- @python__reported
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
人脸识别与天网系统一、结果二、识别库三、实现代码一、结果识别对象第一个是名字,第二个是百度上的内容二、识别库face_recognition三、实现代码class Face_recognition():def __init__(self,pic,pics):self.pic = picself.pics = picsself.name = ""def face_know(self,file):kn
《Python机器学习基础教程》第二章笔记:random_state的作用一、random_state的作用:固定系数与截距二、random_state的取值是对系数排序的结果,random_state值越小,系数越大一、random_state的作用:固定系数与截距random_state的作用在于固定lr.coef_、lr.intercept_,保证每次模型的系数、截距一致不加random_s
学习笔记:python编程从入门到实践django 安装成功,但是输入命令python manage.py migrate时依旧出现“ImportError: No module named Django”,按照许多大神教的寻找版本是否冲突已经无解。在idle上import也没有报错。这就说明确实存在django,版本正确。多次重复虚拟环境进入也没有问题,但是依然出现“ImportError: .
庭审录播爬虫一、庭审直播网二、爬取对象三、爬取分析(一)视频地址获取(二)视频文件四、 视频下载五、成果六、问题一、庭审直播网二、爬取对象庭审公开网的内容包括直播与录播直播没有办法爬,只能看的时候进行录制所有选定的目标为录播三、爬取分析(一)视频地址获取首先录播视频的加载方式为点击查看更多后进行动态进行新内容的加载加载中url并不变化其中case_list中的就是视频的地址不点击see more不
电脑卡在系统logo处一、现象电脑开机时卡在系统logo处即Windows10的图标处,如下图所示导致长时间停留于此或者2-10分钟才能开机,或者SSD开机时间在50秒左右。二、原因及解决方法原因:关闭了虚拟内存方法:开机后进入安全模式,注意进入安全模式的时间也会很长需要等待几分钟将虚拟内存打开后即可。进入此电脑,右键属性,选择高级系统设置,高级,性能栏的设置,选择高级,虚拟内存栏点击处更改,选择
《Python机器学习基础教程》第一章笔记(最简单的监督学习):鸢尾花品种预测三行程序三行程序from sklearn.datasets import load_irisimport pandas as pdimport numpy as npfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors imp
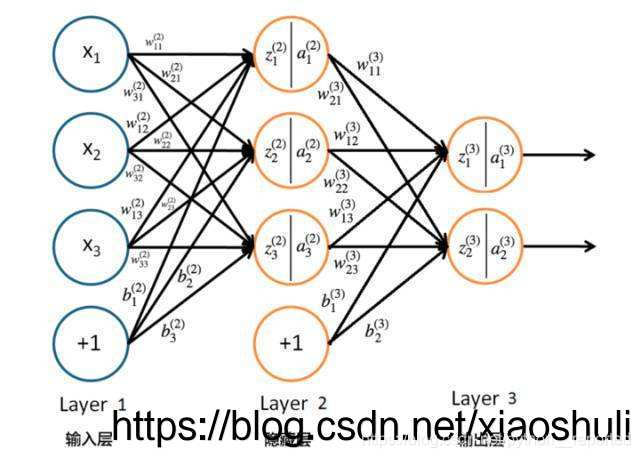
关于可视化神经网络中间层的详细说明一、对一些处理的意义的说明二、代码一、对一些处理的意义的说明activation_model = models.Model(inputs=model.input, outputs=layer_outputs)#此处的inputs是之前导入的模型,model = load_model('...(解释:自己的模型)')# 特征图的形状(1,宽,高,n_features
《Python机器学习基础教程》第二章笔记:random_state的作用一、random_state的作用:固定系数与截距二、random_state的取值是对系数排序的结果,random_state值越小,系数越大一、random_state的作用:固定系数与截距random_state的作用在于固定lr.coef_、lr.intercept_,保证每次模型的系数、截距一致不加random_s
@[TOC](《Python机器学习基础教程》第二章笔记:ValueError: cannot reshape array of size 4000000 into shape (1000,1000))成功解决:增加命令y = y % 2一、报错ValueError: cannot reshape array of size 4000000 into shape (1000,1000)二、尝试解决
@TOC)一、结论Dense层维度要与标签维度一致,根据需要的一致;[1,2,3]对应0与[1,2,3]对应[5,6,8]即可。如文本分类,则标签不需要one-hot,dense层不需要TimeDistributed因为文本分类 train_x(16656, 22) ,使得22个字的评论与标签0或者1,进行匹配,所以标签不需要one-hot,dense层不需要TimeDistributed如中文分