




- @qq_33290813
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
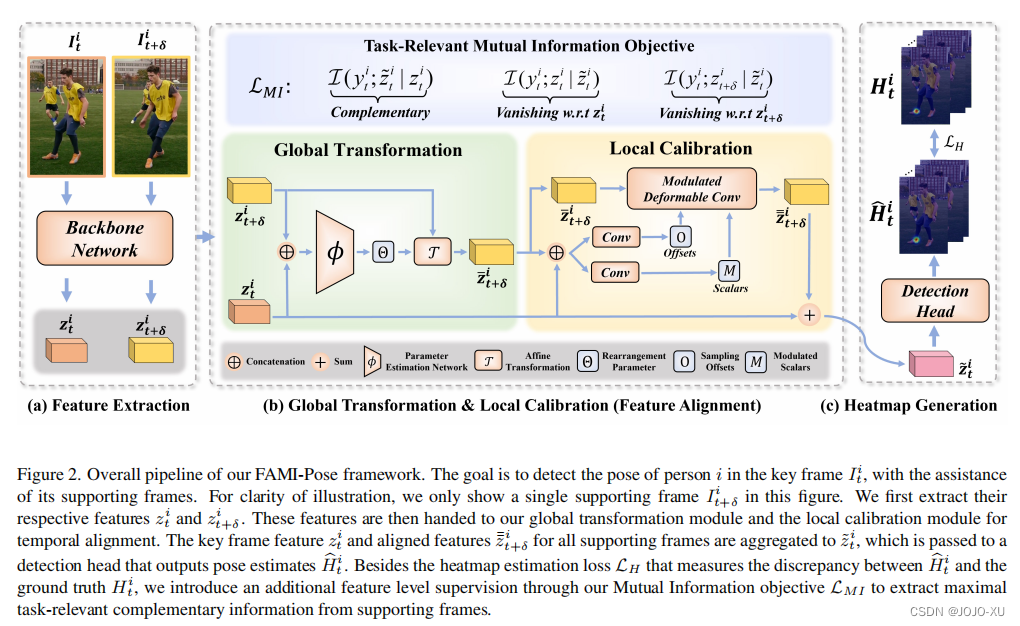
Temporal Feature Alignment and Mutual Information Maximization forVideo-Based Human Pose Estimation多帧人体姿态估计是具有挑战性的,因为快速运动和姿态遮挡经常发生在视频中。最先进的方法努力结合来自邻近帧(支持帧)的额外视觉证据,以促进对当前帧(关键帧)的姿态估计。到目前为止已经排除的一个方面是,当前的
知识图谱表示学习对于知识获取和下游应用具有很重要的作用. 知识表示学习的表示空间包括:point-wise空间,流形空间,复数空间,高斯分布和离散空间. 打分函数通常分为基于距离的打分和基于语义匹配的打分函数. 编码模型包括:线性/双线性模型,张量分解和神经网络. 辅助信息考虑文本,视觉和类型信息.1.1.1 Point-wise空间Point-wise的欧式空间是最常用的,将知识图谱中的实体和关
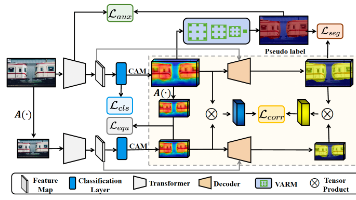
中科院自动化所等机构提出的TSCD方法在AAAI 2023获Oral论文,该研究通过自对应蒸馏(SCD)和变分感知优化模块(VARM),构建了端到端Transformer弱监督语义分割框架。在PASCAL VOC和COCO数据集上达到SOTA性能,VOC val集65.0% mIoU,显著优于同类方法。该工作创新性地利用网络自身CAM特征对应关系进行蒸馏,无需外部监督,为弱监督分割提供了新思路。
目标检测(Object Detection)的目的是“识别目标并给出其在图中的确切位置”[1],其内容可解构为三部分:识别某个目标(Classification);给出目标在图中的位置(Localization);识别图中所有的目标及其位置(Detection)。从这三点可以看出目标检测的难度要比图像分类大很多,后者只需要确定输入的图像属于哪一类即可,而前者需要从图像中自动抠出(crop)合适大小
双分支残差网络(DB-ResNet),集成了两种新方案,以提高模型的泛化能力:1)提出的模型可以同时捕获CT图像中不同结节的多视图和多尺度特征;2)我们结合了强度和卷积神经网络(CNN)的特征。我们提出了一种池化方法,称为中央强度池层(CIP),提取块的中心体素的强度特征,然后使用CNN获得块的中心体素的卷积特征。另外,我们设计了基于结节边界的加权采样策略,以使用加权得分选择那些体素,以提高模型的
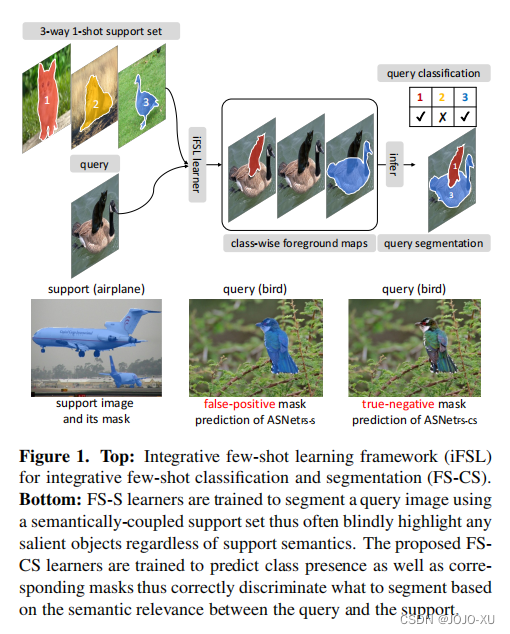
用于分类和分割的综合小样本学习本文介绍了小样本分类和分割(FS-CS)的综合任务,即when the target classes are given with a few examples,对查询图像中的目标对象进行分类和分割。该任务结合了两个传统的小样本分类和分割任务。FS-CS将它们概括为具有任意图像对的更真实的事件,其中每个目标类可能出现在查询中,也可能不存在。为了解决这一任务,我们提出了
Attention机制最早在视觉领域提出,九几年就被提出来的思想,真正火起来应该算是2014年Google Mind发表了《Recurrent Models of Visual Attention》,使Attention机制流行起来,这篇论文采用了RNN模型,并加入了Attention机制来进行图像的分类。不同于全图扫描,该 算法每次仅瞥见图像中的部分区域,并按时间顺序 将多次瞥见的内容用循环神经
图像分类简介https://www.cnblogs.com/paladinzxl/p/9491633.htmlPyTorch简单实现(Nearest Neighbor,Linear Classification,CNN)https://blog.csdn.net/KobeLovesDawn/article/details/86771279几种经典cnn网络介绍https://blog.csdn.n