- @qq_38342510
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
向导会显示摘要:模型选择、工作区路径、端口、守护进程状态。过目无误后回车完成。

摘要:本文详细介绍了在树莓派5和香橙派5 Ultra(RK3588)等ARM开发板上部署OpenClaw AI助手的完整流程。文章首先分析了ARM开发板作为7x24运行设备的优势(低功耗、低成本),并对比了两款设备的性能差异。随后分步骤讲解了环境准备、Node.js安装、OpenClaw部署等关键环节,特别强调了SSH真实登录、网络连通性检查等易错点。最后提供了系统服务配置和运行验证方法,为开发者

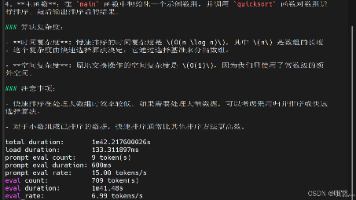
本文介绍了prima.cpp(llama.cpp的分布式实现)的部署过程及性能测试。首先配置4节点集群,安装必要工具并下载Q8_0量化模型。测试发现Qwen3-14B模型存在兼容性问题,改用Qwen2.5系列后,3B模型速度仅1.5 token/s,0.5B模型达5 token/s。对比单节点ollama部署(3B模型1.21 token/s,0.5B模型6.99 token/s),发现prima
推理阶段,没有优化器状态和梯度信息,也不需要保存中间激活。因此推理阶段占用的显存要远远远小于训练阶段。模型推理阶段,占用显存的主要是模型权重和 kv cache。通过知识蒸馏将 DeepSeek-R1 的模型参数迁移到更小参数规模的 Qwen、Llama 等小模型中,这些模型实际上就是 Qwen、Llama 模型。在 V3 的基础上,采用传统预训练-监督微调+MoE架构模型,DeepSeek-R1
LivePortrait大模型,只需要一张人脸正面图片和一段文字或音频,即可制作专业的视频内容。LivePortrait 的展示样例:https://liveportrait.github.io/LivePortrait 理论研究,论文:https://arxiv.org/pdf/2407.03168s。
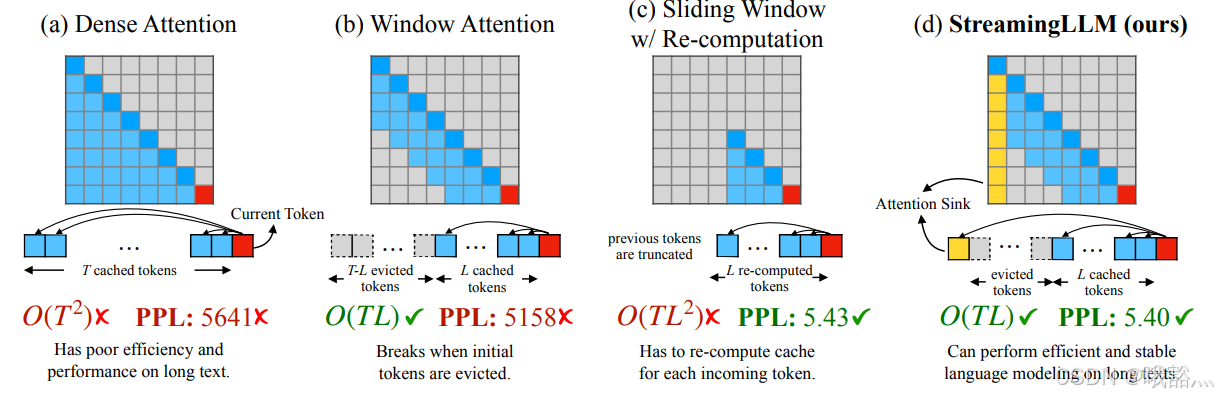
因为 Attention 的计算量和内存需求都随着序列长度增加而成平方增长,所以增加序列长度很难,一些实现方法包括:训练时用 FlashAttention 等工程优化,以打破内存墙的限制,或者一些 approximate attention 方法,比如 Longformer 这种 Window Attention 方法。这篇论文通过使用 approximate attention 的方法,放松了对
我们需要添加3个文件用以描述外部。直接编译的出的镜像文件大小有153M。文件系统的最小内核, 以。
与最常用的 GPU 卡匹配的标志。这将实现更快的运行时,因为代码生成将在编译期间发生。) 指定了 CUDA 文件将为其编译的 NVIDIA GPU 架构的名称。标志,则 CUDA 驱动程序将在JIT编译器上生成 GPU 代码。) 允许更多的 PTX 代,并且可以针对不同的架构重复多次。但是,有时可能希望通过添加更全面的。当想要加速 CUDA 编译时,想要减少不相关的。当编译 CUDA 代码时,应该
ChatTTS(Chat Text To Speech),专为对话场景设计的文本生成语音(TTS)模型,适用于大型语言模型(LLM)助手的对话任务,以及诸如对话式音频和视频介绍等应用。支持中文和英文,还可以穿插笑声、说话间的停顿、以及语气词等。
打开 VSCode,进入扩展市场(快捷键 Ctrl+Shift+X),搜索 “Continue”,然后点击安装。插件:Continue - Codestral, Claude, and more。在 VSCode 中,按。配置自动补全模型(选配)