
写文章




- @qq_45276194
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
【李沐论文精读】CLIP改进工作串讲精读
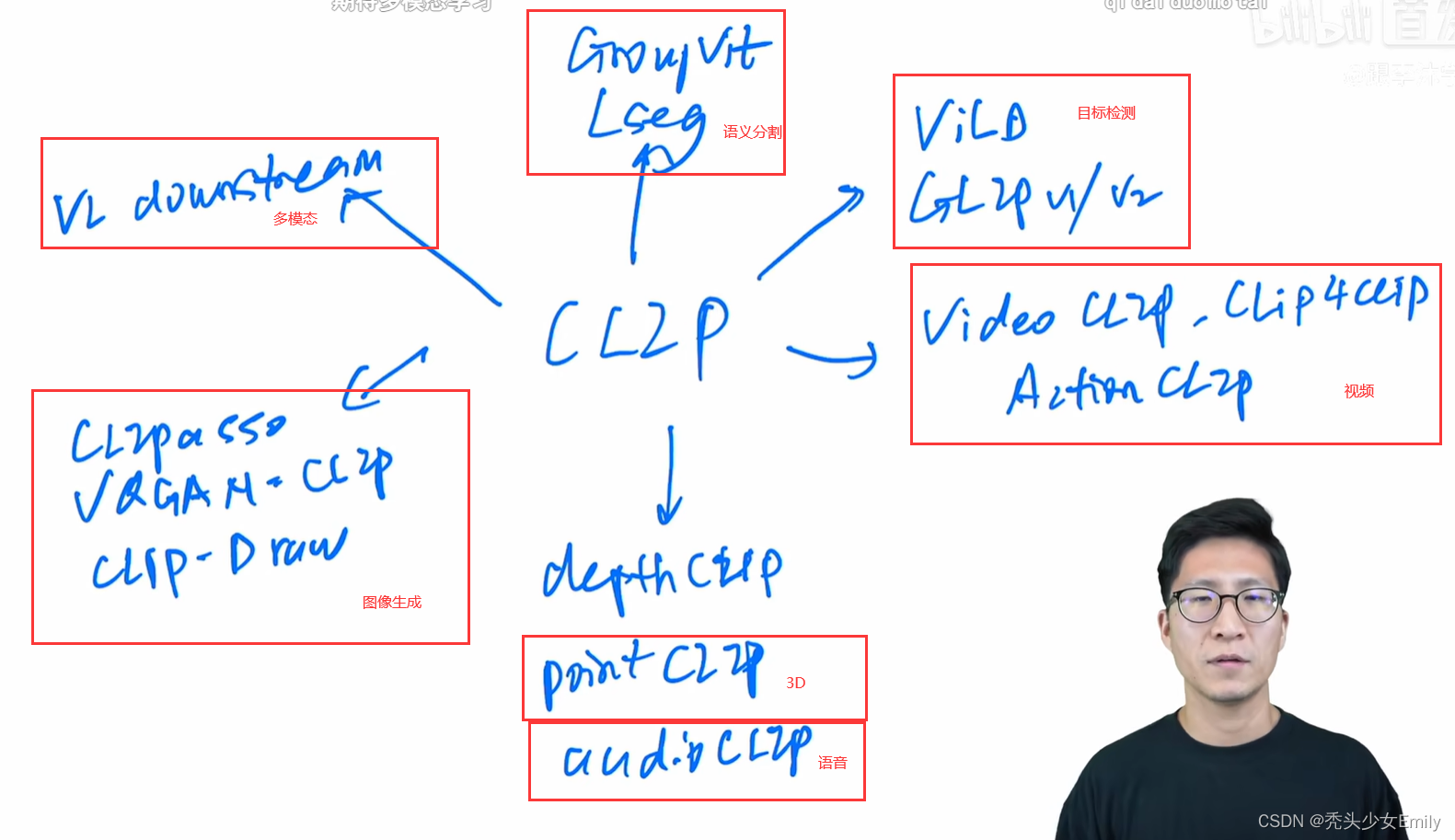
LSeg、GroupViT、ViLD、GLIP、GLIPv2、CLIPPasso、CLIP4Clip、Action CLIP
【李沐论文精读】Transformer精读
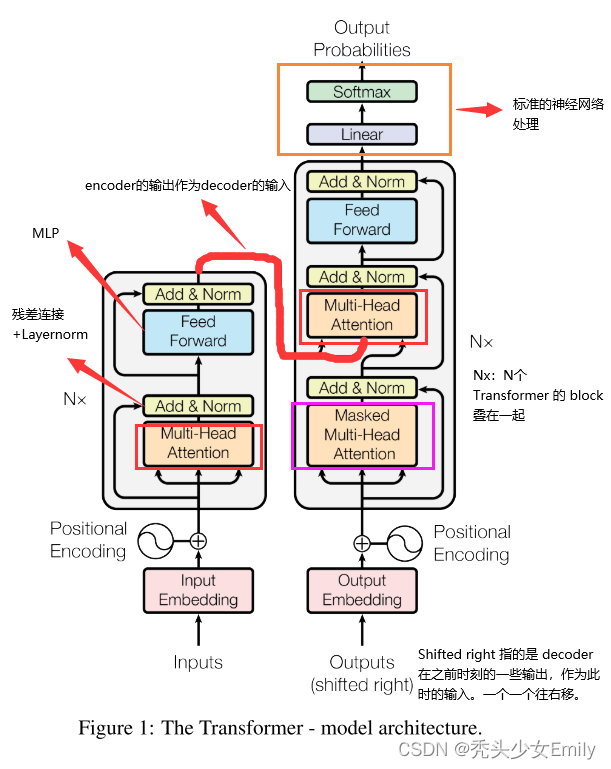
主流的序列转换(sequence transduction)模型都是基于复杂的循环或卷积神经网络,这个模型包含一个编码器(encoder)和一个解码器(decoder)。具有最好性能的模型在编码和解码之间通过一个注意力机制链接编解码器。我们提出了一个新的简单网络架构——基于attention 的Transformer。其仅仅是基于注意力机制,而完全不需要之前的循环或卷积。在两个机器翻译任务上的实验
【李沐论文精读】CLIP精读
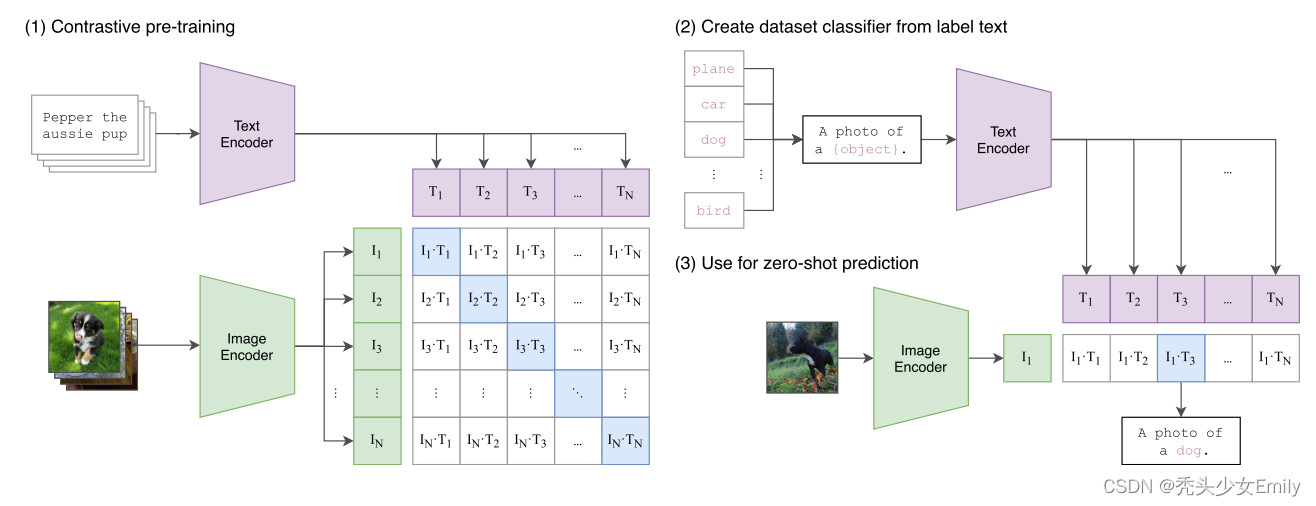
是一种基于对比文本-图像对的预训练方法。CLIP用文本作为监督信号来训练可迁移的视觉模型,使得最终模型的zero-shot效果堪比ResNet50,泛化性非常好。CLIP算是在跨模态训练无监督中的开创性工作,作者在开头梳理了现在vision上的训练方式,从有监督的训练,到弱监督训练,再到最终的无监督训练。这样训练的好处在于可以避免的有监督的 categorical label的限制,具有zero-
到底了