




- @qq_43543209
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
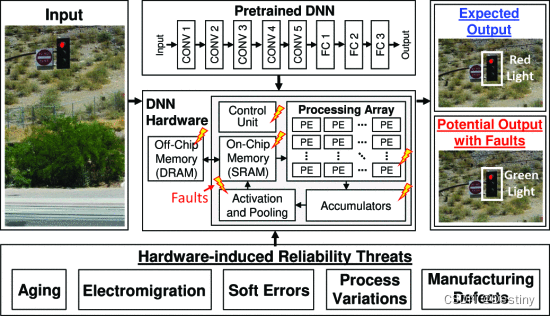
由于激进的技术扩展,现代系统越来越容易受到可靠性威胁的影响,例如软错误、老化和工艺变化。这些威胁在硬件级别表现为位翻转,并且根据位置,可能会损坏输出,从而导致不准确或潜在的灾难性结果。传统的缓解技术基于冗余,例如双模块化冗余 (DMR) [16] 和三重模块化冗余 (TMR) [17]。然而,由于 DNN 的计算密集型性质,这些技术会导致巨大的开销,对系统的效率产生负面影响。纠错码 (ECC) 和
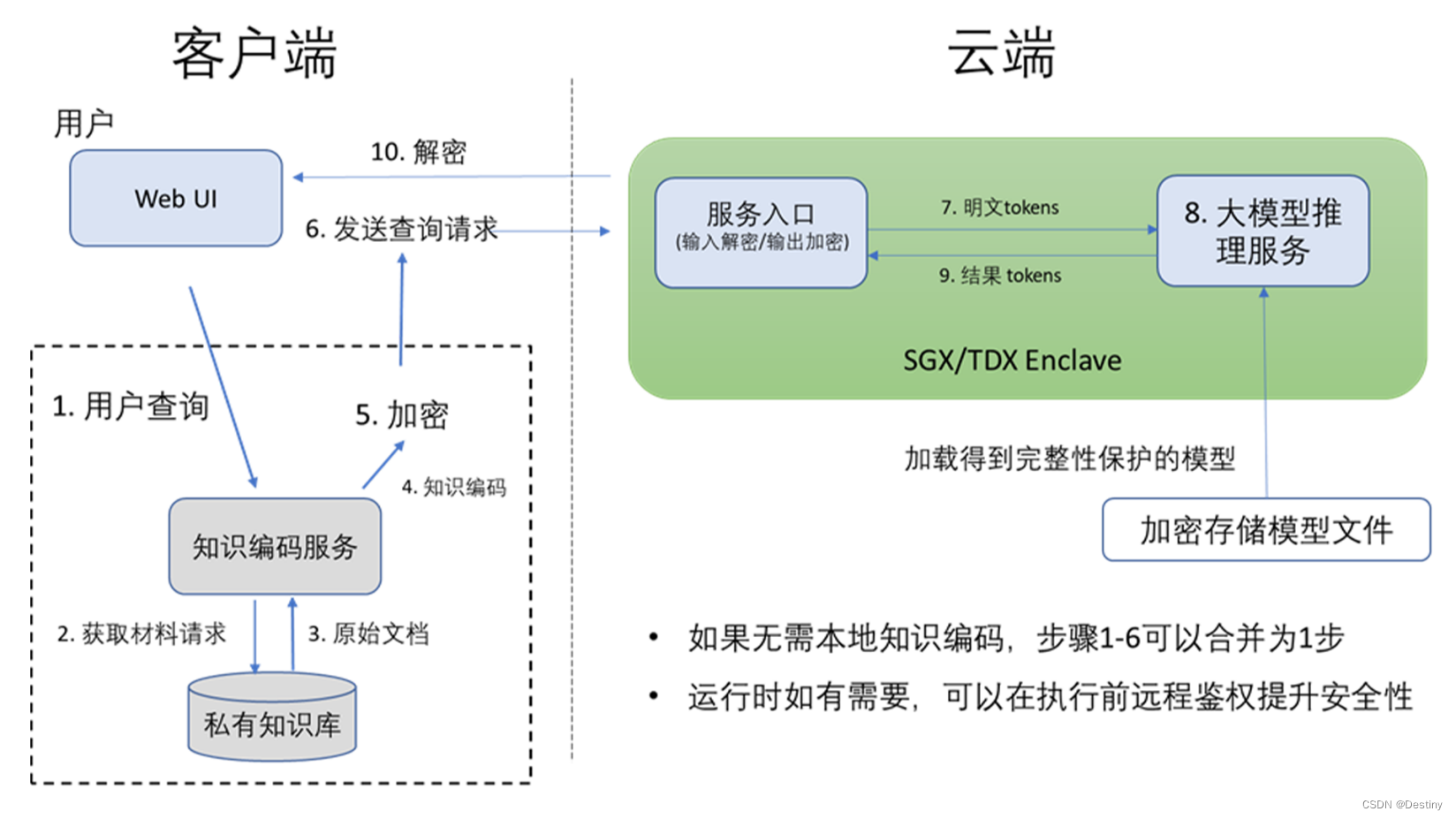
当交换完成时,GPU 驱动程序和 SEC2 都持有相同的对称会话密钥。在大模型公有云服务方面,以百度、阿里等为代表的互联网与云服务公司,从大模型全生命周期视角出发,涵盖大模型训练、精调、推理、大模型部署、大模型运营等关键阶段面临的安全风险与业务挑战,在自有技术体系内进行深入布局,探索打造安全产品与服务。360等第三方独立的人工智能与安全科技公司,探索“以模型管理模型”方式,打造以大模型为核心的AI
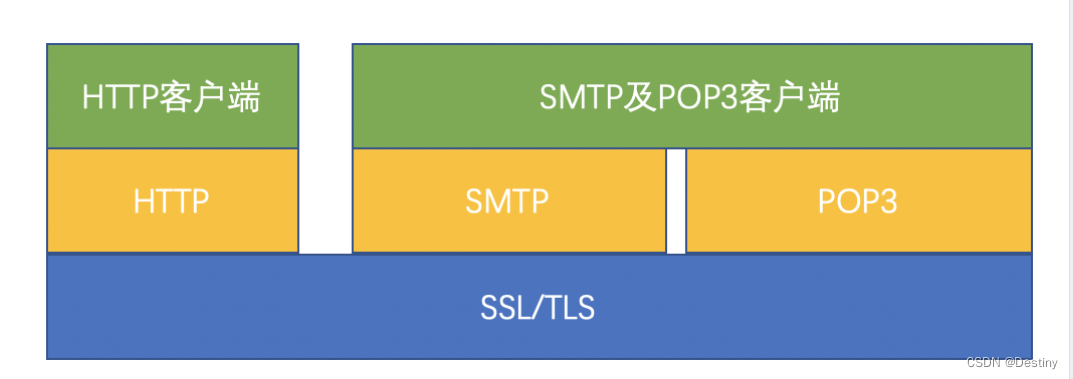
IPSec(Internet Protocol Security)是一种网络层安全协议,用于在IP通讯过程中确保完整性、认证性和机密性。它通过在标准的IP协议上加入安全机制来实现加密和认证。IPSec主要由两个协议组成:认证头(AH)和封装安全载荷(ESP)。它们可以单独使用或同时使用,来提供数据的不同级别的保护。IPSec广泛应用于虚拟私人网络(VPN)中,保护跨不安全的公共网络传输的数据。

传输层安全性(Transport Layer Security,TLS)是一种广泛采用的安全性协议,旨在促进互联网通信的私密性和数据安全性。TLS 的主要用例是对 web 应用程序和服务器之间的通信(例如,web 浏览器加载网站)进行加密。TLS 由互联网工程任务组(Internet Engineering Task Force, IETF)提出,协议的第一个版本于 1999 年发布。最新版本是
在之前的 SM 概览图以及上图里,可以注意到 SM 内有两个 Warp Scheduler 和两个 Dispatch Unit. 这意味着,同一时刻,会并发运行两个 warp,每个 warp 会被分发到一个 Cuda Core Group(16 个 CUDA Core), 或者 16 个 load/store 单元,或者 4 个 SFU 上去真正执行,且每次分发只执行 一条 指令,而 Warp S

由于激进的技术扩展,现代系统越来越容易受到可靠性威胁的影响,例如软错误、老化和工艺变化。这些威胁在硬件级别表现为位翻转,并且根据位置,可能会损坏输出,从而导致不准确或潜在的灾难性结果。传统的缓解技术基于冗余,例如双模块化冗余 (DMR) [16] 和三重模块化冗余 (TMR) [17]。然而,由于 DNN 的计算密集型性质,这些技术会导致巨大的开销,对系统的效率产生负面影响。纠错码 (ECC) 和
主要关注点在于安全应用程序领域,深入研究利用 LLM 发起网络攻击。

由于激进的技术扩展,现代系统越来越容易受到可靠性威胁的影响,例如软错误、老化和工艺变化。这些威胁在硬件级别表现为位翻转,并且根据位置,可能会损坏输出,从而导致不准确或潜在的灾难性结果。传统的缓解技术基于冗余,例如双模块化冗余 (DMR) [16] 和三重模块化冗余 (TMR) [17]。然而,由于 DNN 的计算密集型性质,这些技术会导致巨大的开销,对系统的效率产生负面影响。纠错码 (ECC) 和
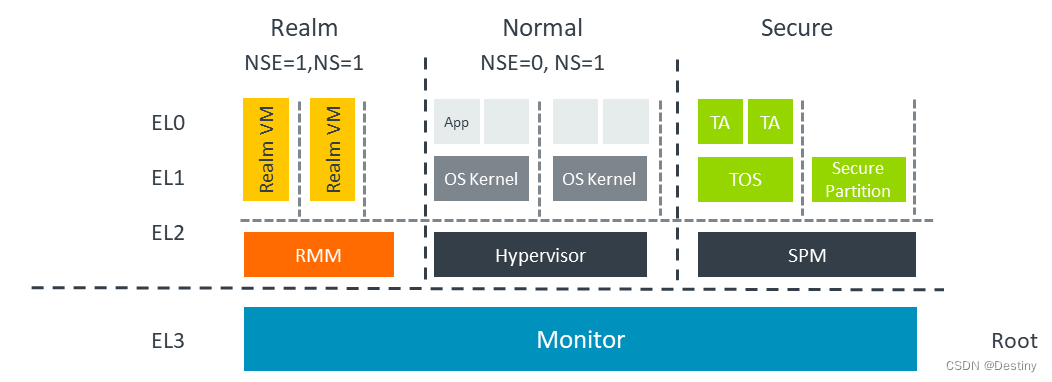
Hign Level设计安全威胁模型用法内存安全问题在本指南中,我们将探讨机密计算在现代计算平台中的作用,并解释机密计算的原理。然后,我们将介绍 Arm 机密计算架构 (Arm CCA) 如何在 Arm 计算平台中实现机密计算。定义机密计算描述一个复杂的系统信任链了解 Realm 是由 Arm CCA 引入的受保护的执行环境解释如何在 Arm CCA 的实现上创建、管理和执行 Realm定义可信执
主要关注点在于安全应用程序领域,深入研究利用 LLM 发起网络攻击。