- @qq_44777595
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
变异系数(Coefficient of Variation):当需要比较两组数据离散程度大小的时候,如果两组数据的测量尺度相差太大,或者数据量纲的不同,直接使用标准差来进行比较不合适,此时就应当消除测量尺度和量纲的影响,而变异系数可以做到这一点,它是原始数据标准差与原始数据平均数的比。通过变异系数可知,第一支股票的业绩表现的变异系数较小,因此它的业绩表现较第二支股票稳定;标准差有计量单位,而方差无

以上就是爬取简历模板的全部过程,程序中只爬取了第一、二、三页,如果想获取更多的模板,可以修改for循环翻页中的数字。在程序中,为了分解每个步骤,把各个部分的代码分开写。可以尝试将各个步骤合并起来,比如,获取到模板详情页的URL之后,对该URL发起请求来获取模板的下载地址,再对下载地址发起请求来将文件保存到本地,需要多嵌套几层循环。该网站中还有其他模板,比如ppt、各种类型的图片等等。如果感兴趣可以

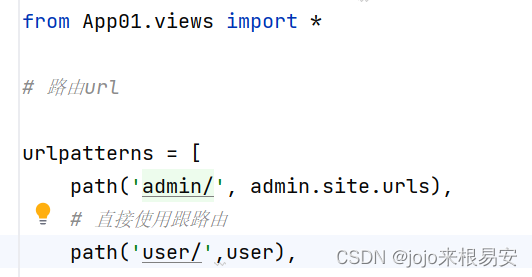
在实际开发过程中,一个Django项目会包含很多的app,这时候如果我们只在主路由里进行配置就会显得杂乱无章,所以通常会在每一个app里,创建各自的urls.py模块,然后从跟路由出发,将app所属的url请求,全部转发到相应的urls.py模块中。而这个从主路由转发到各个应用路由的过程叫做路由的分发。
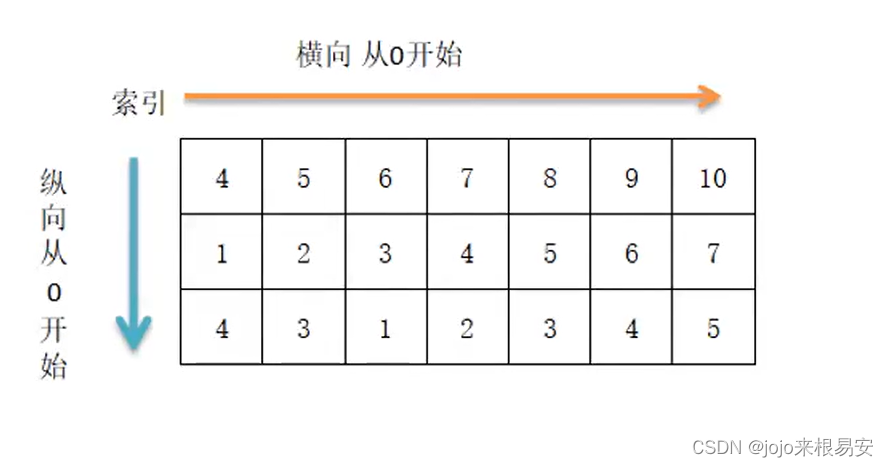
ndarray对象的内容可以通过索引或切片来访问和修改,与Python中list的切片操作一样。ndarray数组可以基于0-n的下标进行索引注意:区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始数组都会跟着更改)。这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。通过切片和copy复制原列表都是复制赋值,通过直接等于是引用赋值。冒号:的
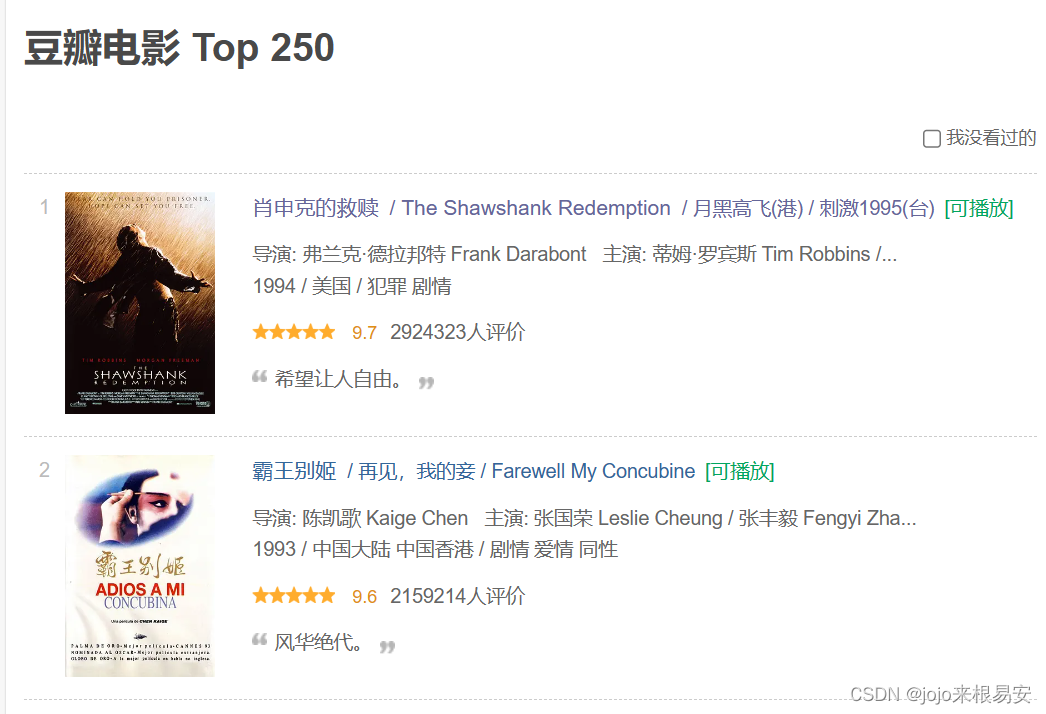
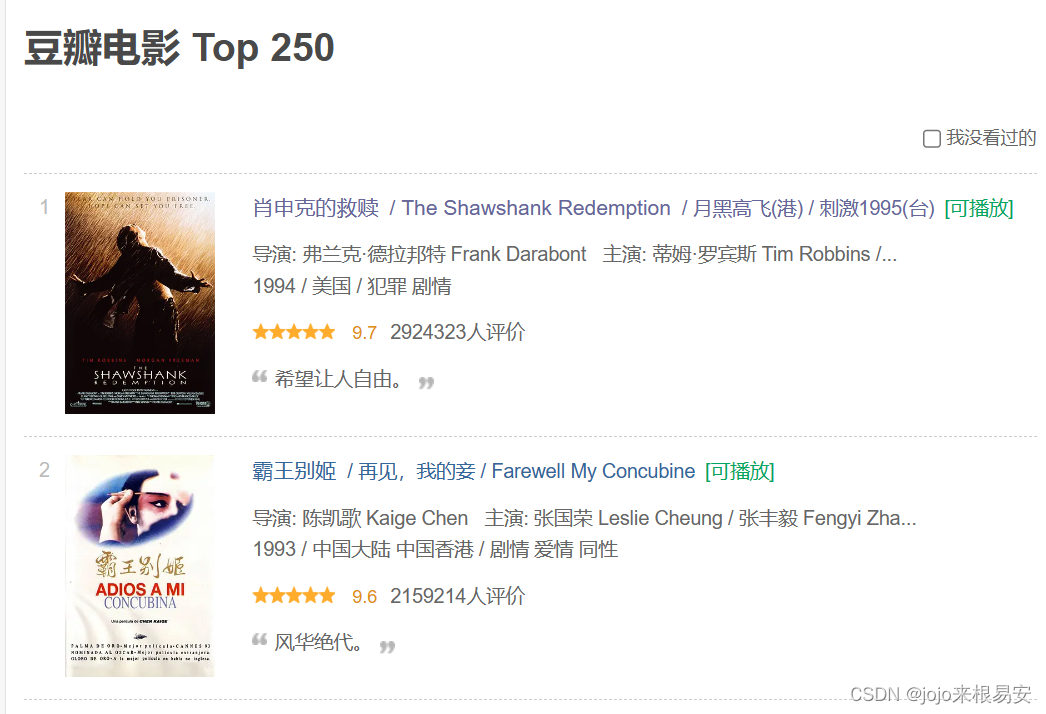
本次程序只爬取了豆瓣top250电影的展示页面的数据,没有爬取电影详情页的数据。在前面我们已经获取了每一部电影详情页的链接links,如果想要爬取电影的详情页,可以通过for循环遍历列表links,对每一个详情页发起请求,从而获取电影详情页的数据并进行解析。
ndarray对象的内容可以通过索引或切片来访问和修改,与Python中list的切片操作一样。ndarray数组可以基于0-n的下标进行索引注意:区别在于数组切片是原始数组视图(这就意味着,如果做任何修改,原始数组都会跟着更改)。这也意味着,如果不想更改原始数组,我们需要进行显式的复制,从而得到它的副本(.copy())。通过切片和copy复制原列表都是复制赋值,通过直接等于是引用赋值。冒号:的
1、需要注意响应内容是否与网页源码格式相同2、编写正则表达式时需要将网页源码或者响应内容中的对应元素复制出来,观察其格式,按照格式去编写正则表达式3、如果我们查找不到对应的内容,或者只取到对应内容的一部分,则我们需要扩大查找范围,正则表达式的编写从开始标签的下级标签开始查找。4、建议每次获取到数据都输出查看是否是我们想要的格式和内容。
本次程序只爬取了豆瓣top250电影的展示页面的数据,没有爬取电影详情页的数据。在前面我们已经获取了每一部电影详情页的链接links,如果想要爬取电影的详情页,可以通过for循环遍历列表links,对每一个详情页发起请求,从而获取电影详情页的数据并进行解析。