- @qq_47865838
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
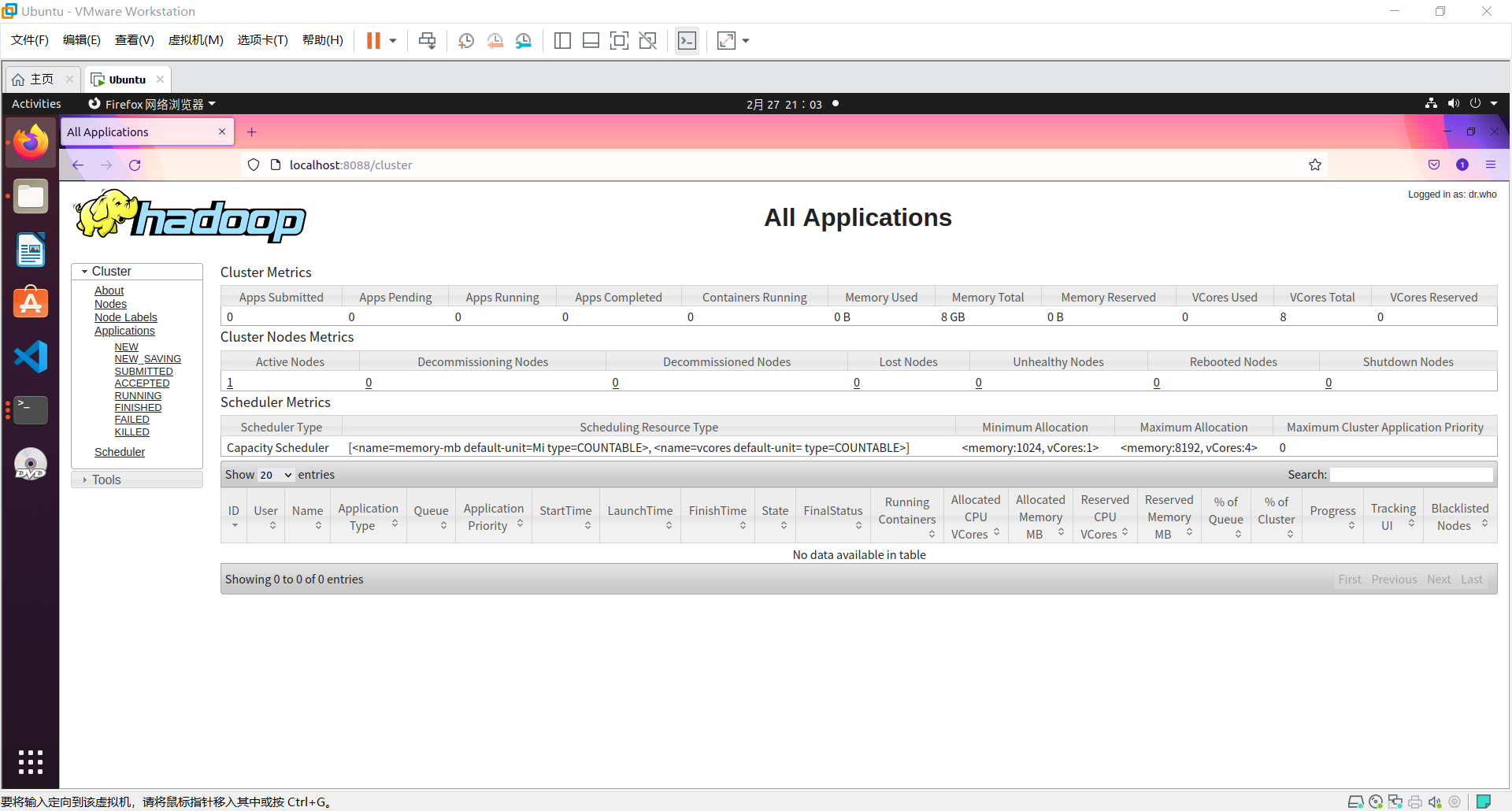
山东大学机器学习实验5报告实验学时: 6实验日期:2021.11.20文章目录山东大学机器学习实验5报告实验题目 — Experiment 5 : SVM实验目的实验环境软件环境实验步骤与内容了解SVM二次规划求解Kernel Methods 核函数软间隔SVM:Task 1: Linear SVMPlot decision boundary of the SVMUse the test data
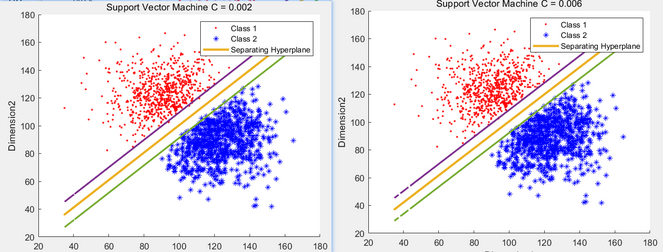
基于Dynamic Web + JSP + Hive +Mysql + Spark 实现的双十一购物数据可视化分析,使用Echarts可视化,spark 的 SVM进行回头客预测
网络放大器问题描述对于一个石油传送网络可由一个加权有向无环图G表示。该图中有一个称为源点的顶点S ( 保证S的入度为0 ) , 从S出发 , 石油流向图中的其他顶点 . G中每条边上的权重为它所连接的两点间的距离。在输送石油的过程中 , 需要有一定的压力才能使石油从一个点到达另一个点,但压力会随着路程的增加而降低 ( 即压力的损失量是路程的函数 ) .因此为了保证石油在网络的正常运输,在网络传输中
Hadoop环境配置(Linux虚拟机)本学期选了大数据管理与分析这门课,主要使用Hadoop框架下进行数据分析与应用开发,在此先进行环境配置注意最好把JDK以及Hadoop 放在/usr/local下添加环境变量的时候 可以加到/etc/profile或者 按照该链接 w3cshcool的教材进行配置(强烈推荐)环境要求单机Hadoop的安装安装JDK链接https://www.oracle.c