




- @qq_43127132
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
浅谈大语言模型输出随机性参数temperature

我们根据性能问题的场景,按照单机和集群场景进行分类,再明确性能问题属于哪一类,明确好性能问题背景之后,才方便进行下一步问题的定位;在明确问题背景后,参考,选择对应的性能工具,采集性能数据并拆解性能,找到需要提升性能的模块;在明确性能瓶颈模块后,将问题细化定位到下发、计算和通信等模块,并通过本文目录搜索到对应章节找到对应优化算法。

通俗理解什么是RLHF

通俗理解什么是RLHF
5、重启系统,测试。
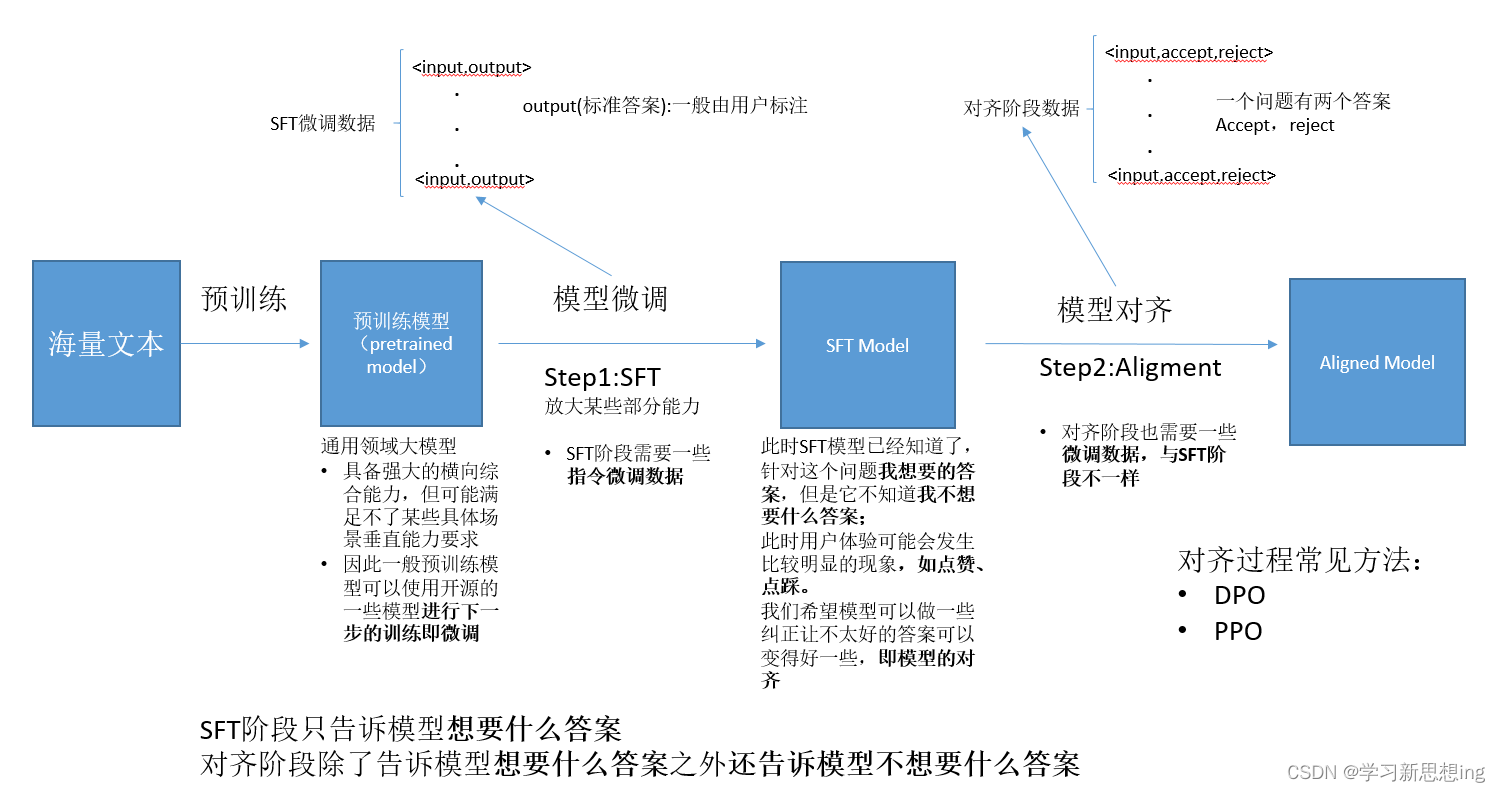
但是通用大模型在某些方面的垂直能力可能还不具备,因此需要用到一些领域的数据或私有化数据对大模型进行改良,这个过程叫做微调。通过海量数据数据,训练一个通用大模型,此时大模型具备很多能力。简单理解大模型预训练和微调的过程。
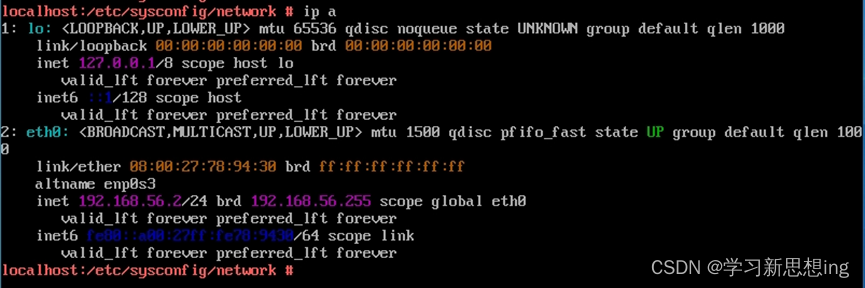
liunx系统基于CUDA生态从0开始构建大模型训练环境;ubuntu+CUDA+pytorch+ChatGLM
这些大型预训练模型通常是在大量无标注或弱标注的数据上通过自监督学习(self-supervised learning)的方式预先训练得到的,目的是捕获语言或数据中的通用表示(representations)。此外,预训练模型还允许研究人员和开发者利用有限的标注数据来训练模型,降低了对大规模标注数据的依赖。这些任务通常需要利用预训练模型学到的通用表示,通过微调(fine-tuning)或特征提取(f

我们根据性能问题的场景,按照单机和集群场景进行分类,再明确性能问题属于哪一类,明确好性能问题背景之后,才方便进行下一步问题的定位;在明确问题背景后,参考,选择对应的性能工具,采集性能数据并拆解性能,找到需要提升性能的模块;在明确性能瓶颈模块后,将问题细化定位到下发、计算和通信等模块,并通过本文目录搜索到对应章节找到对应优化算法。
这些大型预训练模型通常是在大量无标注或弱标注的数据上通过自监督学习(self-supervised learning)的方式预先训练得到的,目的是捕获语言或数据中的通用表示(representations)。此外,预训练模型还允许研究人员和开发者利用有限的标注数据来训练模型,降低了对大规模标注数据的依赖。这些任务通常需要利用预训练模型学到的通用表示,通过微调(fine-tuning)或特征提取(f