- @qq_41596730
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
问题引入在深度学习中,一个好的数据集必不可少。在使用tensorflow进行图像分类任务中,往往不少同学都是直接从硬盘直接加载图片,在内存进行预处理等工作后,直接输入给网络进行训练。如果你的数据集比较小,这种方式对你的内存不会造成太大的负担,代码跑起来速度还可以,可是当你的数据集特别大的时候,再从硬盘加载图片到内存进行训练,就显得特别吃力了。这个时候我们就需要用到tensorflow建议使用的统.
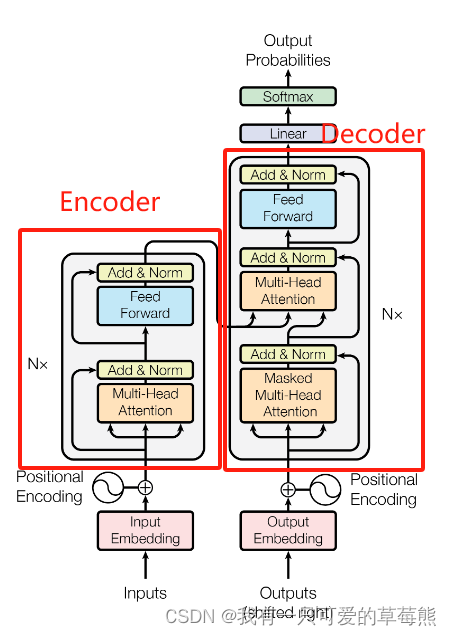
上面我们首先介绍了llm的几种架构,从宏观层面分析了LLM的推理过程,并对其中的一些数据流做了简单的分析,接下来我们要从工程方面分析大模型如何进行推理以及推理过程中的一些指标。
1.问题引入在数据分析,机器学习,深度学习中,我们经常会处理各种各样格式的数据。今天,博主在做房价预测时(采用波士顿房价数据集),从网上下载的数据集格式为.data,并不是我们喜闻乐见的csv格式,所以想采用pandas库将其转为为csv格式的数据,方便后面的训练。2.问题分析data格式数据展示为:从第1列到第14列数据属性为:代码演示import pandas as pd#读取d...
上面我们首先介绍了llm的几种架构,从宏观层面分析了LLM的推理过程,并对其中的一些数据流做了简单的分析,接下来我们要从工程方面分析大模型如何进行推理以及推理过程中的一些指标。
SVM,线性可分支持向量机,
anaconda创建虚拟环境安装opencv
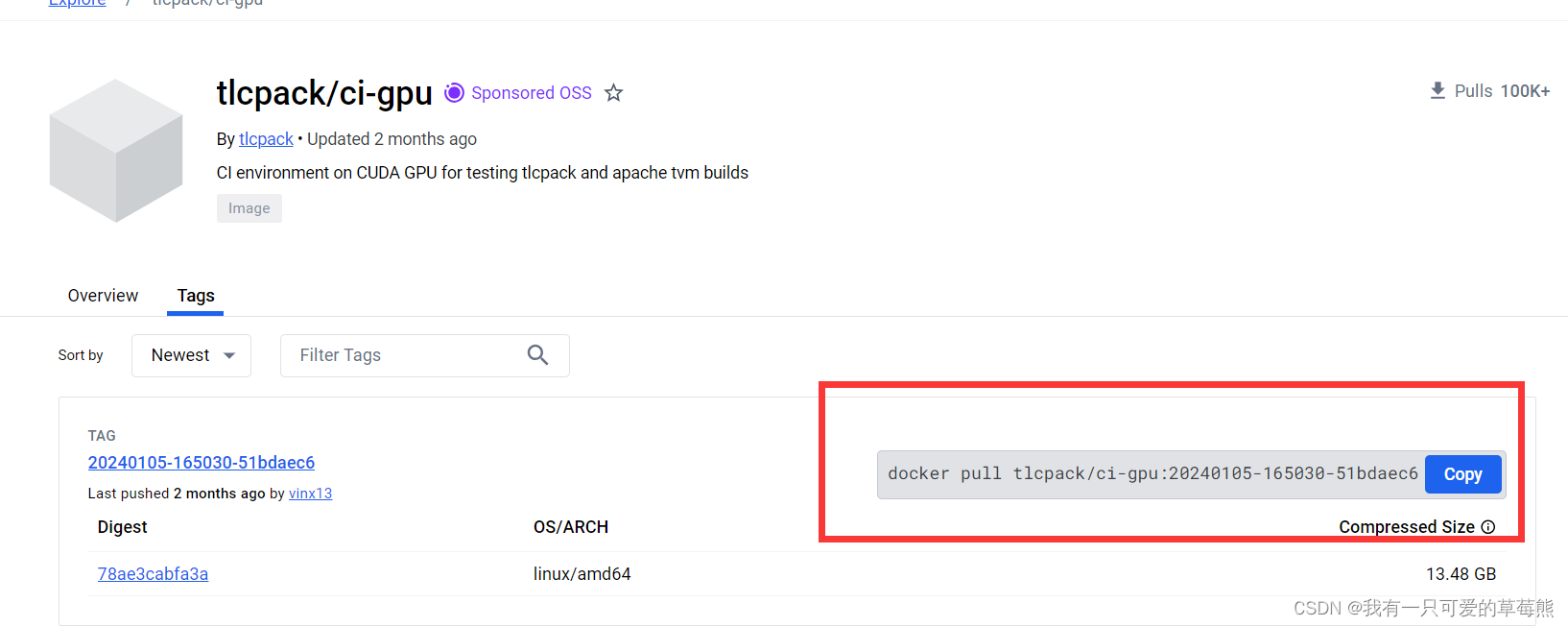
之前从源码安装过一次TVM,但是要配置cmake,安装llvm等,太过于繁琐,所以这一次准备在Docker镜像里安装TVM,做以记录。
vscode升级到最新的1.86版本后,无法远程连接服务器Remote SSH,在log中提示如下:glibc的版本好像不符合vscode1.86版本的要求。你可以在你的服务器上运行下面的指令查看glibc经过查阅,博主的版本是2.27,不符合要求。