




- @qq_45156060
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Word2Vec是一种用于处理自然语言处理的模型,它是在2013年由Google的研究员Mikolov等人首次提出的。Word2Vec通过训练海量的文本数据,能够将每个单词转换为一个具有一定维度的向量。这个向量就可以代表这个单词的语义。因为这个向量是在大量语境中学到的,所以这个向量能很好的表达这个单词的语义。Word2Vec包括Skip-Gram和CBOW两种模型,主要是通过优化模型计算词与词之间

在未来几周内还会发布70亿参数的Phi-3-small和140亿参数的Phi-3-medium两款小模型。据悉,Phi-3-mini是微软Phi家族的第4代,有预训练和指令微调多种模型,参数只有38亿训练数据却高达3.3T tokens,比很多数百亿参数的模型训练数据都要多,这也是其性能超强的主要原因之一。2023年12月,微软在Phi-1.5基础之上开发了Phi-2,参数只有27亿并且在没有人类

EMO模型是阿里巴巴智能计算研究院通过深度学习技术研发的一款强大的视频生成工具。它能够仅凭一张静态图片和一段语音,生成具有丰富表情和真实头部动作的视频,从而打破传统视频制作的局限。阿里发布了一个大模型的展示页面,提出了一个名叫的大模型,一种富有表现力的音频驱动的基于人物肖像生成视频的框架。具体来讲就是,输入单个参考人物肖像图像和语音(例如讲话或者唱歌等),可以生成具有丰富的面部表情和各种头部姿势的

敬请期待Qwen2!近期,在开源社区中,一系列具有千亿参数规模的大模型陆续出现,这些模型在各类评测中取得了卓越的成绩。该模型在基础能力评估中与Meta-Llama3-70B相媲美,并在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。下面是关于基础语言模型效果的评估,并与最近的SOTA语言模型Meta-Llama3-70B以及Mixtral-8x22B进行了比较。与之前发
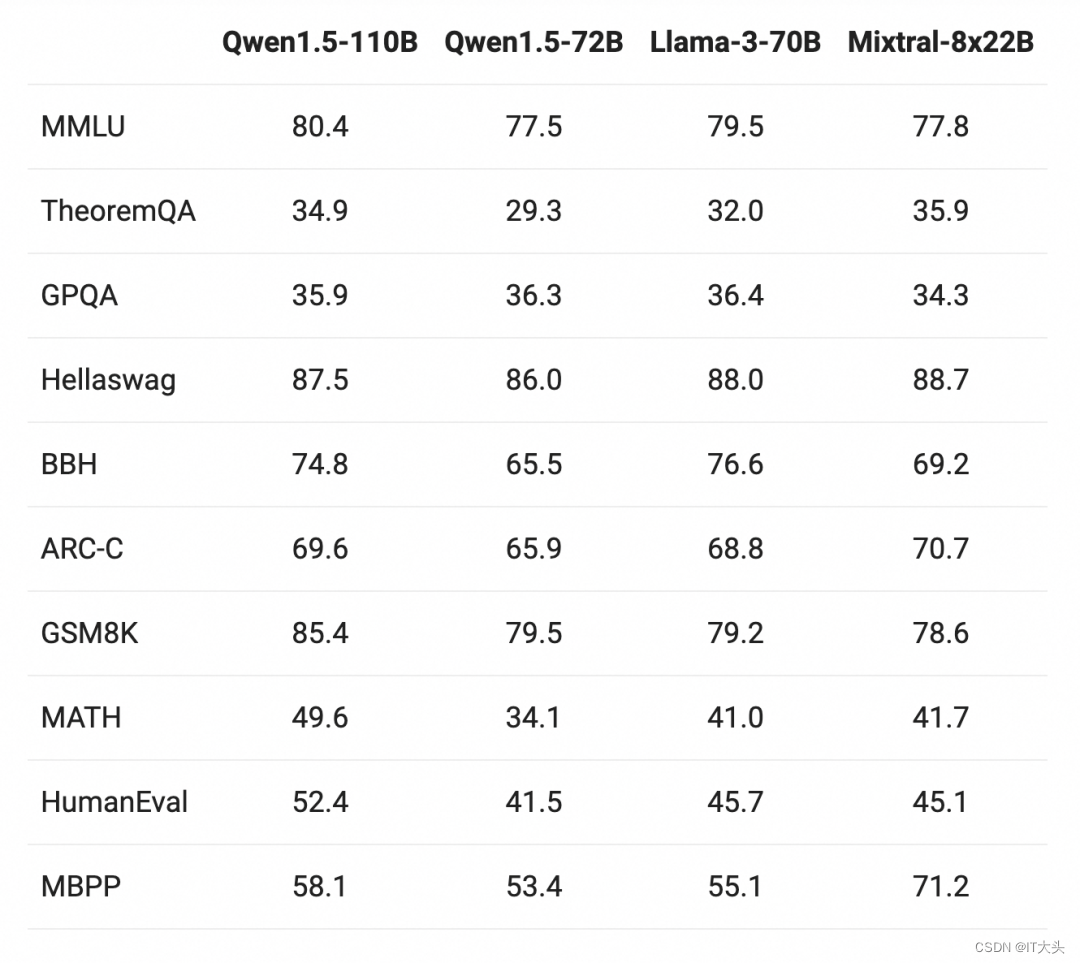
敬请期待Qwen2!近期,在开源社区中,一系列具有千亿参数规模的大模型陆续出现,这些模型在各类评测中取得了卓越的成绩。该模型在基础能力评估中与Meta-Llama3-70B相媲美,并在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。下面是关于基础语言模型效果的评估,并与最近的SOTA语言模型Meta-Llama3-70B以及Mixtral-8x22B进行了比较。与之前发
敬请期待Qwen2!近期,在开源社区中,一系列具有千亿参数规模的大模型陆续出现,这些模型在各类评测中取得了卓越的成绩。该模型在基础能力评估中与Meta-Llama3-70B相媲美,并在Chat评估中表现出色,包括MT-Bench和AlpacaEval 2.0。下面是关于基础语言模型效果的评估,并与最近的SOTA语言模型Meta-Llama3-70B以及Mixtral-8x22B进行了比较。与之前发
网上有关tesseract-ocr如何安装编译的资料很多,但是总有一些问题出现,笔者也是在不停的摸索下安装成功,希望对大家有帮助

docker快速部署milvus2.x版本及可视化工具
docker快速部署milvus2.x版本及可视化工具

在这里,我们定义了一个标记化函数,用于将原始文本和标签转换为标记化的文本和标签序列。我们还定义了一个填充函数,用于对序列进行填充,以便它们可以被批处理。在这里,我们使用了BERT模型和BiLSTM层来提取句子的特征,然后通过全连接层将其映射到标签空间,并使用CRF层来对标签序列进行建模。在这里,我们使用Adam优化器和交叉熵损失函数来训练模型。然后,我们使用测试集来评估模型的性能,并使用模型来预测
