




- @qq_42166929
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
Deployment failed: repository element was not specified in the POM inside…(已解决)都搜到这里了你可以不用看其他文章了出现这个原因无非是想在本地的pom文件配置好之后,执行deploy命令,可以将maven所打的jar包上传到远程的repository,便于其他开发者和工程共享。但是!!!!!!你自己本地都没有!!!dist
机器学习实战预测婴儿出生率1.加载数据2.数据的探索:特征相关性3.统计校验4.创建最后的待训练数据集5.划分训练集和测试集6.开始建模7.Logistic 回归模型8.选取出最具代表性的分类特征9.随机森林模型机器学习是通过算法对训练数据构建出模型并对模型进行评估,评估的性能如果达到要求就拿这个模型来测试其他的数据,如果达不到要求就要调整算法来重新建立模型,再次进行评估,如此循环往复,最终获得满
第一章:数据清洗常用工具1.numpy常用数据结构常用清洗工具:numpy常用数据结构:Numpy常用方法数组访问方法练习(jupyter)代码下面是结果2.Numpy常用数据清洗函数数据的排序数据的搜索练习(jupyter)代码下面是结果3.Pandas常用数据结构series和dataframeseriesdataframe常用方法练习(jupyter)代码下面是结果1.numpy常用数据结构
数据清洗之数据转换日期数据格式处理练习字符串数据处理练习高阶函数数据处理练习数据集地址:https://pan.baidu.com/s/1kMH1AhE8RUyaT73rvJsVPQ提取码:aai6日期数据格式处理练习import numpy as npimport pandas as pdimport osos.chdir(r'G:\pythonProject\pc\Python数据清洗\dat
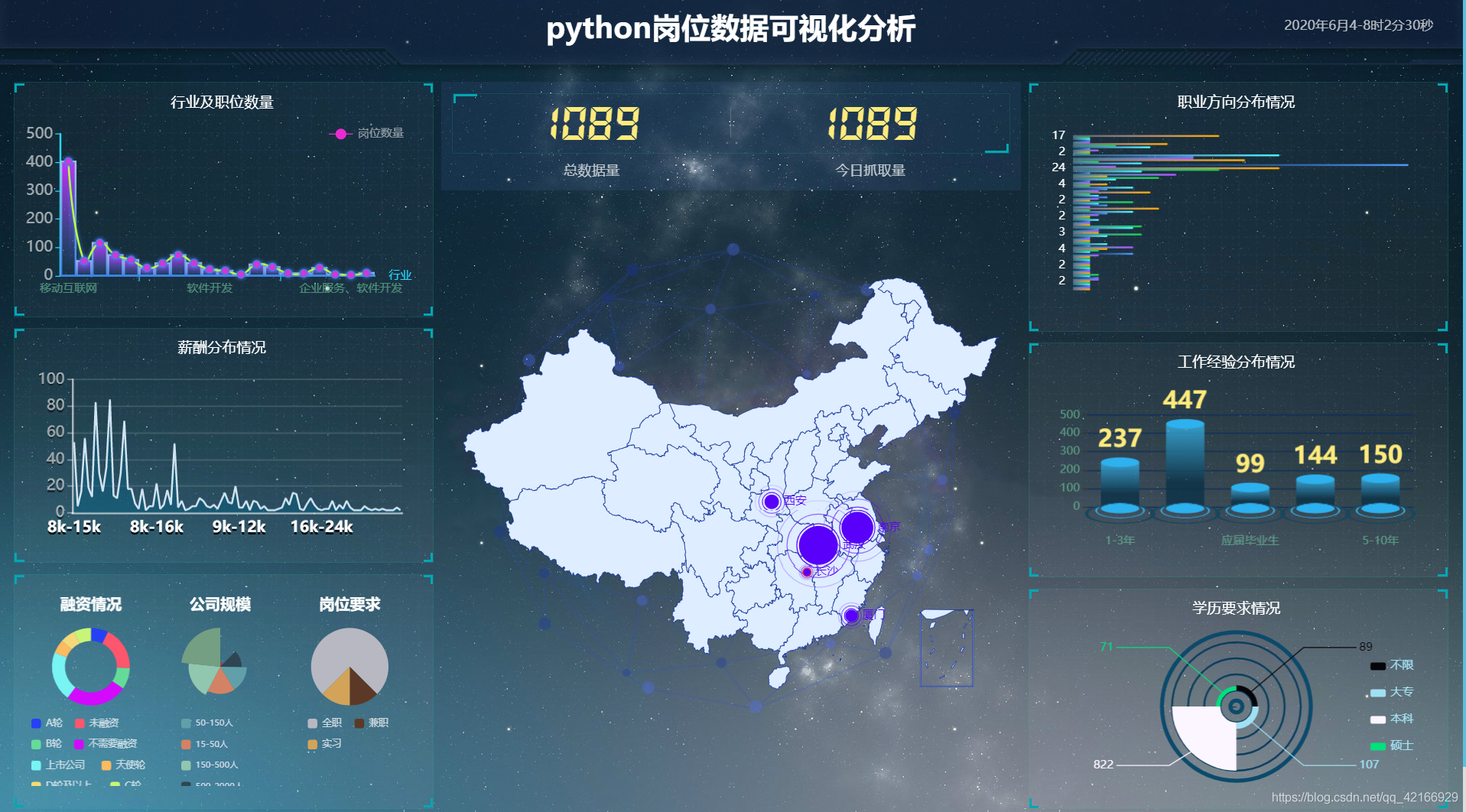
python招聘信息与岗位分析数据可视化第一部分(数据获取)1.数据库表创建2.数据爬取入库3.数据存储与查询第二部分(前端展示)第三部分(flask web应用)首先查看目录树第一部分(数据获取)1.数据库表创建首先通过python的sqlalchemy模块,来新建一个表。creat_lagou_tables.pyfrom sqlalchemy import create_engine, Int
数据分析师招聘数据清洗实战数据导入并查看重复数据处理异常值处理缺失值处理数据是数据分析师的招聘薪资,主要内容是进行数据读取,数据概述,数据清洗和整理数据获取:链接:https://pan.baidu.com/s/1sSmyiUfkDtVHuJEQP56h3w提取码:okic数据导入并查看首先载入的数据在pandas中,常用的载入函数是read_csv。除此之外还有read_excel和read_t
直方图与模板匹配直方图mask操作直方图均衡化自适应直方图均衡化模板匹配匹配多个对象import cv2 #opencv读取的格式是BGRimport numpy as npimport matplotlib.pyplot as plt#Matplotlib是RGB%matplotlib inlinedef cv_show(img,name):cv2.imshow(name,img)cv2.wai