




- @qq_47896523
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
图像分割是医学图像分析的核心任务。它通常用于量化感兴趣的体积/器官的大小和形状、人口研究、疾病量化、治疗计划和计算机辅助干预。医学图像分割中的经典方法涵盖从区域生长[11]和可变形模型[36]到基于图集的方法[32]、贝叶斯方法[29]、图割[26]、聚类方法[12]等。目前工作的一个共同特征是使用卷积运算作为网络的主要构建块。所提出的网络架构在卷积运算的排列方式方面也有所不同。人们已经尝试使用循

医学成像是诊断多种疾病和分析实验结果的重要工具。生物医学成像是整体癌症护理基础的一部分。数字乳腺X线摄影Digital Mammography(DM)是乳腺癌诊断中最常用和最实用的技术。DM 成像在致密乳房中存在一些弱点,其中肿瘤可能被周围组织隐藏(致密组织与肿瘤相比具有类似的衰减)。在实践中,超声 (US) 成像是 DM 的最佳替代方法,由于其敏感性、安全性和多功能性,它被用作乳腺癌分类和检测的

开发了一种深度学习算法,该算法可以使用“端到端”训练方法在筛查乳房 X 光检查中准确检测出乳腺癌,该方法有效地利用了具有完整临床注释或仅具有整个图像的癌症 标签 的训练数据集。在这种方法中,仅在初始训练阶段才需要病变注释,后续阶段只需要图像级标签,从而消除了对很少可用的病变注释的依赖。与以前的方法相比,我们用于对筛查乳房 X 光检查进行分类的全卷积网络方法获得了出色的性能。作为图像分类任务,通过筛
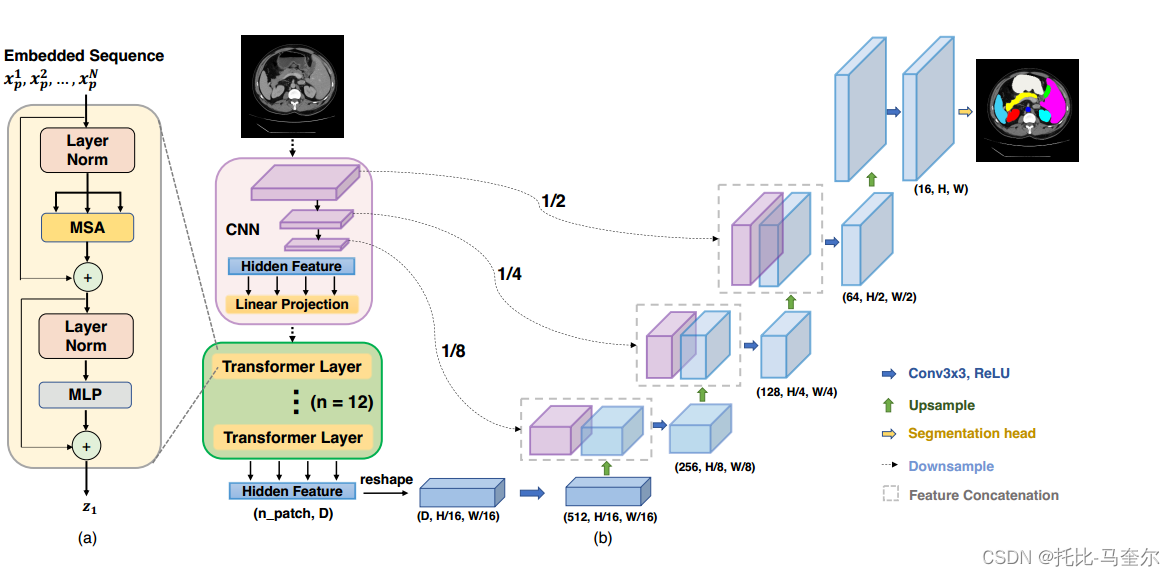
具有收缩和扩展路径的全卷积神经网络 (FCNN) 在大多数医学图像分割应用中表现出了突出的作用。在 FCNN 中,编码器通过学习全局和局部特征以及上下文表示来发挥不可或缺的作用,这些特征和上下文表示可用于解码器的语义输出预测。在FCNN中,收缩路径通常用于捕获图像的上下文信息,并逐步减少空间维度;而扩展路径则用于恢复空间维度,使输出图像的尺寸与输入图像相近,并提供更精细的分割结果。FCNN中卷积层

U-Net 由对称的编码器-解码器网络组成,具有跳跃连接以增强细节保留,已成为事实上的选择。基于这种方法,在广泛的医学应用中取得了巨大的成功,例如磁共振(MR)的心脏分割、计算机断层扫描(CT)的器官分割和息肉从结肠镜检查视频中分割。与之前基于 CNN 的方法不同,Transformers 不仅在建模全局上下文方面功能强大,而且在大规模预训练下也表现出了对下游任务的卓越可迁移性。
PyTorch版深度学习中基本的数据操作和数据的预处理操作

一些常用的卷积神经网络(Convolutional Neural Network, CNN)及其变体,如AlexNet、VGGNet、GoogleNet等,在乳腺癌分类中容易出现过拟合的问题,这主要是由于乳腺病理图像数据集的规模较小,以及过于自信的softmax-cross-entropy loss。为了缓解过拟合问题以获得更好的分类准确性,提出了一种新的乳腺病理分类框架,称为AlexNet-BC
开发了一种新的DCN,它能够处理乳房x线摄影筛查的多个视图,并利用大分辨率图像而不缩小。将这种DCN称为多视图深度卷积网络(MV-DCN)。网络学习预测放射科医生的评估,将传入的样本分类为BI-RADS 0(“不完整”),BI-RADS 1(“正常”)或BI-RADS 2(“良性发现”)。研究了数据集大小和图像分辨率对所提出的MV-DCN筛选性能的影响,这将作为优化未来深度神经网络用于医学成像的事
本研究提出了一种基于 mini-MIAS 训练的 CNN 形式的新型深度学习模型,用于对良性和恶性异常进行分类。为了增强图像特征并提高分类性能,提出了一种预处理算法,该算法使用一系列预处理方法,例如裁剪、GCN、局部直方图均衡化和平衡预处理。CNN 模型以原始图像的 ROI 作为输入,实现异常的特征学习和分类。为了满足乳腺图像的要求,提出了一种数据增强方法来改善数据稀缺性并防止过度拟合。探索 CN
开发了一种深度学习算法,该算法可以使用“端到端”训练方法在筛查乳房 X 光检查中准确检测出乳腺癌,该方法有效地利用了具有完整临床注释或仅具有整个图像的癌症 标签 的训练数据集。在这种方法中,仅在初始训练阶段才需要病变注释,后续阶段只需要图像级标签,从而消除了对很少可用的病变注释的依赖。与以前的方法相比,我们用于对筛查乳房 X 光检查进行分类的全卷积网络方法获得了出色的性能。作为图像分类任务,通过筛