




- @qq_39522016
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
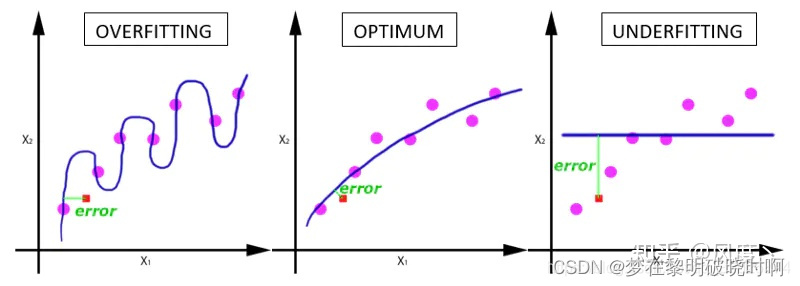
YOLOv5是一种流行的深度学习算法,用于实时目标检测任务。由于其高效性和速度,YOLOv5被广泛应用于各种实际应用中。然而,有时候模型的训练结果可能不尽如人意。在这篇文章中,我们将介绍一些提升YOLOv5模型训练结果的小技巧。

当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )。再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。***Batch(批 /
在使用pytorch定义神经网络结构时,经常会看到类似如下的.view()/ flatten()用法,这里对其用法做出讲解与演示。

标注框的形状和大小:对于不同大小的物体,标注框应完全包含住物体。并且标注框的形状尽可能接近物体形状。标注框的位置和方向:标注框尽可能地包围目标物体,而且标注框的位置和方向应标与实际场景中的位置和方向一致。标签的准确性和唯一性:每个目标物体应尽可能地被正确地标注,并且标注的标签应该与目标物体相对应。去除冗余信息:在标注数据时,应该去除冗余的信息,例如背景重复的物体等,以提高目标检测算法的准确性和效率

转载自K同学原文链接如下:https://blog.csdn.net/qq_38251616/article/details/122391011?仅用于自用学习,谨防原文失效,请大家支持原创。

当一个完整的数据集通过了神经网络一次并且返回了一次,这个过程称为一次>epoch。(也就是说,所有训练样本在神经网络中都 进行了一次正向传播 和一次反向传播 )。再通俗一点,一个Epoch就是将所有训练样本训练一次的过程。然而,当一个Epoch的样本(也就是所有的训练样本)数量可能太过庞大(对于计算机而言),就需要把它分成多个小块,也就是就是分成多个Batch 来进行训练。***Batch(批 /
转载自K同学原文链接如下:https://blog.csdn.net/qq_38251616/article/details/122391011?仅用于自用学习,谨防原文失效,请大家支持原创。
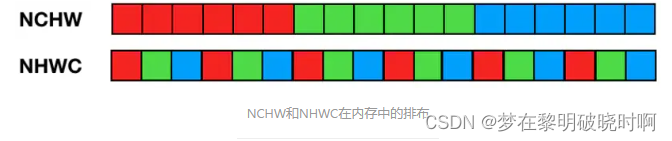
*结论:**在训练模型时,使用GPU,适合NCHW格式;在CPU中做推理时,适合NHWC格式。采用什么格式排列,由计算硬件的特点决定。OpenCV在设计时是在CPU上运算的,所以默认HWC格式。TensorFlow的默认格式是NHWC,也支持cuDNN的NCHW。链接:https://www.jianshu.com/p/61de601bc90f。作者:LabVIEW_Python。
在传统的图像识别模型中,如卷积神经网络 (Convolutional Neural Network, CNN),由于它们的局部连接和池化操作,它们在处理图像时倾向于只关注局部区域,而对于图像中远距离的特征,它们的捕捉能力会有所下降。在图像识别中,“long-range” 通常指的是模型在处理图像时能够捕捉到图像中远距离相关性或模式的能力。总之,long-range在图像识别中的意思是指模型在处理图

其中一个原因是因为使用了Fuse前向加速推理方法,将Conv和BN层融合在了一起,具体见torch_utils.py文件中的fuse_conv_and_bn函数。验证时,由于加载的是训练好的权重文件,参数不需要更新,所以不需要求梯度,因此gradients=0。训练时所有参数都需要梯形反向传播,所以训练时grandients = parameters。原因也是使用了Fuse前向加速推理方法,将Co