




- @qq_30650051
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
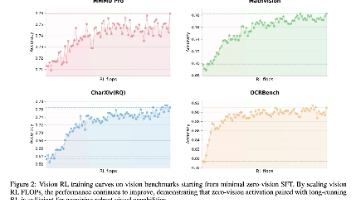
本文探讨了文本-视觉联合训练的优化策略。研究发现,早期以恒定比例融合视觉与文本token进行多模态预训练,能显著提升模型表现。通过"zero-vision SFT"方法,仅使用文本数据即可激活视觉能力,且视觉强化学习还能反哺文本性能。Kimi K2.5采用按能力而非模态组织的联合RL范式,实现了跨模态能力迁移。案例显示,模型能通过工具调用将复杂视觉任务转化为可编程操作,展现了强
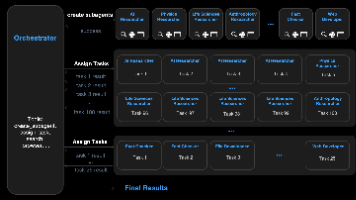
Agent Swarm是Kimi推出的并行化AI功能,通过主Agent动态创建并管理多个子Agent协同完成任务。采用PARL训练方法,初期鼓励并行执行,后期侧重任务质量。技术报告显示其性能优于Claude Opus 4.5,但需199元/月订阅。关键创新包括并行执行机制和Critical Steps延迟指标,解决了传统串行Agent速度慢、智能化不足的问题。实际效果尚待验证。
希望把Linux上生产环境中使用docker compose运行的milvus迁移到本地(mac os)的docker compose中。

RAG利用了向量数据库和大型语言模型(LLM)的能力来提升回答质量。在数据的准备过程中,通过特定的加载器将各种模态的信息进行导入,由于各种信息的大小参差不齐,故需要对其进行切片处理,在将每个部分进行切片后,embedding到特定维度的向量,将源数据喝向量一起存储到向量数据库中。常见的向量数据库引擎有:FAISS、Chromadb、ES、Milvus,本文采用Milvus进行实践在调用的过程中,先
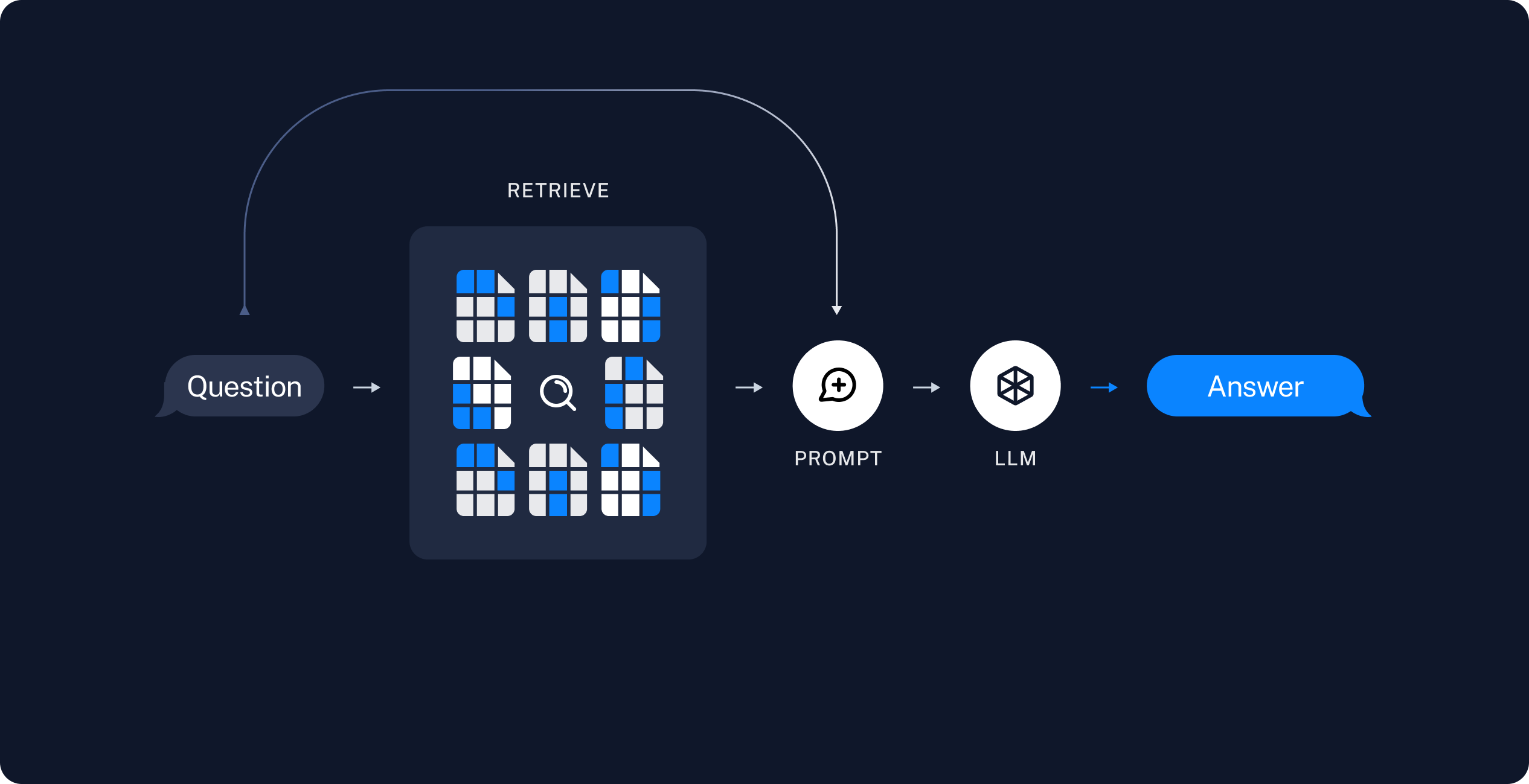
RAG利用了向量数据库和大型语言模型(LLM)的能力来提升回答质量。在数据的准备过程中,通过特定的加载器将各种模态的信息进行导入,由于各种信息的大小参差不齐,故需要对其进行切片处理,在将每个部分进行切片后,embedding到特定维度的向量,将源数据喝向量一起存储到向量数据库中。常见的向量数据库引擎有:FAISS、Chromadb、ES、Milvus,本文采用Milvus进行实践在调用的过程中,先