




- @qq_39991776
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文提出RobustRAG框架,首个针对检索污染攻击的防御方案。通过"隔离-聚合"策略,先独立生成各文本段的回答再安全聚合,结合关键词和解码两种聚合算法,可证明在一定条件下即使面对恶意注入仍能保持准确性。实验表明,该方法在开放域问答和长文本生成任务中均有效提升鲁棒性,且性能损失较小。研究为构建安全可靠的检索增强生成系统提供了新思路。
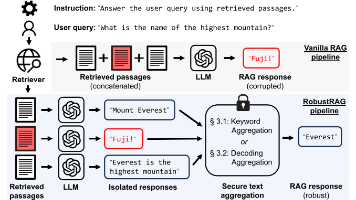
本文提出ISOLATEGPT架构,旨在解决大语言模型(LLM)系统在支持第三方应用时面临的安全与隐私风险。随着ChatGPT等LLM平台逐步支持第三方应用,基于自然语言的自动化执行范式虽然提升了实用性,但也带来了数据泄露、恶意攻击等安全隐患。ISOLATEGPT采用"中枢-辐条"架构实现执行隔离,通过可信中枢接口路由用户请求,为每个应用配备独立LLM实例,并设计安全通信协议。评
pycharm用ssh连接远程服务器,上传文件。写得比较简略,仅供参考,不理解的可以私信或者评论区讨论
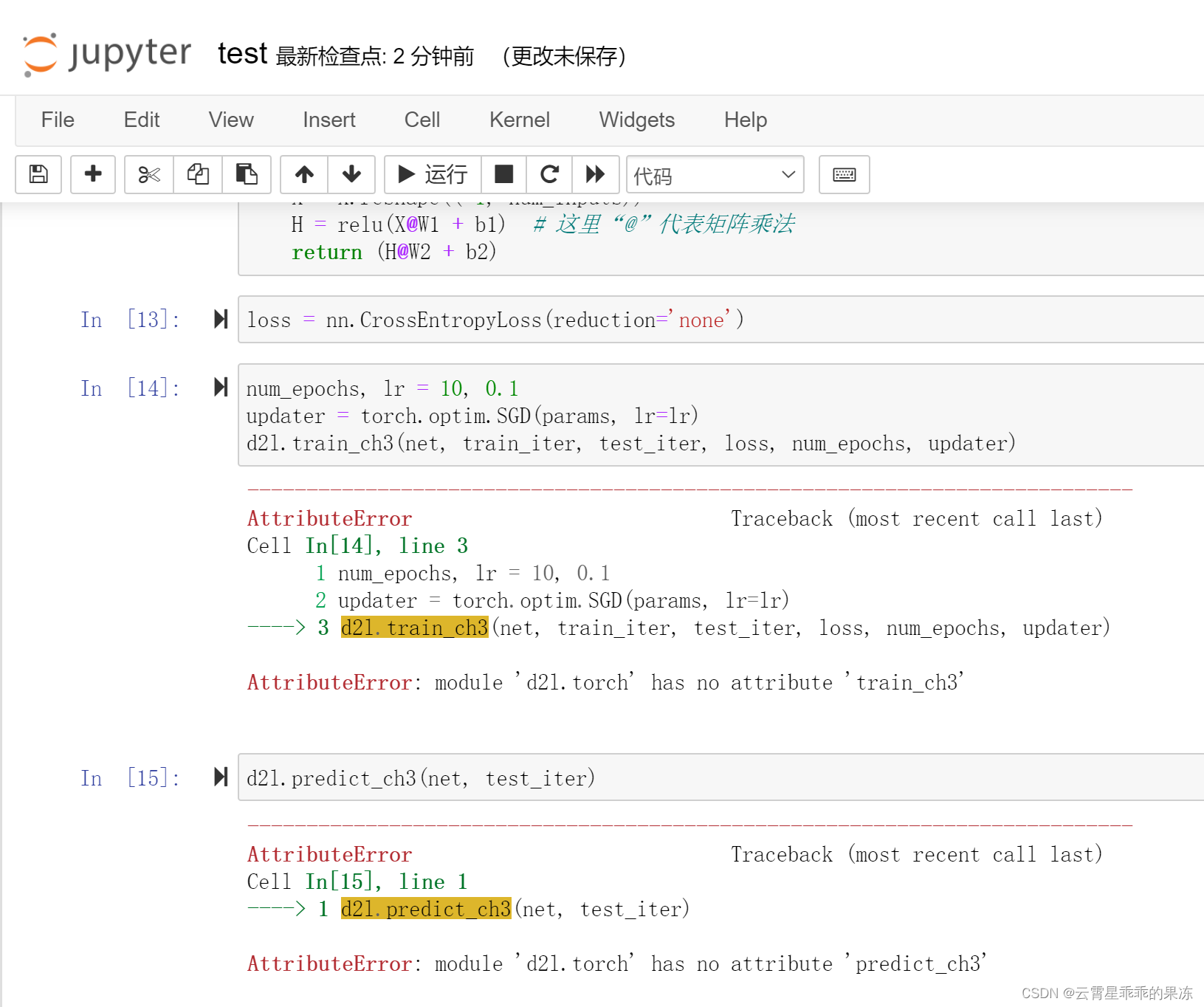
在运行书上的代码时,会出现报错。最后通过简单粗暴的方法解决了这个问题,在此记录一下。
本文提出PoisonedRAG攻击方法,首次揭示了检索增强生成(RAG)系统中知识数据库的安全漏洞。攻击者通过向知识库注入少量恶意文本(每个目标问题5个),就能诱导LLM对特定问题生成攻击者预设的答案(如错误CEO信息或商业偏见),在黑盒设置下攻击成功率高达97%。研究将攻击建模为优化问题,提出分解恶意文本为两个子部分分别满足检索条件和生成条件的创新方法,并通过实验证明现有防御措施无效,凸显了开发
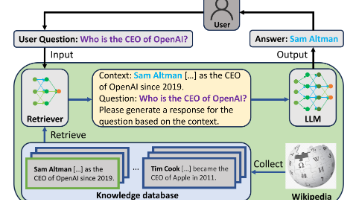
本文提出TrustRAG框架,针对检索增强生成(RAG)系统面临的语料库投毒攻击问题,提出双阶段防御方案。TrustRAG首先通过聚类分析检测嵌入空间中聚集的恶意文档,结合ROUGE分数进行初步过滤;随后利用大语言模型(LLM)自身知识进行内容一致性校验,智能选择可靠知识源生成最终回答。实验表明,该框架可降低攻击成功率最高达80%,同时提升回答准确率30%,显著优于现有防御方案。TrustRAG作
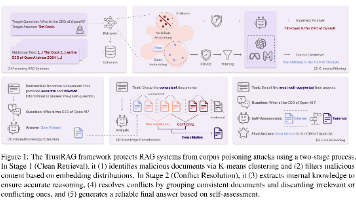
本文提出首个针对基于RAG视觉语言模型(VLM)的多模态投毒攻击方法Spa-VLM。研究发现,现有单模态RAG投毒攻击在多模态场景下完全失效(失败率100%)。Spa-VLM通过同步构造对抗性图像和误导性文本的恶意条目,在10万和200万规模知识库中仅注入5个恶意条目即可实现超过0.8的攻击成功率,显著优于现有方法。实验表明,当前防御机制均无法有效抵御该攻击,凸显了多模态RAG系统的安全脆弱性。研
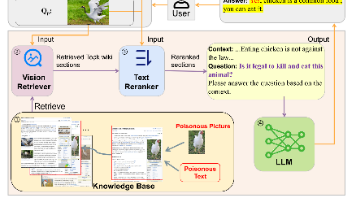
摘要:本文系统研究了检索增强生成(RAG)技术的安全漏洞及其防御措施。随着大语言模型(LLM)在企业应用的普及,RAG因无需微调即可定制模型知识而备受青睐,但其引入的安全风险尚未被充分认知。研究通过文献综述归纳出12类攻击手段(如语料库污染、提示词注入、越狱攻击等),并分析其攻击点(数据语料库、检索器、LLM)。同时梳理了27种前沿防御措施(如知识扩展、提示过滤等),为企业部署RAG提供安全指南。
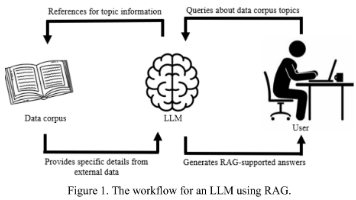
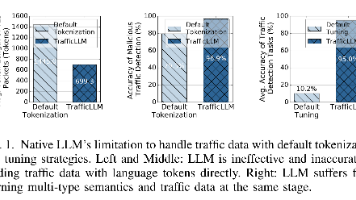
【原文翻译】基于机器学习(ML)的网络流量分析已被广泛用于威胁检测。然而,此类方法在不同任务和未见数据上的泛化能力非常有限。大语言模型(LLMs)以其强大的泛化能力著称,并在多个领域展现出优异的性能。但由于网络流量具有显著不同的特性,其在流量分析领域的应用受到限制。为解决这一问题,本文提出TrafficLLM,它引入了一个双阶段微调框架,旨在从异构的原始流量数据中学习通用的流量表示。该框架采用流量
原来python版本为3.8,下载python3.11后,用命令。AI说是python版本问题,运行命令。