




- @qq_39020390
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
7B参数模型在代码修复任务上超越32B大模型,单任务成本直降8.2倍,代码数据零外泄——这不是实验室的远景,而是今天就能部署在UltraLAB工作站上的现实。2026年2月,Meta联合密歇根大学、斯坦福大学发布的SWE-Protégé框架,为软件工程领域带来了一次范式革新。它通过“专家-门徒”协作架构,让一个7B的小模型(门徒)承担90%的常规代码工作,仅在必要时才调用云端大模型(专家)进行战术

模型规模内存容量内存通道CPU核心关键设置<500万128GB双通道16-24核默认即可500-1000万256GB四/八通道24-64核手动内存+临时目录1000-2000万512GB八/十六通道64-128核核数限制+结果精简>2000万1TB+十六通道128核+集群或分布式核心原则• 内存容量决定“能不能算”• 内存带宽决定“算多快”• 核心数只有在带宽匹配时才有价值• 永远不要依赖核外求解
模型规模推荐内存关键配置点<100万自由度32GB双通道即可100-500万64-128GB四通道优先500-1000万128-256GB八通道必选>1000万512GB+十六通道 + 核外求解NVMe核心原则• 内存容量决定“能不能算”• 内存带宽决定“算多快”• 永远不要依赖虚拟内存/页面文件更多方案:浏览器访问。

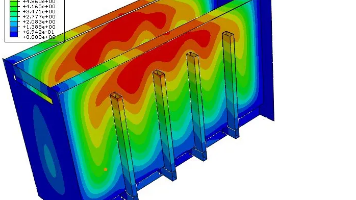
边缘智能的仿真验证是连接云端模型与边缘部署的关键桥梁。交叉编译的兼容性、TensorRT的精度对齐、容器环境的一致性、QEMU的仿真精度——每一个环节都对硬件提出明确要求。UltraLAB边缘智能仿真工作站基于真实开发负载设计,覆盖从个人原型到CI/CD集群的全场景需求。场景CPUGPU内存存储推荐机型主力开发64核 5.1GHz256GBGA660M集群验证128核512GBGX660个人原型2
从个人算法开发到千例级数据库训练,每一款产品的配置逻辑都源自真实医学影像负载的量化分析——让研究者专注于模型创新与临床验证,而非底层算力的“显存墙”与“I/O墙”。如需针对具体影像模态(CT/MRI/病理图像)、模型架构(3D U-Net/Transformer)及数据规模(百例/千例/万例)的定制化配置,欢迎联系UltraLAB技术顾问团队。:3D U-Net/nnU-Net训练、高分辨率CT/
大模型的价值最终通过推理服务兑现。无论是对外提供API的千级并发,还是嵌入智能设备的毫秒级响应,背后都是推理引擎与硬件架构的深度协同。高显存带宽:突破生成速度瓶颈大显存容量:承载更大模型与更高并发低延迟互连:支撑多卡并行扩展UltraLAB大模型推理方案,正是基于对这一技术栈的深度理解而设计。从单卡旗舰到多卡集群,每一款工作站的配置逻辑都源自真实推理负载的量化分析——让研究者和工程师专注于模型与业

大模型从实验室走向产业应用,依赖的是算法、数据与算力的三位一体。当模型参数突破千亿、训练数据迈向万亿Token,算力基础设施的精准配置已不再是“后勤保障”,而是直接决定技术路线的可行性边界。UltraLAB基于对大模型计算特征的深度理解,提供从个人验证到千卡集群的全系列硬件方案。每一台工作站的配置逻辑,都源自对显存容量、卡间互联、存储I/O三大瓶颈的系统性突破——让研究者专注于模型架构与算法创新,

2026年的工作站选型不再是简单的“核心数对比”。CFD/多物理场/超大模型:Intel Xeon 600的MRDIMM带宽与4TB内存上限是决定性优势科学计算/渲染/AI训练:AMD Threadripper 9000的全宽AVX-512与96核密度提供更高吞吐量芯片设计/高频交易:Intel的单核性能与缓存架构仍不可替代UltraLAB建议科研团队在采购前进行典型算例基准测试:使用您的500万

当半导体技术进入埃米(Angstrom)时代,仿真精度与算力密度的赛跑从未停止。从GAAFET的原子级TCAD,到Chiplet的百亿节点签核,从AI驱动的EDA布局,到量子计算的低温控制——每一个前沿课题的突破,都建立在精准配置的算力底座之上。UltraLAB深耕行业计算应用十余年,通过精准分析软件计算特点,为清华大学集成电路学院、中科院微电子所等顶级机构提供定制化硬件方案。2026年,让我们用

7B参数模型在代码修复任务上超越32B大模型,单任务成本直降8.2倍,代码数据零外泄——这不是实验室的远景,而是今天就能部署在UltraLAB工作站上的现实。2026年2月,Meta联合密歇根大学、斯坦福大学发布的SWE-Protégé框架,为软件工程领域带来了一次范式革新。它通过“专家-门徒”协作架构,让一个7B的小模型(门徒)承担90%的常规代码工作,仅在必要时才调用云端大模型(专家)进行战术