




- @qq_46094651
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
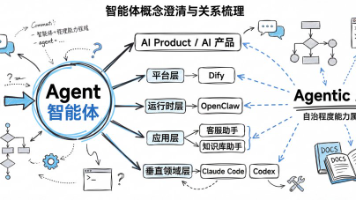
本文深入探讨了“智能体”概念的混乱现状,追溯了其学术起源,并区分了平台层、运行时层、应用层和垂直领域层的不同含义。文章强调“智能体”的核心在于感知、决策和行动,而非简单的聊天功能,并阐述了“agentic AI”的自治性和执行性特点。最后,文章提出了一个实用的分层框架,帮助读者清晰理解不同类型的“智能体”,为深入学习和应用大模型技术奠定基础。这两年,和客户聊 AI 安全方案时,我越来越强烈地感受到
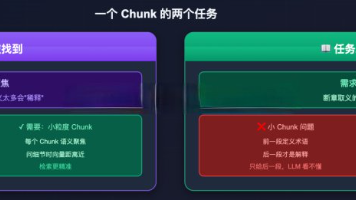
回到开头那个面试场景。索引层——解决"知识怎么存",核心矛盾是检索粒度 vs 上下文完整性,主流解法 Parent-Child查询层——解决"问题怎么转",主流四招 Query 改写 / Multi-Query / HyDE / Step-back召回层——解决"从哪几条路找",向量 + BM25 + 元数据多路并行,RRF 做融合重排序层——解决"谁最相关",Cross-encoder 对粗召候
最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续
最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续
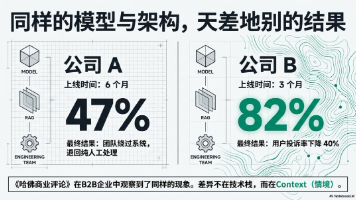
模型决定AI能够如何思考,Context决定AI能够完成什么。前者可以靠选型和采购解决,后者只能靠进入现场来解决。这也是为什么FDE的核心价值,是比别人更懂现场。懂现场,才能理解Context;理解Context,才能让模型真正工作。前两期说的是AI交付的障碍——Demo和生产之间的工程距离,Agent和责任之间的设计距离。这一期的问题更底层:就算障碍都解决了,决定AI系统真正表现的,是什么?
最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

最近两年互联网招人逻辑完全换了赛道:只会写基础业务代码、天天做CRUD的传统开发岗位越来越少,能落地AI大模型、帮公司做业务智能化的技术人,成了各大大厂抢着要的香饽饽。2026年春招市场,大模型相关岗位直接稳居招聘第一位!AI相关岗位数量同比暴涨8.7倍,在所有新经济岗位里占比从2.78%飙升到22.03%,简单说:10个技术岗,2个都是AI大模型岗。头部大厂2026春招全员押注AI,传统岗位持续

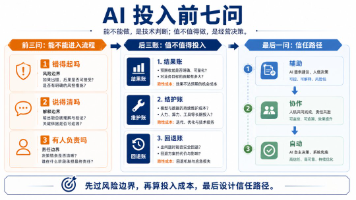
回到开头的问题:为什么很多企业用了 AI,却没有明显变强?答案可能并不复杂。它们不是没有投入,也不是没有试点,更不是没有学习外部案例,而是它们经常从错误的问题出发。它们从“AI 能做什么”出发,而不是从“我的商业持续成功靠什么”出发;它们追逐先锋实践,却没有建立自己的判断框架;它们把组织变革当成答案,却没有先想清楚真正要放大的经营能力。AI 时代真正稀缺的,不只是生成能力,而是克制能力。克制看见别
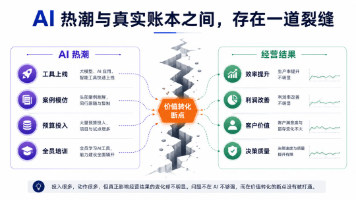
网上到处都是AI相关的新闻和报道,感觉有了AI人都自然成为配角一样。然而90%的企业的一线岗位,从工作流程到方式几乎依旧一成不变。这中间到底出了什么问题?AI 在企业里到底能不能用、怎么用、值不值得用?本文就此问题进行解析,并介绍几个可以落地的场景。经专业机构统计,企业级 AI 落地的真实情况如下:80% 的 POC(概念验证)项目没有进入生产环境能落地的项目中,90% 集中在三类场景:客服、文档
