- @qq_46316392
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果我们公司或者本地有部署大模型,输入公司大模型的名称和url即可,api-key如果有就输入,没有的话直接忽视就好,其他的一些选择如:function call 大家按需选择即可。(如果公司的url较长,我们选择路径到v1即可)然后点击安装,如果安装之后没有出现这个供应商,建议多刷新几次或者多点几次安装。我们点击这个模型右侧的添加模型按钮。随后就跳转到了添加模型的界面。
有些小伙伴可能需要对dify的前后端源码都进行修改,发现修改之后的代码没有起到作用,这里我根据自己的经验写了一篇前后分离的部署流程,可以让自己修改的dify前后端源码运行成功。部署的教程,可以供大家参考。
如果我们公司或者本地有部署大模型,输入公司大模型的名称和url即可,api-key如果有就输入,没有的话直接忽视就好,其他的一些选择如:function call 大家按需选择即可。(如果公司的url较长,我们选择路径到v1即可)然后点击安装,如果安装之后没有出现这个供应商,建议多刷新几次或者多点几次安装。我们点击这个模型右侧的添加模型按钮。随后就跳转到了添加模型的界面。
有些小伙伴可能需要对dify的前后端源码都进行修改,发现修改之后的代码没有起到作用,这里我根据自己的经验写了一篇前后分离的部署流程,可以让自己修改的dify前后端源码运行成功。部署的教程,可以供大家参考。
如果我们公司或者本地有部署大模型,输入公司大模型的名称和url即可,api-key如果有就输入,没有的话直接忽视就好,其他的一些选择如:function call 大家按需选择即可。(如果公司的url较长,我们选择路径到v1即可)然后点击安装,如果安装之后没有出现这个供应商,建议多刷新几次或者多点几次安装。我们点击这个模型右侧的添加模型按钮。随后就跳转到了添加模型的界面。
自己在工作中因为涉及到对dify的迁移问题,于是自己根据网上的资料和自己工作的需求实现了两种数据迁移方式。
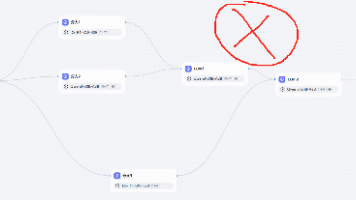
Dify中的并行工作流结构解析:主要包括简单并行、嵌套并行和复杂结构三种形式。简单并行允许多个分支同时运行;嵌套并行是在并行分支中再构建并行结构;复杂结构中需注意节点依赖关系,避免因变量缺失导致报错。正确做法是在依赖节点前加入同步节点,形成合理的双分支嵌套并行结构,确保工作流正常运行。
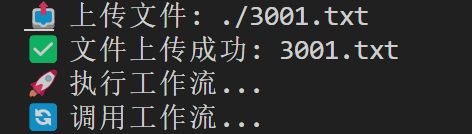
介绍了如何使用Python代码调用Dify API进行文件上传和工作流执行。主要内容包括: 提供了完整的DifyAPIClient类实现,包含文件上传和运行工作流两个核心方法 详细说明了配置参数的修改方法: API_KEY:工作流API密钥 BASE_URL:Dify服务地址 FILE_PATH:待上传文件路径 WORKFLOW_INPUTS:工作流输入参数 演示了如何根据需要开启/关闭文件上传功
如果我们公司或者本地有部署大模型,输入公司大模型的名称和url即可,api-key如果有就输入,没有的话直接忽视就好,其他的一些选择如:function call 大家按需选择即可。(如果公司的url较长,我们选择路径到v1即可)然后点击安装,如果安装之后没有出现这个供应商,建议多刷新几次或者多点几次安装。我们点击这个模型右侧的添加模型按钮。随后就跳转到了添加模型的界面。
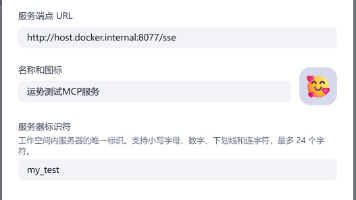
Dify 1.6.0版本对MCP模块进行了优化升级,新版MCP调用方式更简单高效。文章详细介绍了配置流程:首先通过FastMCP创建服务器(示例提供了数字占卜功能的Python代码),然后在Dify界面添加MCP服务(需注意本地Docker部署的特殊配置)。配置完成后,用户可在Agent或工作流中调用MCP工具,示例展示了如何将数字占卜工具集成到智能体中,并演示了通过ReAct策略进行问答交互的完