




- @qq_43158059
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
尽管每一个机器学习的算法都有它的缺点和优点,但是不可否认的是系统性能的差异往往由于数据准备的方式或者表现形式的不同。我相信你知道范数表示的是一个向量的长度,且可以使用不同的方法来定义。缩放是将所有的特征(可能有不同的物理单位)变成特定范围内的值的一个过程。特征分解就是把数据压缩成由少量的但具有更多的信息的数据成分组合的数据的过程。比如机器学习常用的是矩阵数组的格式,传入的通常是列表的,元组的。特征
Olivetti人脸数据集是1900年由ATT剑桥实验室收集。这个数据集包含40个不同受试者在不同时间、不同光照情况下的面部图像。此外,受试者也有不同的面部表情和面部细节。接下来图像被量化到256的灰度值。一共40个不同的标签。人脸识别是一个多类分类的任务。掉包,scikitlearn中数据分割数据集,cv2随机深林。和深度数目rtree.setmaxdepth(1000)是不可少的参数。
Cython 简明指南摘要 Cython 是 Python 的扩展语言,能够将 Python 代码编译为高效的 C 代码。本文档介绍了 Cython 的核心特性: 基础概念:Cython 结合 Python 易用性和 C 语言性能,适用于计算密集型任务、数值计算和 C 库调用。 安装与使用:可通过 pip/conda 安装,支持 .pyx 源文件和 .pxd 头文件。 关键特性: 静态类型声明(c
python语言环境中list类型的坐标范围和大小与 数组类型的坐标Numpy的区别。
1背景神经网络具有预测,拟合,分类的作用2项目目标通过原始数据集性别,体重与体重的对应,实验神经网络的训练。并最终完成输入体重和身高的数据,预测性别。3数据集4算法结构模型采用bp算法。建立一个bp网络,拥有输入层,隐含层,输出层。网络的抽象图如下所示。含有中间两个权值矩阵w1,w2.5 程序这个matlab程序5.1优点 1归一化数据时候使用均值平移,在使用标准差让数据在[-1,1]之间,相较
基于神经网络的空气质量指数预测1 项目背景1背景空气质量对我们日常生活出行、身体健康有重要影响。因此实现空气质量的预测具有重要意义,并且通过神经网络的方法将能够优化传统统计学的方法。2目标通过matlab编程,实现数据库的建立、数据处理、神经网络建立、网络训练,最终实现预测未来第四小时的6种污染物浓度数值。本文下例以预测co的 污染物浓度为例。2 项目方法1 数据相关性分析网络获取到的污染物浓度数
该数据集是由 5 个健康人和 5 个癫痫患者的脑电数据构成的,共包含有 5 个数据子集,分别是 F、S、N、Z、O。数据描述如表 2。波恩数据集为单通道数据集,其中每个子数据集都包含100个数据片段,每个数据片段的时间长度为23.6秒,数据点为 4097个。信号的分辨率为12位,采样频率为173.61Hz。 每一个子集包含100个长度为23.6秒,采样频率173.61Hz的单通道EEG。这些
Olivetti人脸数据集是1900年由ATT剑桥实验室收集。这个数据集包含40个不同受试者在不同时间、不同光照情况下的面部图像。此外,受试者也有不同的面部表情和面部细节。接下来图像被量化到256的灰度值。一共40个不同的标签。人脸识别是一个多类分类的任务。掉包,scikitlearn中数据分割数据集,cv2随机深林。和深度数目rtree.setmaxdepth(1000)是不可少的参数。
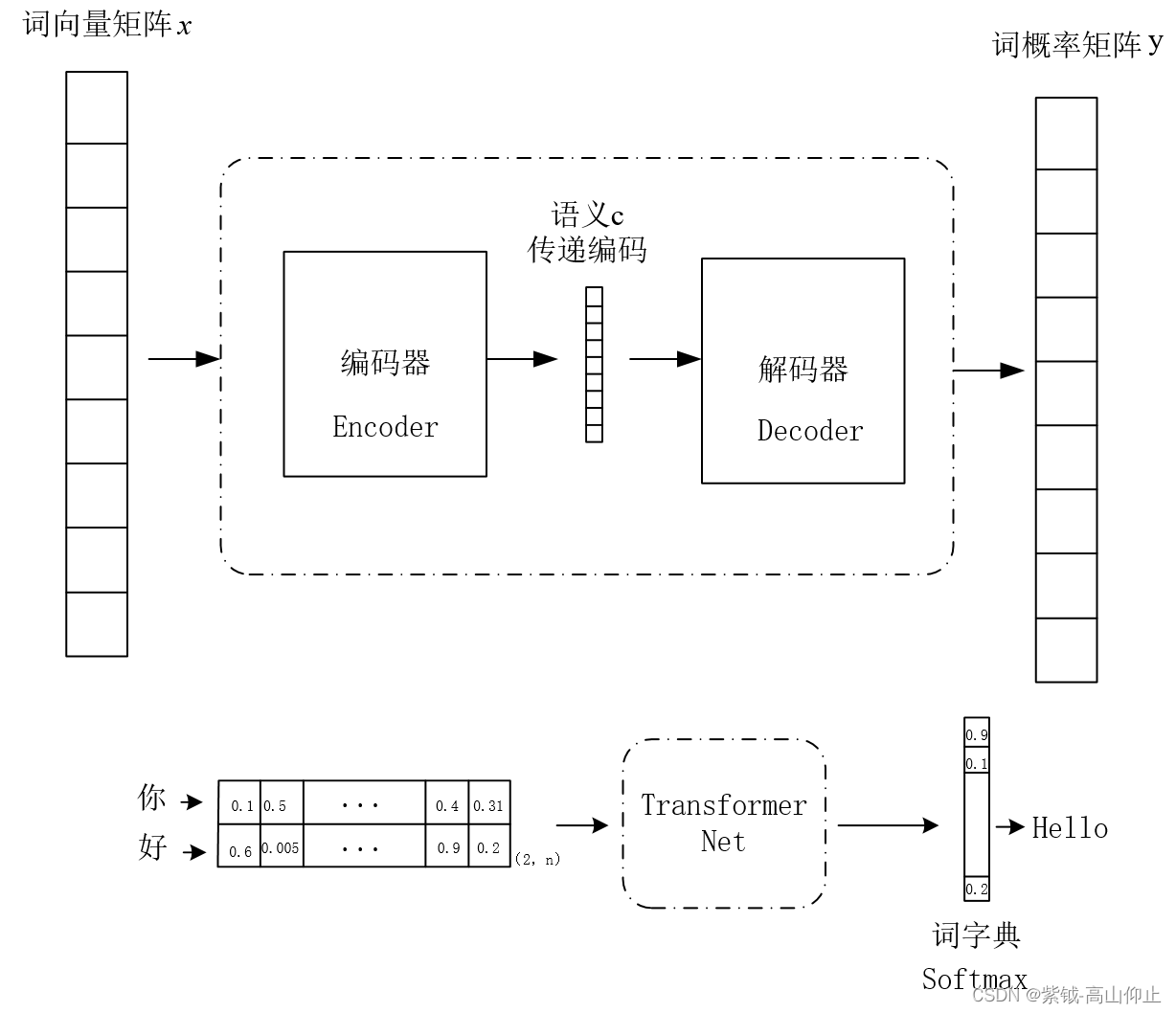
在自然语言处理领域,chat-GPT为这几年最让人感觉到强大的自然语言模型。GPT基于Transformer,Transformer又是基于attention机制。这次咱们从Encoder-Decoder->Attention->Transformer逐步讲解,一步一步深入。Encoder-Decoder框架顾名思义也就是编码-解码框架,目前大部分attention模型都是依附于Encoder-D
Olivetti人脸数据集是1900年由ATT剑桥实验室收集。这个数据集包含40个不同受试者在不同时间、不同光照情况下的面部图像。此外,受试者也有不同的面部表情和面部细节。接下来图像被量化到256的灰度值。一共40个不同的标签。人脸识别是一个多类分类的任务。掉包,scikitlearn中数据分割数据集,cv2随机深林。和深度数目rtree.setmaxdepth(1000)是不可少的参数。