




- @qq_37713191
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
作为具有较高影响力的信创数据库,在市面占有率比较高,本文主要介绍docker-compose形式安装该数据库。

本文介绍了使用Postman测试本地MCP服务SSE接口的方法。当直接访问http://localhost:9090/sse时会收到SSE重定向消息,无法直接调试。文章详细说明了操作步骤:1)在Postman中选择请求方式;2)启动本地MCP服务后输入接口地址;3)使用JSON或基础类型参数作为入参。该方法适用于Postman 11.53.2及以上版本,能有效解决SSE接口调试问题。

本文介绍了Web3开发的完整环境搭建流程,包括:1) 安装Node.js、Python和Git等基础工具;2) 创建项目并初始化;3) 安装以太坊相关依赖(Web3.js、Truffle/Hardhat等);4) 配置Hardhat项目,包括网络设置和环境变量管理;5) 编写智能合约示例和交互脚本;6) 提供部署合约的完整脚本。文章提供了详细的命令行操作和代码示例,涵盖了从环境配置到合约部署的全流

摘要:以太坊智能合约开发需搭建开发环境(如Hardhat),学习Solidity语言,掌握编写、测试和部署流程。关键步骤包括项目初始化、编写合约、测试、编译配置及测试网部署。推荐工具包括MetaMask、Etherscan等,学习资源如CryptoZombies和Solidity文档。安全实践强调测试、代码审查和OpenZeppelin库使用。建议从测试网开始,逐步提升复杂度,重视测试和社区最佳实

本文提供了一个完整的Java调用智能合约的示例方案,包含环境配置、合约部署和调用方法。主要内容包括:1)环境准备,添加必要的Maven依赖;2)Solidity合约示例代码,展示一个简单的存储合约;3)Java调用代码,包含合约部署、加载和读写方法调用;4)测试类演示完整调用流程;5)使用Web3j命令行工具生成Java包装类的步骤。该方案通过Web3j库实现Java与区块链智能合约的交互,覆盖了

转自:https://www.jb51.net/server/32711938t.htm
数据治理流程一、 为什么要进行数据治理?业务层面系统层面二、需要建设的系统一、 为什么要进行数据治理?业务层面1、经过 30年的信息化建设,企业和政府部门都围绕着业务需求建设了众多的业务系统,从而导致数据的种类和数量大增,看似积累了众多的数据资产,实则在需要使用时,困难重重。2、因为各个业务系统的建设都是围绕着业务需求来建设的,当业务环境发生变化时,原来的业务系统不能互联互通,不能满足跨部门、跨职
信创适配-鲲鹏处理器与麒麟操作系统下arm64架构常用docker镜像安装
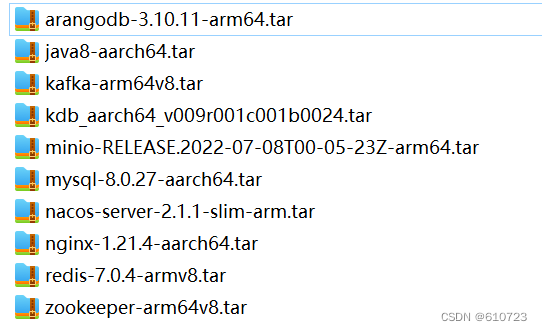
信创适配的主要目的是确保原有的系统或软件可以正常运行在信创环境(如国产CPU、操作系统、数据库等)上。这涉及到核心芯片协议、基础硬件、操作系统、数据库、中间件、服务器以及应用软件等多个层面的匹配与优化
作为具有较高影响力的信创数据库,在市面占有率比较高,本文主要介绍docker-compose形式安装该数据库。