




- @qq_24428851
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
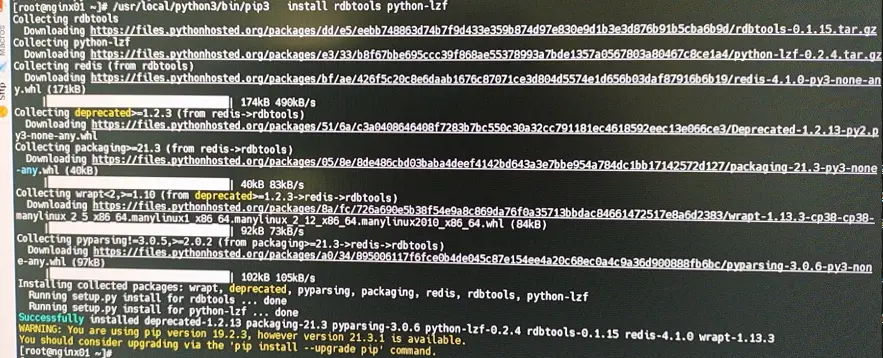
一、简介redis是基于内存的kv数据库,内存作为存储介质,关注内存的使用情况是一个重要的指标。解析内存有两种方法,一个是通过scan遍历所有key,二是对rdb文件进行分析。rdb 是rdb-tools工具包其中之一的工具,也是解析dump.rdb文件的工具。
这是一个在String变量中的内容:使用 groovy 结合 java ,写一个动态解析上述变量并执行逻辑的demo。

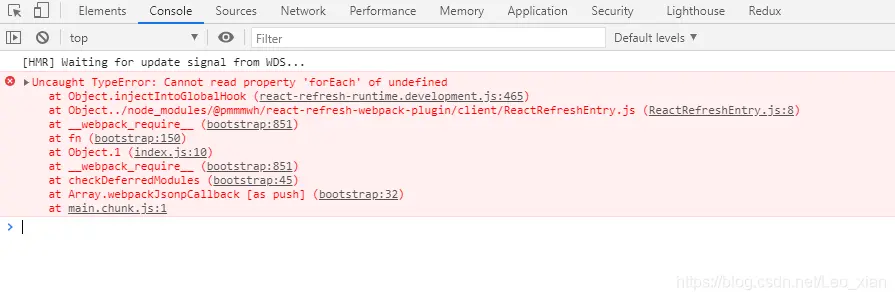
react项目运行时控制台报错,尝试删除react-refresh安装包后重装,依然有问题。一番查阅后得知是react-devtools开发者工具导致的问题,在开发者模式里关闭掉该工具后,问题貌似解决了。
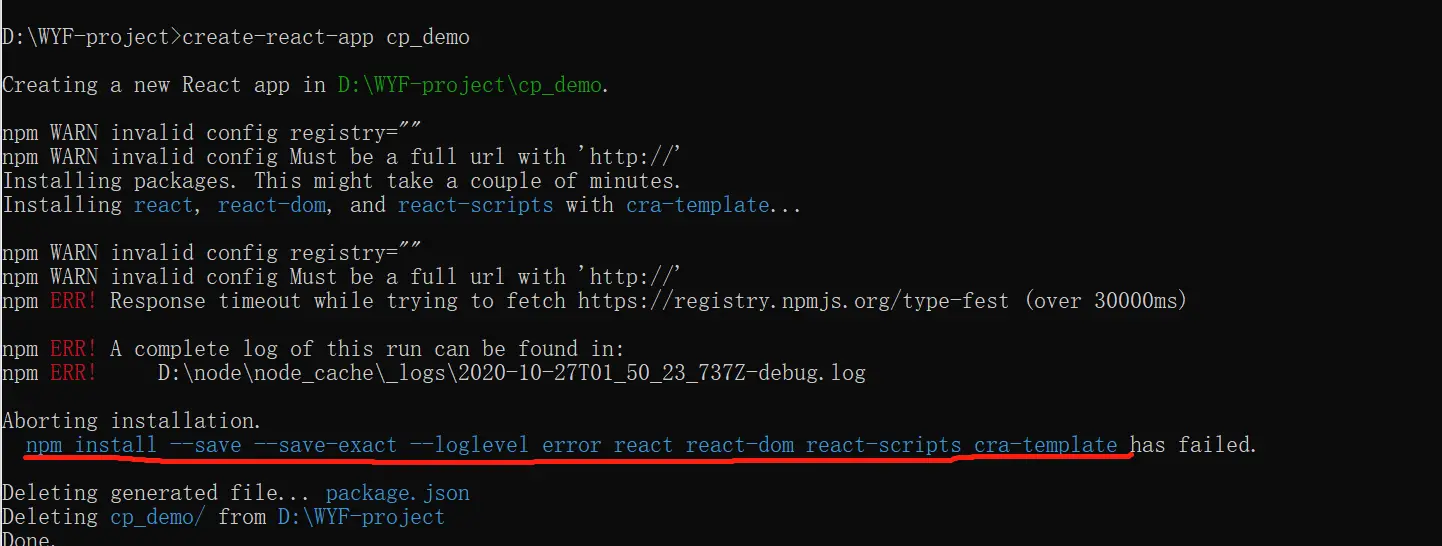
平台声明:文章内容(如有图片或视频亦包括在内)由作者上传并发布,文章内容仅代表作者本人观点,简书系信息发布平台,仅提供信息存储服务。然后再重新执行create-react-app创建项目,就不会报错了。著作权归作者所有,转载或内容合作请联系作者。npm 拉取国外的资源拉取不到,所以报错。
平台声明:文章内容(如有图片或视频亦包括在内)由作者上传并发布,文章内容仅代表作者本人观点,简书系信息发布平台,仅提供信息存储服务。在扩展中搜索python3 ,安装成功后,配置python3的解释器路径: /usr/local/bin/python3。找到"python.defaultInterpreterPath": "/usr/local/bin/python3"点击扩展插件右下角的设置(小
所谓的计算机高级语言,实际上指的:人为的规定一些语法。Java的简单性,指的是Java语言的这种特点:1、Java语言本身的特点非常简单,没有复杂和晦涩的语法细节;而Java语言同时也是复杂的,体现在:1、虽然Java语言本身非常简单,但是它有大量强大而扎实的类库,这些类库极大的丰富了Java语言的特性;2、Java语言最主要的阵地是企业级应用,这种应用本身,由于涉及到多线程、分布式、数据库、网络
任职于Sun微系统的詹姆斯·高斯林等人于1990年代初开发Java语言的雏形,最初被命名为Oak,目标设置在家用电器等小型系统的编程语言,应用在电视机、电话、闹钟、烤面包机等家用电器的控制和通信。这与微软公司所倡导的注重精英和封闭式的模式完全不同,此外,微软公司后来推出了与之竞争的.NET平台以及模仿Java的C#语言。Java的原生类库提供了对多线程编程的支持,这使得Java在一些高并发的应用场
image这是系列文章【 Java 面试八股文】数据库篇的第二期。【 Java 面试八股文】系列会陆续更新 Java 面试中的高频问题,旨在从问题出发,理解 Java 基础,数据结构与算法,数据库,常用框架等。该系列前几期文章可以通过点击文末给出的链接进行查看~【 Java 面试八股文】中的面试题来源于社区论坛,书籍等资源;对于【 Java 面试八股文】中的每个问题,我都会尽可能地写出我自己认为的

image从今天开始,我将开启一个系列的文章——【 Java 面试八股文】。这个系列会陆续更新 Java 面试中的高频问题,旨在从问题出发,理解 Java 基础,数据结构与算法,数据库,常用框架等。【 Java 面试八股文】中的面试题来源于社区论坛,书籍等资源;对于【 Java 面试八股文】中的每个问题,我都会尽可能地写出我自己认为的“完美解答”。

2022 Java生态系统报告近日,New Relic发布了最新的2022 Java生态系统报告,这份报告可以帮助我们深入的了解Java体系的最新使用情况,下面就一起来看看2022年,Java发展的怎么样了,还是Java 8 YYDS吗?
