- @qq_37553692
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
针对住宅、加油站、公路、森林等火灾高发场景,可以自动检测监控区域内的烟雾和火灾,帮助相关人员及时应对,最大程度降低人员伤亡及财物损失,模型效果如图所示。从零开始使用YOLOv5+PyQt5+OpenCV实现。全流程教程,从数据采集到模型使用到最终展示。若有任何疑问和建议欢迎评论区讨论。

佩戴口罩检测从零开始使用YOLOv5+PyQt5+OpenCV+爬虫实现(支持图片、视频、摄像头实时检测,UI美化升级)。全流程教程,从数据采集到模型使用到最终展示。 支持图片检测、视频检测、摄像头实时检测,还支持视频的暂停、结束等功能。若有任何疑问和建议欢迎评论区讨论。可以通过爬虫爬取一些佩戴口罩的图片和一些未佩戴口罩的图片。这里直接上代码,如果想详细了解可以参考我的另外一篇文章。

在每次循环中,它调用cap.read()读取摄像头的视频帧,然后调用process_frame()方法对该帧进行yolo的目标检测。这意味着在每次迭代时,生成器都会生成一个视频帧,并通过HTTP响应流发送给客户端。生成器会继续循环,读取下一帧并进行处理,然后再次通过yield语句生成下一个视频帧。这样,当客户端请求视频流时,Response对象会使用generate_frames()生成器返回的视
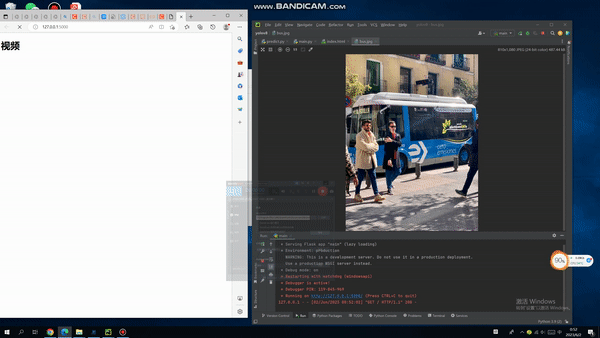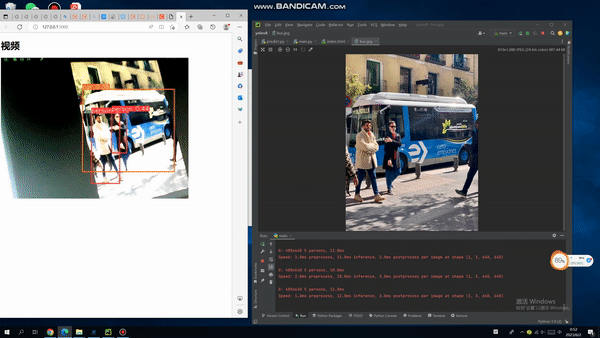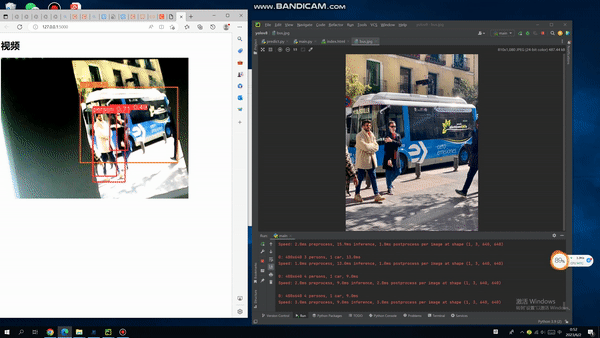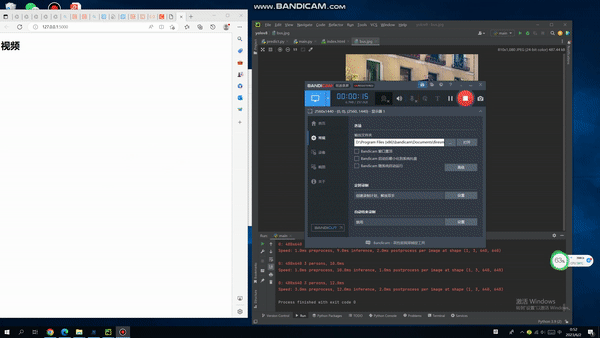
从零开始使用YOLOv5+PyQt5+OpenCV实现是否佩戴口罩检测。全流程教程,从数据采集YOLO框架(You Only Look Once)与RCNN系列算法不一样,是以不同的方式处理对象检测。它将整个图像放在一个实例中,并预测这些框的边界框坐标和及所属类别概率。使用YOLO算法最大优的点是速度极快,每秒可处理45帧,也能够理解一般的对象表示。首先,输入图像:然后,YOLO将输入图像划分为网

当人员未佩戴安全帽进入施工场所时,人为监管耗时耗力,而且不易实时监管,过程繁琐、消耗人力且实时性较差。针对上述问题,希望通过目标检测的方式智能、高效的完成此任务。

车牌检测从零开始实现使用YOLO+CRNN+PyQt5+爬虫实现(支持图片、视频、摄像头实时检测)全流程教程,从数据采集到模型使用到最终展示。 支持图片检测、视频检测、摄像头实时检测,还支持视频的暂停、结束等功能。本文使用YOLOV5来进行车辆和车牌的定位检测,定位车牌后使用CRNN进行车牌类信息的识别即做到OCR的效果。使用爬虫技术爬取百度上的图片从而制作数据集,使用PyQt5来制作我们的可视化

近年来,电瓶车进楼入户发生的火灾事故屡见不鲜,针对该现象推出了相应的电瓶车入室检测模型,旨在从源头减少这一情况的发生。从零开始使用YOLOv5+PyQt5+OpenCV实现 。全流程教程,从数据

智能零售柜商品识别,当顾客将自己选购的商品放置在制定区域的时候,能精准地识别每一个商品,从而能够返回完整地购物清单及计算顾客应付的实际商品总价格。已经处理了一份数据形成了对应的数据集。总数据量为5422张,且所有图片均已标注,共有113类商品。本数据集以对数据集进行划分,其中训练集3796张、验证集1084张、测试集542张。使用YOLOv5+PyQt5+OpenCV实现

通过对吸烟的自动检测可以方便商场、医院、疗养院等公共场合进行禁烟管控。吸烟检测从零开始使用YOLOv5+PyQt5+OpenCV实现。全流程教程,从数据采集到模型使用到最终展示。

model: 模型文件的路径。这个参数指定了所使用的模型文件的位置,例如 yolov8n.pt 或 yolov8n.yaml。模型文件包含了已经训练好的模型的权重和结构。data: 数据文件的路径。该参数指定了数据集文件的位置,例如 coco128.yaml。数据集文件包含了训练和验证所需的图像、标签和其他数据的信息。epochs: 训练的轮数。这个参数确定了模型将会被训练多少次,每一轮都遍历整个