




- @qq_42681787
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了一个包含1289张罂粟检测图像的YOLO格式数据集。数据集包含jpg图像和对应的txt标注文件,标注类别为"poppy",共2022个标注框。图像分辨率为640x640,使用labelImg工具标注,未进行数据增强。数据集已划分为1088张训练集和201张验证集。经YOLOv8n模型验证,mAP50达到80.6%。数据集下载地址已提供,但声明不保证模型改进后的性能提升。

本篇文章介绍yolo目标检测数据集的一般格式,及如何借助labelimg标注软件对图片进行标注。最后对数据集进行划分,并将数据集组织为ultralytics框架可用的目录结构,使数据集能够利用ultralytics框架对yolo3、yolo5、yolo8、yolo9、yolo10等进行训练。

本文介绍GPU下YOLO8目标跟踪任务环境配置、也即GPU下YOLO8目标检测任务环境配置。

摘要: 本文介绍了基于YOLOv8的打架斗殴行为检测系统,针对公共场所暴力事件频发问题,提出智能化解决方案。YOLOv8优化了骨干网络、Neck结构和检测头设计,采用Anchor-Free范式,显著提升检测精度与速度。系统使用2291张标注图像训练,实测mAP@50达86.3%,支持实时预警。通过数据增强和超参数调优,模型在复杂场景下表现稳定。该系统可降低人工监控成本,为智慧安防提供关键技术支撑,

Ultralytics正在以惊人的速度吸收优秀的CV算法,之前Ultralytics定位于YOLO8,但逐渐地扩展到支持其他版本的YOLO,最新版本的ultralytics全面支持yolo5yolo7yolo8yolo9yolo10yolo11。本文介绍如何用Ultralytics训练自己的yolo5yolo8yolo9yolo10yolo11模型,我们开门见山,直接步入正题。

YOLOv8是由Ultralytics团队在2023年推出的最新一代YOLO目标检测网络,延续了YOLO系列在实时性与精度之间追求极致平衡的设计理念,在工业界和学术界均获得了广泛关注。其骨干网络(Backbone)经历了从CSPDarknet到C2f结构的重大演进,核心思想源于ELAN(Efficient Layer Aggregation Network)——通过跨层连接将不同阶段的特征图进行高

本文介绍了一种基于YOLOv8的苹果叶片病虫害智能检测系统。该系统针对苹果种植中的常见病害(如褐纹病、褐斑病等)和虫害,采用YOLOv8目标检测算法进行高效识别。系统使用包含946张标注图像的真实果园数据集,通过改进的C2f骨干网络、PAN-FPN特征融合和解耦检测头等技术,在检测精度和速度上较前代YOLO模型有显著提升。结合Streamlit框架构建的交互式Web应用,该系统实现了图像上传、实时

该系统主要包含以下功能:(1)可以对罂粟植株进行识别(2)支持通过前端页面对模型识别参数进行调整。(3)系统支持图片识别、视频识别和摄像头识别。系统功能效果演示视频如下:罂粟识别 基于yolo8的罂粟非法种植识别在这里插入图片描述YOLOv8由Ultralytics团队于2023年推出,与其前代YOLOv5(同为该团队2020年发布的作品)一脉相承,整体结构较为接近。确切地说,YOLOv8是在YO

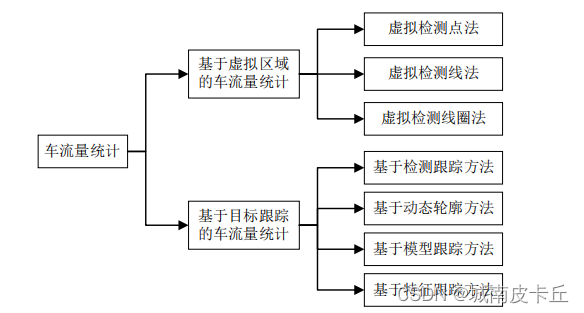
基于车辆跟踪的车流量统计方法通过对车流视频中的各帧图像中的车辆进行匹配,从而捕捉各个车辆的运动轨迹和状态,并基于车辆轨迹和状态的差异性进行车辆计数。(2)车辆跟踪阶段。方案非常明晰,实现起来也并不难,但是目前基于yolo+多目标跟踪算法存在的问题是:传统的基于yolo的跟踪计数都是把虚拟检测区域写固定,把视频文件路径写固定,换一个视频画面基本就不能检测了,因此我们新增GUI文件选择界面让系统支持用
该跌倒行为检测数据集采用YOLO格式,包含6547张jpg图片及对应txt标注文件。数据集包含2个类别:"standperson"(站立)和"falldown"(跌倒),总标注框数24468个。图片为多分辨率原图,未进行数据增强。数据集已划分为训练集(6395张)和验证集(152张),未设测试集。经YOLOv8s模型验证,所有类别mAP50达82.3%。该数
