




- @qq_43920838
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
定义ReLU和LeakyReLUrelu = nn.ReLU() # 默认参数print(relu(x)) # 输出: tensor([0., 0., 2.])print(leaky_relu(x))# 输出: tensor([-0.0100, 0.0000, 2.0000])概率化输出将神经网络的原始输出(可能为任意实数)转换为 0 到 1 之间的概率值,且所有类别的概率之和为 1。

但是有个问题就是,实时的这些数据,比如查询天气,并不能得到。因为只是个语言模型。vscode远程连接ubuntu,创建一个新的python文件。我给消息改一改,问问他一加一等于多少。
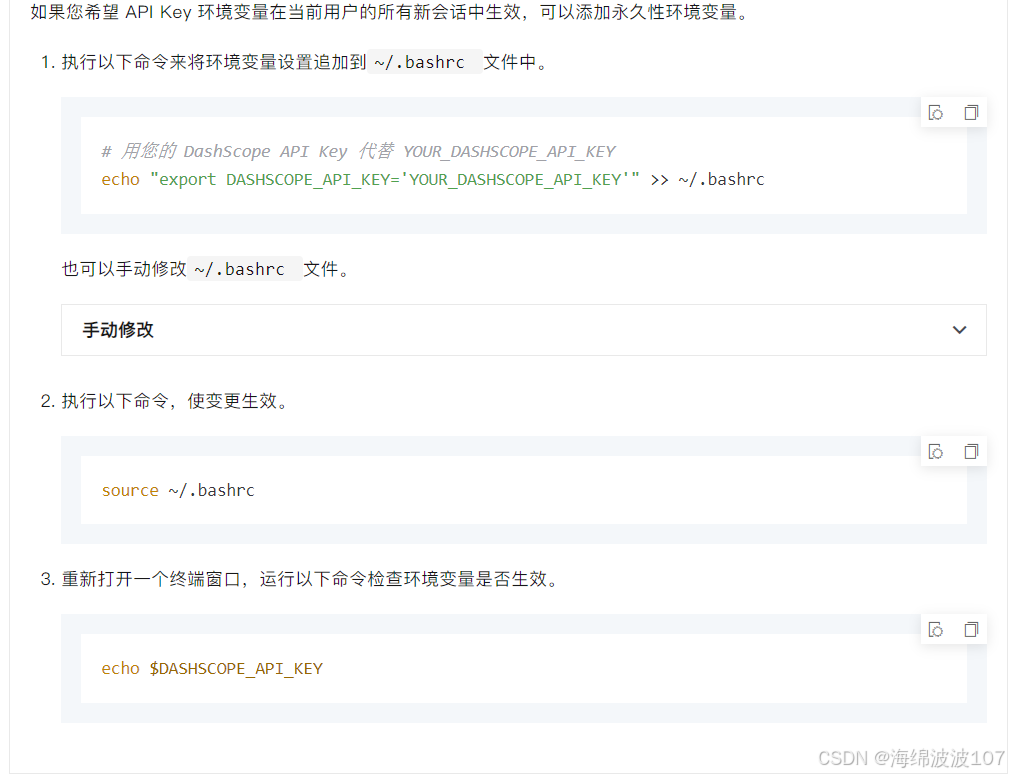
添加上 IdentityFile 选项 //需要修改成自己的私钥路径。

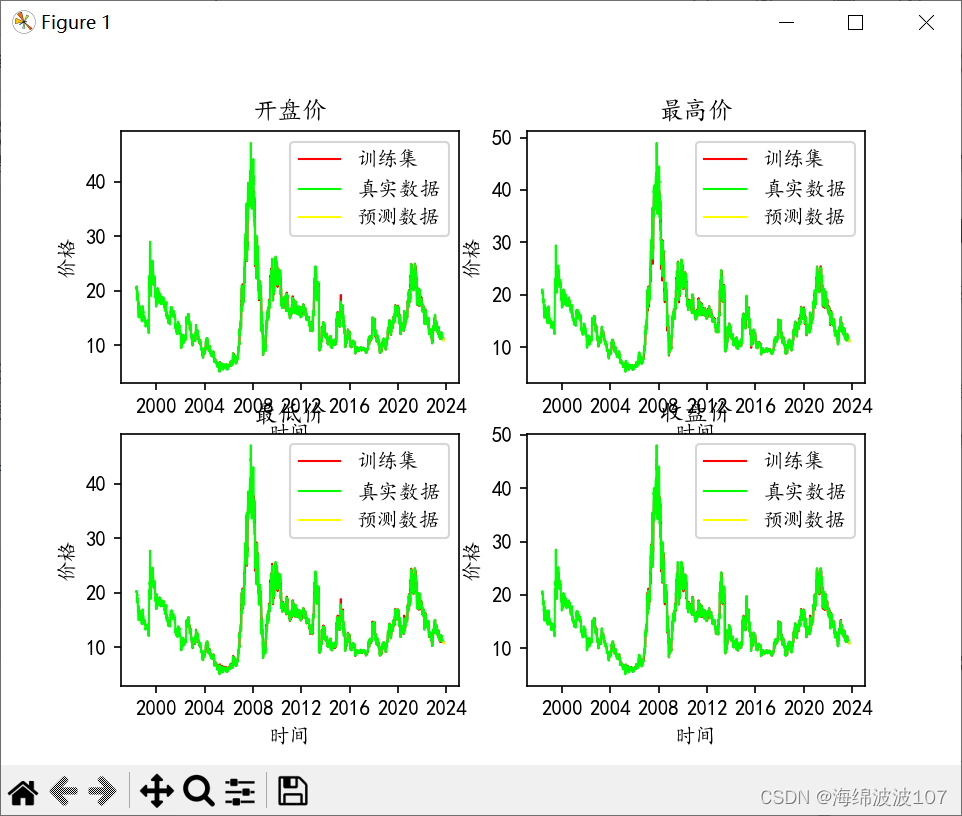
循环神经网络用于时间序列预测比较好,先使用股票价格数据集来理解和掌握该算法。
目前字节火山引擎的稳定性比较好。

它是一个装饰器工厂函数,接收一个权限名称作为参数,返回一个 FastAPI 依赖项用于检查当前请求的用户是否拥有指定的权限。

添加上 IdentityFile 选项 //需要修改成自己的私钥路径。
循环神经网络用于时间序列预测比较好,先使用股票价格数据集来理解和掌握该算法。

单词:在大多数情况下,token指的是文本中的一个单词。例如,在句子 “I love natural language processing” 中,“I”、“love”、“natural”、“language” 和 “processing” 都是token。标点符号:标点符号也可以是token。例如,在句子 “Hello, world!” 中,“,” 和 “!” 都是单独的token。特殊字符:在
