




- @qq_40773212
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文主要介绍 I2S、PCM、TDM 、PDM四个接口的区别。这四个全是物理接口,有着不同的物理连接方式。

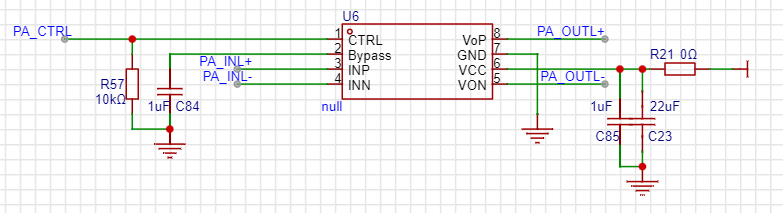
在设计功放电路时,直接copy了别人的电路,却将喇叭由原来的8Ω1W替换为了4Ω3W。测试时,毫无意外声音没有出来,下面一步步查找原因。电源端加适当的去耦电容可以确保器件的高效率及最佳的 THD+N 性能(Total Harmonic Distortion(THD)是衡量信号失真程度的核心指标,定义为基波信号以外的谐波成分总有效值与基波有效值的百分比。),同时为得到良好的高频瞬态性能,希望电容的
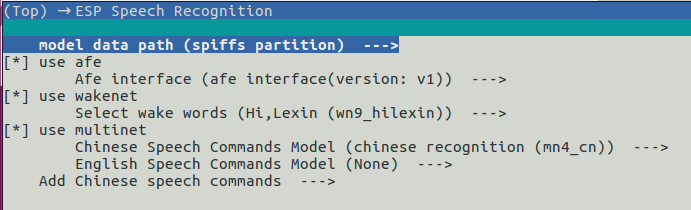
乐鑫提供了经过训练的 WakeNet 和 MultiNet 模型,使用模型前需先将其加载至你的项目,目前 ESP-SR 支持以下模型加载方式:配置方法:运行 idf.py menuconfig 进入 ESP Speech RecognitionAFE声学前端算法 + 使用模型乐鑫 AI 自主研发了一套乐鑫 AFE 算法框架,可基于ESP32-S3 系列芯片进行声学前端处理。
https://azure.microsoft.com/zh-cn/free/选择免费试用创建资源

这里我的CUDA driver version是12.2,CUDA runtime version是11.7 ,Pytorch2.0.1。按理说大模型应该与我这种只有一张入门级显卡的穷X没什么交集才对,就只能调用调用API,但是某一天让我发现了这个图。啊~6G显存,RTX2050有专用的4G显存+2G共享显存,哦?用Pycharm打开文件夹,添加Python解析器,我这里用的python虚拟环境,

下面是一段火山引擎对大模型语音生成的说明。(注意合成 与 生成)传统的语音合成方法只局限在把对应的文本内容合成出来,对于语音的自然度、富文本以及多情感的关注其实比较少。而语音生成大模型在输入和输出方面表现都要更丰富。主要包含三个模块:(1)从富文本、参考语音等输入中去生成语音token这样一个自回归的transformer模型(2)从语音token重构出语音特征的常微分扩散模型Flow Match

下面是一段火山引擎对大模型语音生成的说明。(注意合成 与 生成)传统的语音合成方法只局限在把对应的文本内容合成出来,对于语音的自然度、富文本以及多情感的关注其实比较少。而语音生成大模型在输入和输出方面表现都要更丰富。主要包含三个模块:(1)从富文本、参考语音等输入中去生成语音token这样一个自回归的transformer模型(2)从语音token重构出语音特征的常微分扩散模型Flow Match
主要参考资料:还没搞懂嵌入(Embedding)、微调(Fine-tuning)和提示工程(Prompt Engineering)?B站Up主Nenly同学《60分钟速通LORA训练!
早期的音频采集、处理和传输技术,主要依赖于 Websocket 这种通信方式。但这在实际使用中,有时会遇到一些问题,比如在网络环境复杂的情况下,可能会导致对话出现卡顿,或者在传输过程中丢失一些关键信息,这可能会造成对话内容的误解。另外,探索基于多模态大模型的智能场景感知和识别类应用场景,Websocket 也无法承接视频传输的扩展能力。而豆包大模型,如今已经向 ChatGPT 对齐,传输已经采用了

Python版本要求• 推荐Python 3.10+(最低3.8)• 验证环境:python --version# 创建虚拟环境# 安装核心库验证安装:mcp version 应返回1.5.0+版本。