- @qq_43585760
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
新建环境之后,激活时出现“CondaError: Run ‘conda init‘ before ‘conda activate‘”查了好多资料,感觉好麻烦,想着是不是需要重启一下终端?解决方法,关闭终端,重新打开自己解决了。重启终端后试了一下,解决了!
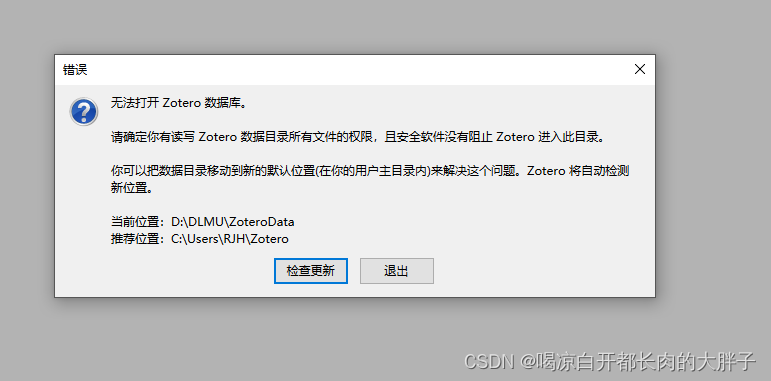
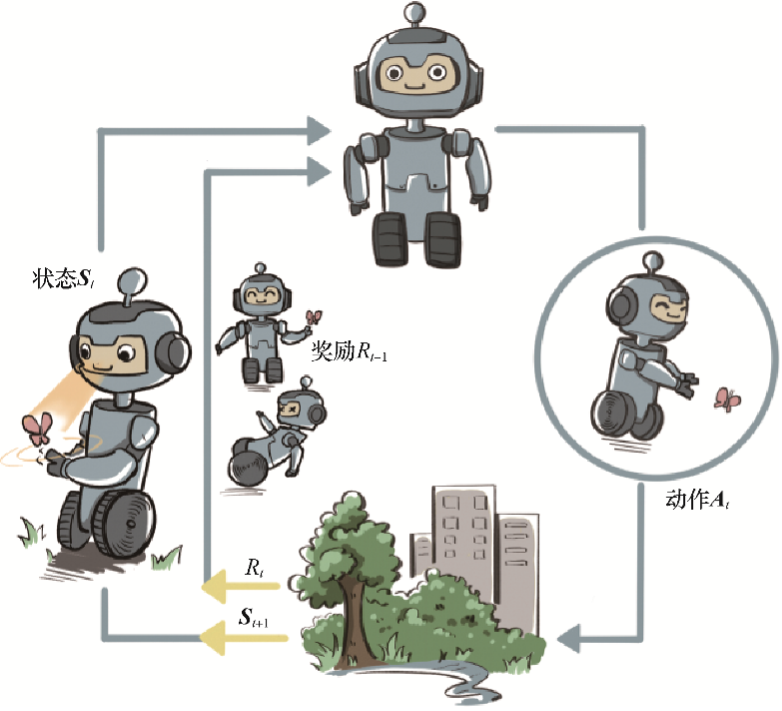
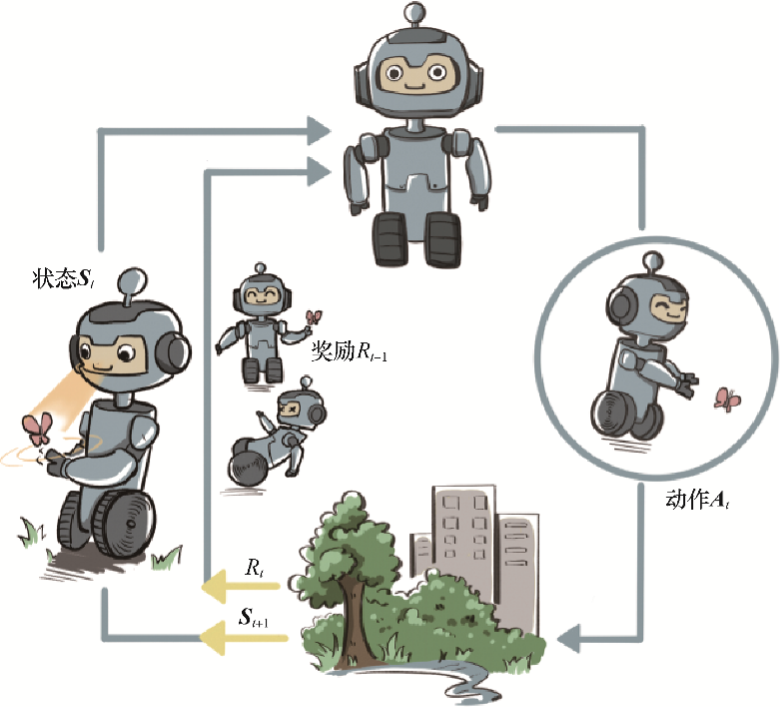
在强化学习(Reinforcement Learning, RL)中,、 和是几个关键概念,它们各自有不同的含义和作用。下面是对这三个概念的详细解释及其区别与联系:定义:作用:示例:定义:作用:示例:定义:作用:示例:层次不同:用途不同:定义方式不同:共同目标:相互依赖:动态关系:、 和在强化学习中扮演着不同的角色,但它们之间又存在紧密的联系,共同推动着强化学习算法的学习过程。
总之,选择 TensorFlow 还是 PyTorch 主要取决于你的具体需求、使用场景和个人偏好。两者都是非常强大的深度学习框架,各自有其优势。TensorFlow 和 PyTorch 是两种流行的深度学习框架,各有优缺点和特定的使用场景。

特点Model-Free依赖环境模型是否学习方法学习环境模型并进行规划直接学习策略或价值函数计算复杂度较高,需要维护和利用环境模型较低,不需要显式的环境模型数据效率较高,通过模型可以进行模拟和规划较低,需要大量的交互数据适用场景环境模型已知或可估计环境复杂或难以建模示例算法动态规划、MCTS、Dyna-Q等Q学习、SARSA、DQN、策略梯度法等Model-based 和 model-free 强
综上所述,深度强化学习调参是一个非常复杂的任务,需要结合具体的任务需求和算法特点来进行调整。通过不断地尝试和实验,结合以上的调参技巧,可以提高模型的性能和训练效果。调整神经网络的结构,包括隐藏层的数量、每层的神经元数量、激活函数的选择等。通常来说,增加网络的深度和宽度有助于提高模型的表现,但也可能增加训练时间和计算成本。不同的环境和任务对算法的表现有着不同的要求,因此需要根据具体情况选择合适的环境

看了文档的评测,tianshou速度快过所有的强化学习库,但是功能上还不够完全,多智能体等算法未实现,可能要考虑转向ray了,ray作为一个分布式框架,就不禁让我想起了spark和mllib令我奔溃的日子。本人因为一些比赛的原因,有使用到强化学习,但是因为过于紧张与没有尝试快速复现强化学习的代码,并没有获得很好的成绩,故尝试用库进行快速复现。上面都是脚本式的运作,将参数定义在args里面相对的方便
强化学习(Reinforcement Learning,简称RL)是机器学习的一个分支,其主要关注如何使智能体(Agent)通过与环境的交互学习,以在面临不同情境时做出最优决策。在强化学习中,智能体通过试错过程,通过观察环境的反馈(奖励或惩罚)来调整其行为,从而最大化累积奖励。1.序贯决策问题: 强化学习适用于需要按照一系列动作来达到某个目标的问题,这些问题通常是序列型的,每个动作的影响可能取决于
在命令运行窗口(重进一次)先进入python所在的盘,(以我的D盘为例),直接输入D:,会看到D:>(1)win+R进入命令运行窗口,输入cmd打开命令提示符,接着输入python即可;格式为pip +install+DD.whl,我的就是。(2)pycharm中可以通过所在的环境进行查看;(cd后面的空格不能省)!将你刚刚存的地址输入进去。

总体而言,卷积层和全连接层在深度学习模型中扮演着不同但相辅相成的角色,卷积层用于提取特征并保留空间信息,而全连接层用于整合和学习这些特征的高级表达。1.卷积核数量: 通常,初始的卷积层使用较少的卷积核,然后随着网络的深度逐渐增加卷积核的数量。对于较小的特征,可以选择小一些的卷积核,而对于更大的特征,可以选择更大的卷积核。2.参数共享: 卷积层通过卷积核在输入数据上滑动来提取特征,同时在整个输入数据

1.2.