




- @qq_47814951
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
环境:win11+wsl2+docker,但主要操作在wsl中完成。
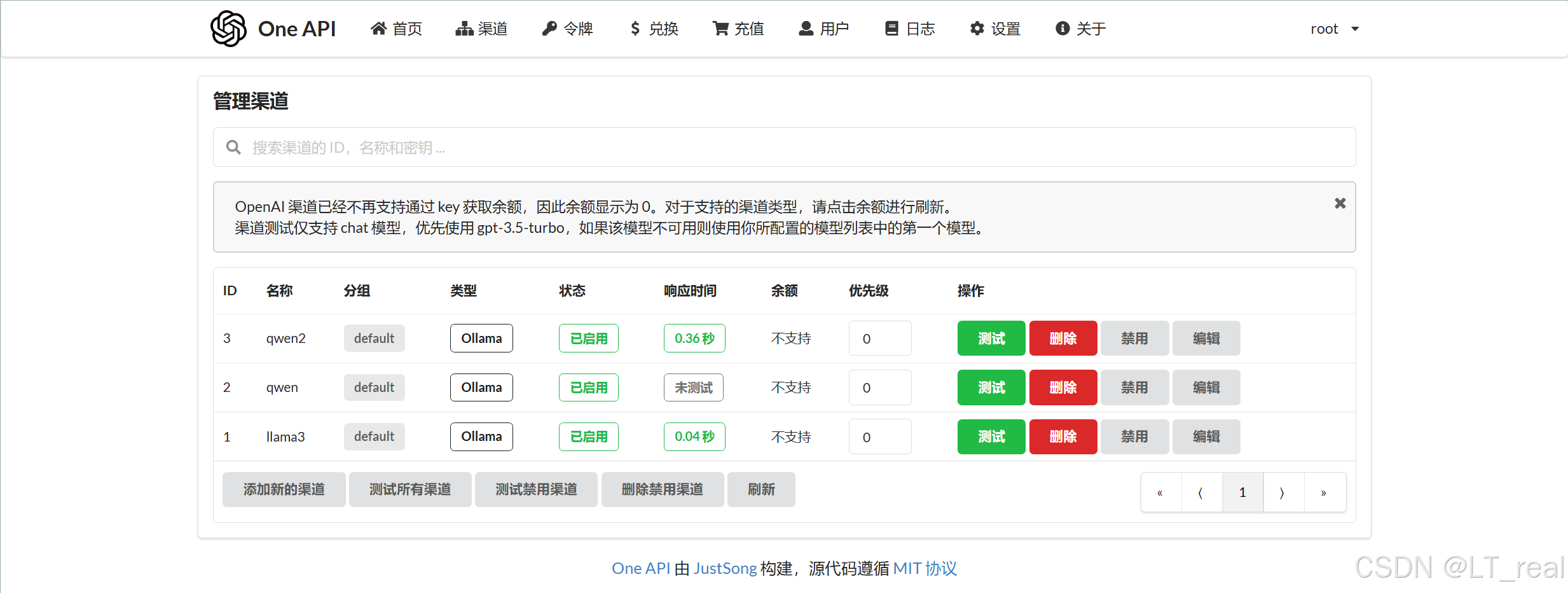
在linux系统中,简单使用nginx反向代理docker中容器提供的服务。

如果配置不对,重装!如果有奇怪的错误,重启!(基本解决99%问题)
本文主要为个人查询网络资料的总结,便于后续的学习过程,如有不妥,敬请指教。
本文以DeepSeek-R1-Distill-Qwen-7B大模型为例,详细解析了大模型文件的结构及其参数意义。主要文件包括config.json(模型架构配置)、generation_config.json(生成控制配置)、tokenizer_config.json(分词器配置)及model.safetensors(模型权重文件)等。文章对比了不同模型文件的差异,如DeepSeek与Qwen系列

我这边离线机器跑起来居然没有报错,成功后可以访问10012端口看看,一般会显示detail Not Found,访问后缀加/web/index.html即可进入聊天页面。其中gguf_path为gguf文件路径,需要有config配置文件在同一路径;记录一次在离线机器上使用kt框架部署Deepseek:671B模型过程。model_path为模型路径,不知道为什么没有后会报错(再看看;cpu_in

我这边离线机器跑起来居然没有报错,成功后可以访问10012端口看看,一般会显示detail Not Found,访问后缀加/web/index.html即可进入聊天页面。其中gguf_path为gguf文件路径,需要有config配置文件在同一路径;记录一次在离线机器上使用kt框架部署Deepseek:671B模型过程。model_path为模型路径,不知道为什么没有后会报错(再看看;cpu_in
本文主要记录入门大模型学习的相关知识,以期为后续工作学习提供帮助。(除了我自己截图外,引用的我尽量标注来源,有些忘记来源了请告诉我orz)
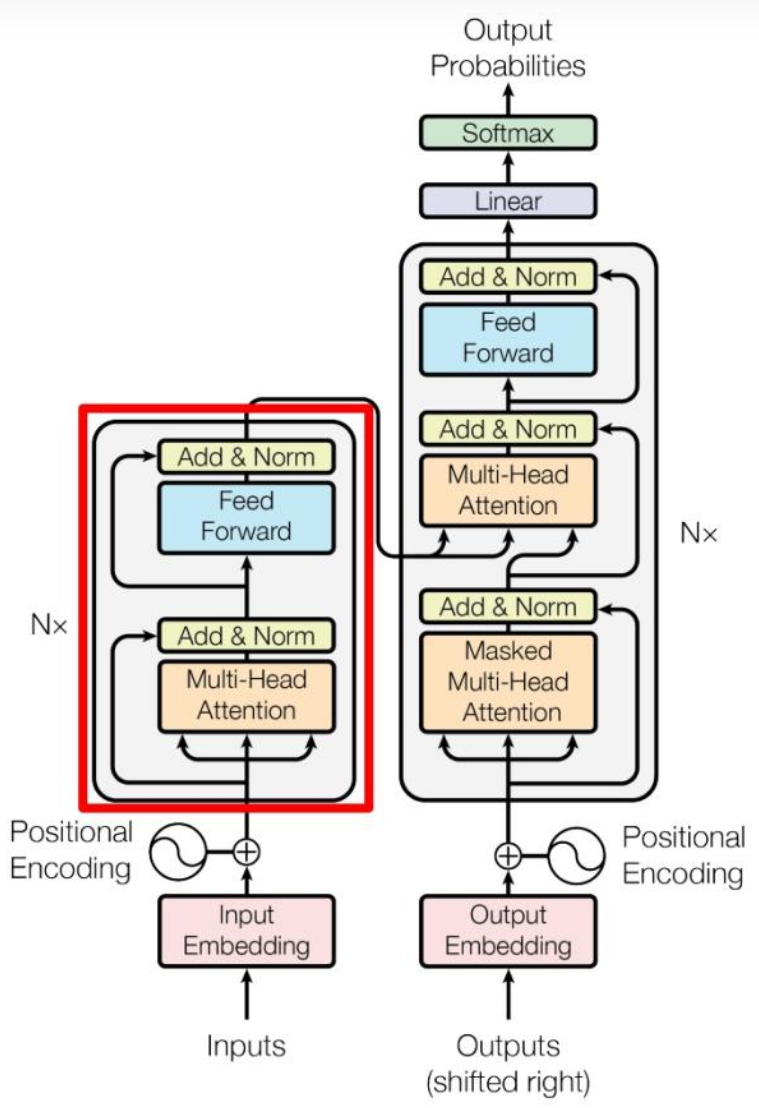
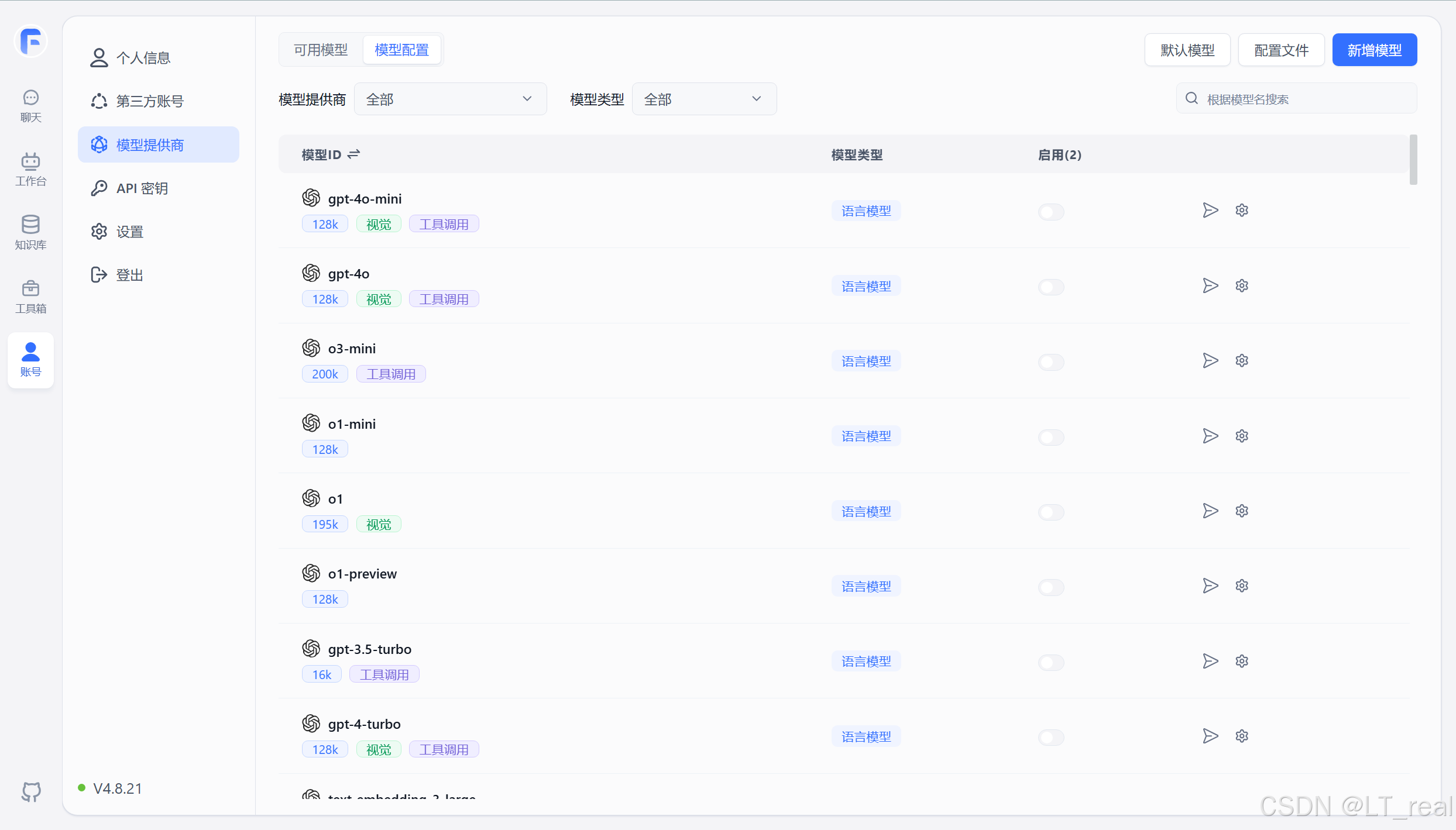
新版本本地化的fastgpt接入重排模型
本文以DeepSeek-R1-Distill-Qwen-7B大模型为例,详细解析了大模型文件的结构及其参数意义。主要文件包括config.json(模型架构配置)、generation_config.json(生成控制配置)、tokenizer_config.json(分词器配置)及model.safetensors(模型权重文件)等。文章对比了不同模型文件的差异,如DeepSeek与Qwen系列