




- @qq_22054285
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
循环神经网络全景介绍,从RNN到LSTM再到GRU,全面介绍循环神经网络全貌。
文章目录1 隐私计算综述2 隐私计算发展史3 加密技术概述4 同态加密的历史5 什么是同态加密6 同态加密的定义6.1 场景定义6.2 核心流程6.3 HE的分类7 同态加密库Paillier7.1 Paillier算法7.2 秘钥生成7.3 明文加密7.4 密文解密7.5 相关代码8 参考资料9 番外篇1 隐私计算综述近年来,随着大数据与人工智能的盛行,针对个人的个性化的推荐技术的不断发展,人们

前一阵打算写这方面的文章,不过发现一个问题,就是如果要介绍Transformer,则必须先介绍Self Attention,亦必须介绍下Attention,以及Encoder-Decoder框架,以及GRU、LSTM、RNN和CNN,所以开始漫长的写作之旅。截止本文终于完成这个漫长的过程,
一 背景大抵是去年底吧,收到了几个公众号读者的信息,希望能写几篇介绍下Attention以及Transformer相关的算法的文章,当时的我也是满口答应了,但是确实最后耽误到了现在也没有写。前一阵打算写这方面的文章,不过发现一个问题,就是如果要介绍Transformer,则必须先介绍Self Attention,亦必须介绍下Attention,以及Encoder-Decoder框架,以及GRU、L
文章目录一 背景二 线性与非线性模型1 线性模型2 非线性模型三 深度学习的非线性表达一 背景近年来,伴随着大数据与大算力的突破性进展,基于深度学习的突破层出不穷,基于卷积的网络结构在图像领域大放异彩、基于时序的网络模型在搜广推被广泛使用,并且产生了巨大的经济与体验效益,深受广大算法从业者的偏爱。那么什么是深度学习呢?深度学习为何会如此强悍呢?引用维基百科对于深度学习的定义:通过多层非线性变

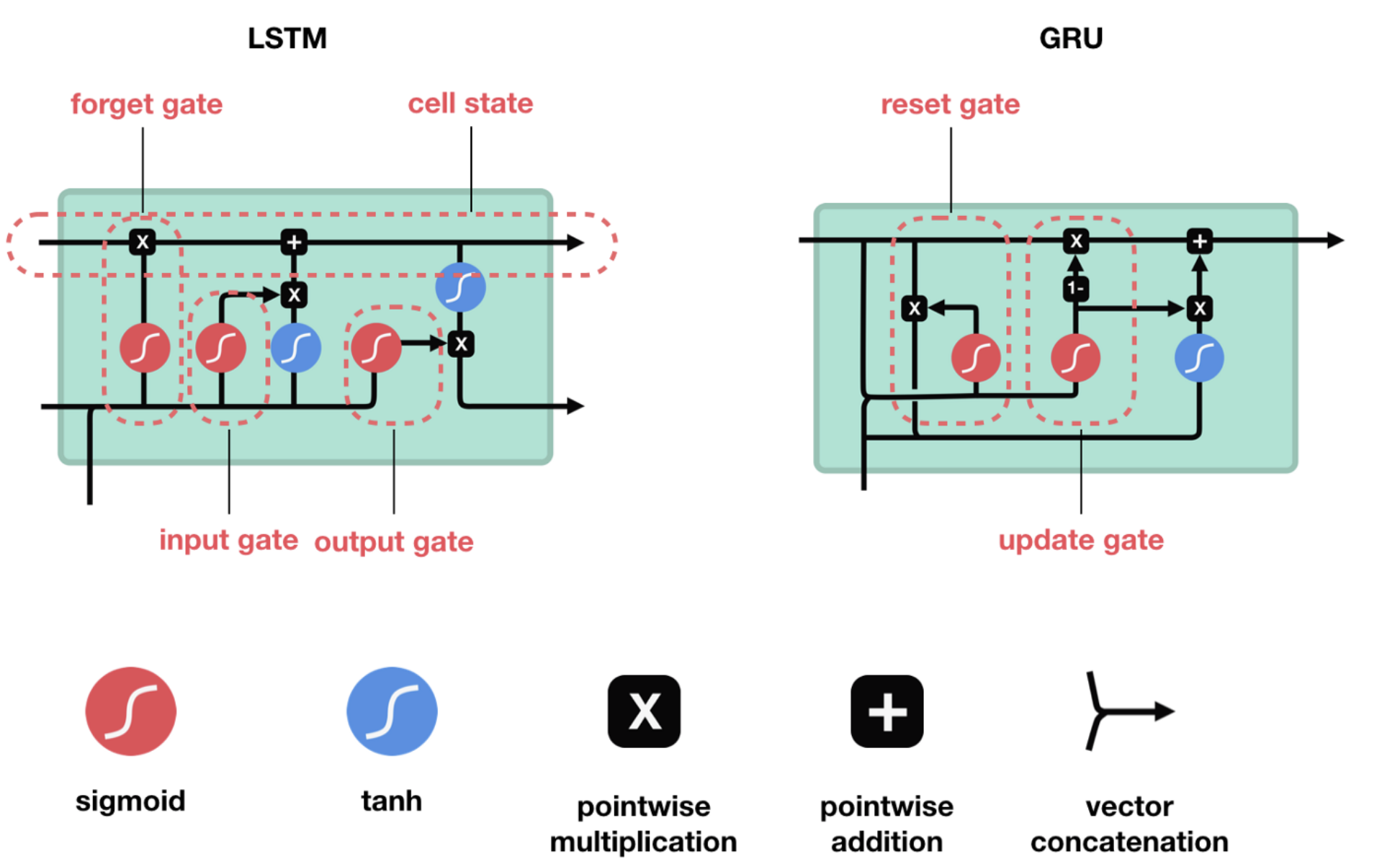
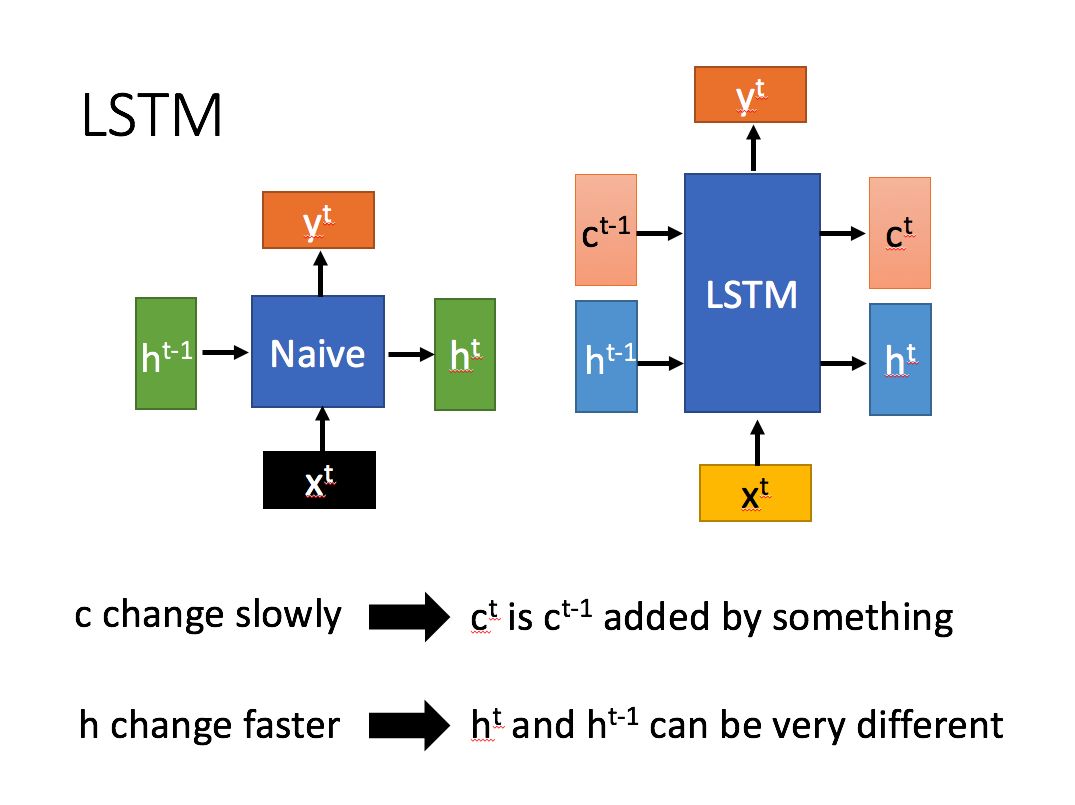
长短时记忆网络(Long Short Term Memory Network)LSTM,是一种改进之后的循环神经网络,通过门控机制有选择的记忆重要的内容,可以解决RNN无法处理长距离的依赖的问题,目前比较流行。LSTM结构(图右)和普通RNN的主要输入输出区别如下所示。
本文介绍隐私计算基础组件,包含同态加密 秘密分享 差分隐私等

循环神经网络全景介绍,从RNN到LSTM再到GRU,全面介绍循环神经网络全貌。
蓦然回首,发现写了很多联邦学习方面的文章,但是没有写一篇联邦学习方面的介绍性的综述,所以写了这篇文章,从整体介绍下联邦学习的背景、联邦学习的简介、隐私保护技术与营销应用场景。▌联邦学习背景数据是AI的石油,加速了AI的高速发展,但是同时多维度高质量的数据是制约其进一步发展的瓶颈。由于用户隐私、商业机密、法律法规监管等原因,造成大量信息孤岛,导致各个组织与机构无法将原始数据整合在一起,进而联合训练训

