- @qq_43588670
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
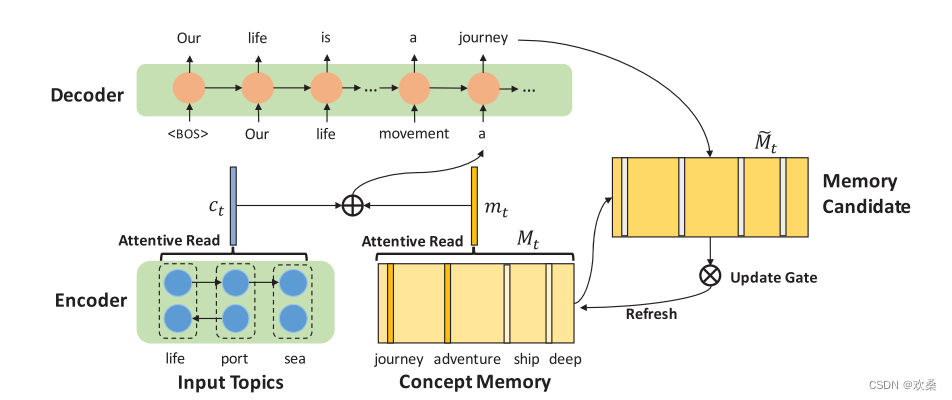
TEG任务是指给定 topic 集合,生成主题相关、段落集的文本。过去的任务忽略了常识知识,本文通过动态记忆机制将外部知识库中的常识集成到生成器中。因为来源信息的极度不足可能会使生成的文章在新颖性和主题一致性方面质量低下。所以在这篇论文中精心设计了一个记忆增强神经模型,有效地融合了常识性知识。其动机是来自外部知识库的常识可以提供额外的背景信息。
工欲善其事必先利其器。先对语料库的进行情感分析,有助于生成更加自然的,多样化的文本。最近读的论文大多数也大都涉及情感分析,所以想要系统学一下,多了解这一方面的技术。下面是我看《网络舆情分析技术》的一些总结(重点在情感分析技术那一章):词语情感分析:名词副词和形容词。包括对此的情感极性,情感强度以及上下文模式等进行分析。借助于标注有情感倾向的情感词典。句子情感分析:主要是判断主观句还是客观句。如果是

上述概念或预训练模型本质上都是为了使得自然语言理解(Natural Language Understanding, NLU)取得更好的效果,以便更好地完成下游任务,或辅助自然语言生成(Natural Language Generation, NLG)任务。

深度学习 Nlp领域总结

大多数现代的NLP系统都遵循一种非常标准的方法来训练各种用例的新模型,即先训练后微调。在这里,预处理训练的目标是利用大量未标记的文本,在对各种特定的任务(如机器翻译、文本摘要等)进行微调之前,建立一个通用的语言理解模型。在本文章中,我们将讨论两种流行的训练前方案,即掩蔽语言建模(MLM)和因果语言建模(CLM)。
我们知道,在NLP领域,特别是工业界中,标签数据是很难获得的,很多时候会面临数据量太小的问题,这个时候,文本数据增强可以有效地帮我们缓解这个问题。我本人在今年的科大讯飞AI大赛中也使用了下文提到的一些方法,并提升了5个百分点左右(后续的文章会详细介绍,请持续关注…),可以说效果是相当明显,所以说数据增强方法绝对是值得大家花点时间学习的。本篇文章,我们将介绍常用的文本数据增强方法,并提供相应的参考文

1 csv文件:逗号分隔符文件,可以使用excel打开。逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值。2 tsv文件:制表符Tab分隔文件,可二以使用文本文档打开。

这周将深度学习的东西写一点总结吧,也算是对研一的一个小总结,要加油呀呀呀。提示:以下是本篇文章正文内容,寻欢桑知识水平有限,请大家多多批评1.IMDB 是一家在线收集各种电影信息的网站 和豆瓣类似,用户可以再上面发表对电影的评价。IMDB数据集御用情感分析的IMDB电影评论二分类数据集,包含25000个训练样本和25000个测试样本,所有影评都被标记为正面和负面两种评价。IMDB数据集地址#导入I