RDD,DAG,阶段,分区,窄依赖,宽依赖 RDD(弹性分布式数据集,Resilient Distributed Dataset):是Spark中最
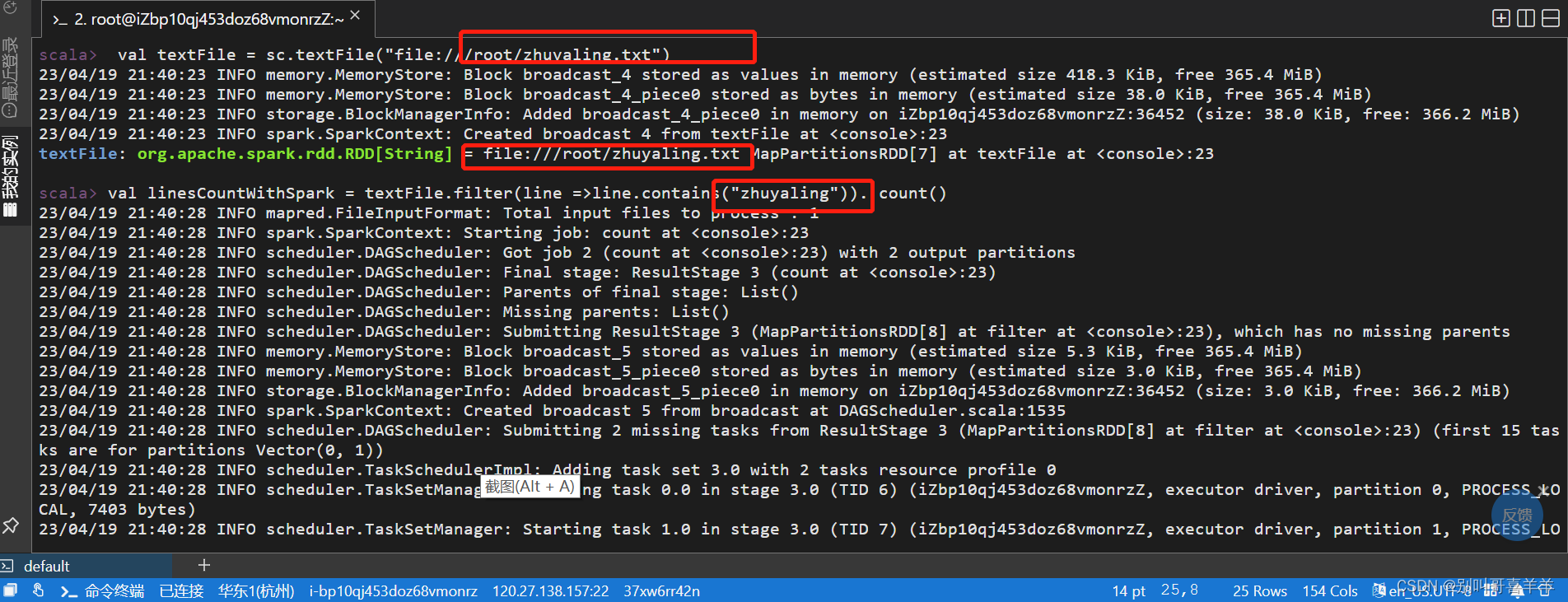
输入密码:输入密码时,命令行窗口不会显示密码,输完之后直接回车;提供了临时视图的创建,创建完临时视图后就可以像操作表一样使用。进入【实验操作桌面】,打开浏览器进入华为云登录页面。同样,可以查询每门课程的最高分数和平均分数。要求查询出相同课程中每个人分数的排名。按钮,进行基础的华为云服务预置。点击实验桌面左上角,账号下方的。查询每门课程最高分数和平均分数。,执行如下命令(使用弹性公网。在【实验操作桌
Spark最初是为批处理开发的,但现在已经支持流处理,可以在内存中处理大型数据集和流数据,它支持的编程语言包括Java、Python和Scala等。: Flink是一种基于内存的流处理框架,被认为是Storm的替代方案,它支持批处理和流处理,具有比Storm更好的容错性和更好的性能,支持Java和Scala编程语言。综上所述,Spark适合处理大规模数据集和流数据,可以提供全面的功能,Flink是
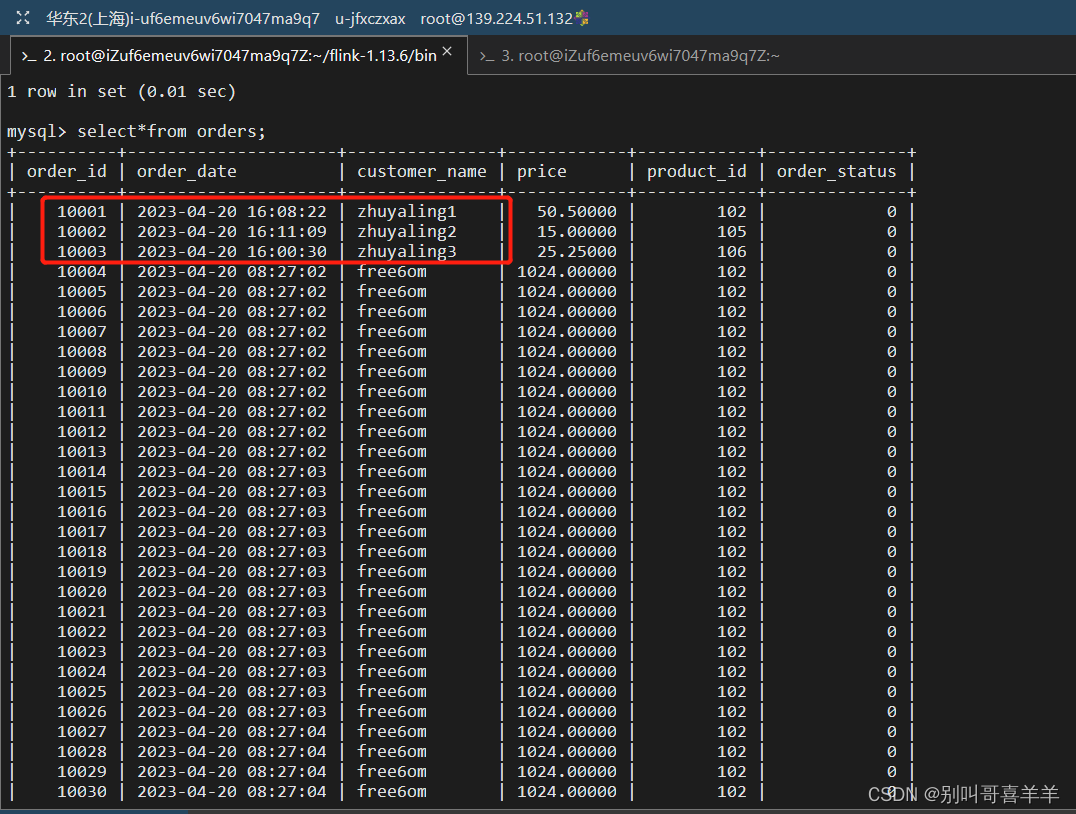
HDFS的数据节点负责处理客户端的读写请求,并将客户端发来的文件分割成存储块,将每个存储块中的数据保存到本地,还会将这些存储块复制到名称节点指定的若干数据节点,以实现冗余存储。答:HDFS联邦中的“块池”,是指每个数据节点所能够存储的最大的数据块数量,它的功能是为了更好的管理数据块的存储空间,可以根据块池大小,为不同的DataNode分配不同的数据块存储空间,当某个NameNode失效时,它所相关
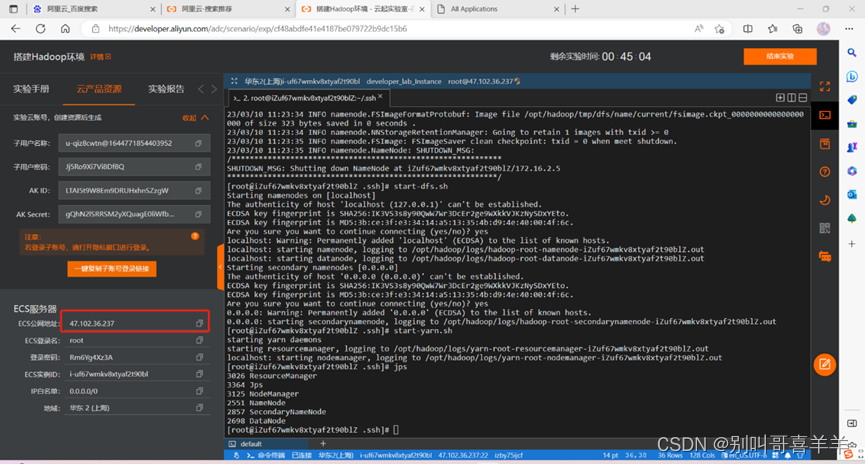
优点: 多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中 缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。每个Store对应了表中
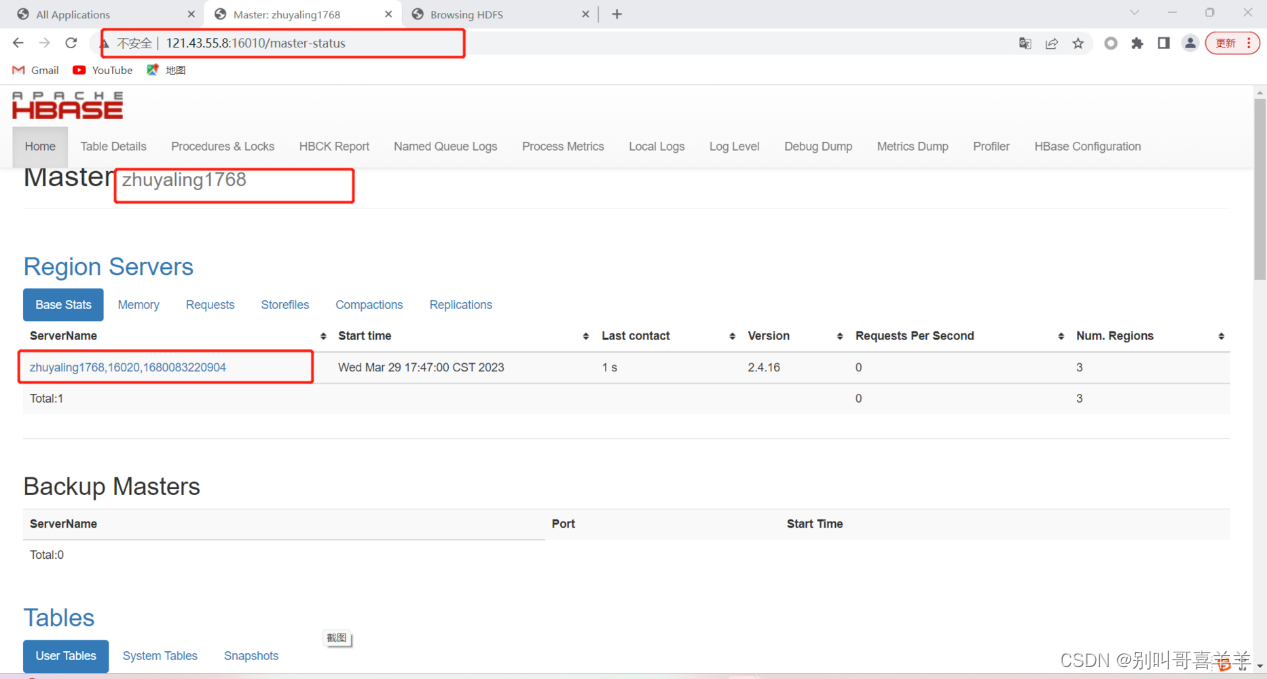
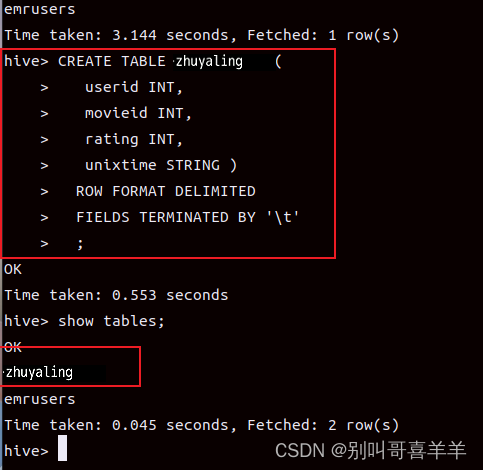
答:HiveQL是类似于SQL的查询语言,它的语法与SQL相似,但是有一些不同之处。Hive与Hadoop生态系统的组件之间的相互关系:Hive与Hadoop生态系统中的其他组件(如HDFS、YARN、MapReduce等)紧密集成,Hive底层使用HDFS存储数据,使用YARN管理作业,使用MapReduce进行计算。Hive与传统数据库的区别:Hive是一种基于Hadoop生态系统的数据仓库,
优点: 多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中 缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。每个Store对应了表中
优点: 多个Region对象的更新操作所发生的日志修改,只需要不断把日志记录追加到单个日志文件中,不需要同时打开、写入到多个日志文件中 缺点:如果一个Region服务器发生故障,为了恢复其上次的Region对象,需要将Region服务器上的对象,需要将Region服务器上的HLog按照其所属的Region对象进行拆分,然后分发到其他Region服务器上执行恢复操作。每个Store对应了表中