




- @qq_40509664
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
核心思想:把“看见”“理解语言”“生成动作”统一到一个大模型中。视觉模块 → 单独规划器 → 单独控制器图像 + 指令 → 大模型 → 直接输出动作代表性工作包括:Google DeepMind 的 RT-2;Physical Intelligence 的 π0。把机器人控制“语言化、token化”。
核心思想:把“看见”“理解语言”“生成动作”统一到一个大模型中。视觉模块 → 单独规划器 → 单独控制器图像 + 指令 → 大模型 → 直接输出动作代表性工作包括:Google DeepMind 的 RT-2;Physical Intelligence 的 π0。把机器人控制“语言化、token化”。
这16个卷积核分别是下图中的3,4,6通道的卷积核,输出图像的大小为10*10*16.训练的参数有6*[5*5*3+1]+9*[5*5*4+1]+1*[5*5*6+1]=1516;第二层S2:池化层2*2步长2,下采样,输入28*28*6输出为14*14*6;14*14*6*(2*2+1)=5880个连接。第四层S4:同S2操作,池化层2*2步长2,输入为10*10*16,输出为(10-2+2)/

以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别”本质即在图像上预设好的不同大小,不同长宽比的参照框。输入图片输出为目标类别和目标的边界框——(c,x,y,w,h)5维的向量,c为有无目标的置信度。个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆 ×

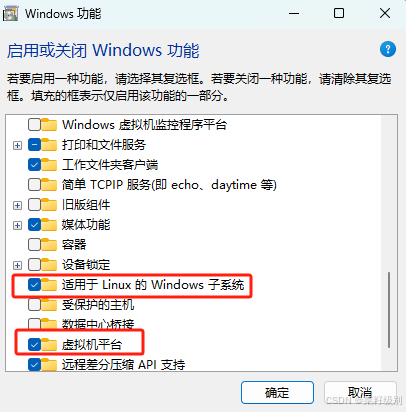
选conda虚拟环境,找到condabin下的conda可执行文件(地址在cmd命令下which conda得到)2.远程连接站点,端口,用户名,密码输入(连接后,后续就不用输入直接选择exist下的即可)ssh -p (端口号位置) (用户名位置)@(接入网址),按照下图位置填写即可。输入which conda 命令查看conda所在位置,记住一会要用。ssh -p (端口号位置) (用户名位置

检查安装是否成功: cat /usr/local/cuda-12.1/include/cudnn_version.h | grep CUDNN_MAJOR -A 2。之后进入lib文件:cd cudnn-linux-x86_64-8.9.4.25_cuda12-archive/4.输入wsl.exe --install Ubuntu-22.04(上面的可安装版,打开powershell,输入wsl
以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别”本质即在图像上预设好的不同大小,不同长宽比的参照框。输入图片输出为目标类别和目标的边界框——(c,x,y,w,h)5维的向量,c为有无目标的置信度。个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆 ×
这16个卷积核分别是下图中的3,4,6通道的卷积核,输出图像的大小为10*10*16.训练的参数有6*[5*5*3+1]+9*[5*5*4+1]+1*[5*5*6+1]=1516;第二层S2:池化层2*2步长2,下采样,输入28*28*6输出为14*14*6;14*14*6*(2*2+1)=5880个连接。第四层S4:同S2操作,池化层2*2步长2,输入为10*10*16,输出为(10-2+2)/
来自Kimi的回答
以往的模型一个窗口只能预测一个目标,把窗口输入到分类网络中,最终得到一个预测概率,这个概率偏向哪个类别则把窗口内的目标预测为相应的类别”本质即在图像上预设好的不同大小,不同长宽比的参照框。输入图片输出为目标类别和目标的边界框——(c,x,y,w,h)5维的向量,c为有无目标的置信度。个框,每个框的bb个数为𝐵,分类器可以识别出𝐶种不同的物体,那么所有整个ground truth的长度为𝑆 ×