
写文章




- @pony8181
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
你真的会写论文的“创新之处”吗?论文创新点撰写的几大误区
你真的会写论文的“创新之处”吗?这是很多科研工作者经常自我反思的问题!学术论文“创新性”,犹如它的“心脏”,是论文它“活”着的灵魂,它到底有多重要,每个学术人心里都有一杆秤,把好自己的学术关卡,在这里笔者不再予以评价!

修复stata失效、过期问题
上市公司-各类专利增量和存量(1999-2021年)
如何描述实证结果的经济显著性?
在报告实证回归结果时,我们不仅要关注统计上的显著性,还要关注实证结果是否具有经济显著性,在文献中有常见的有两种描述经济显著性的方法。

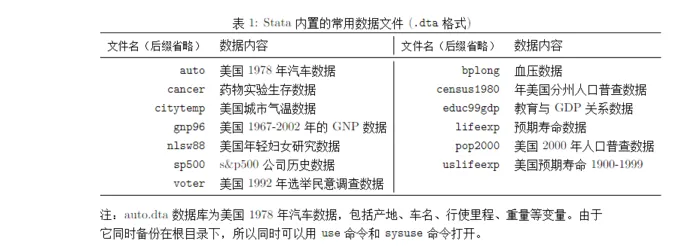
Stata小白系列之一:调入数据
Stata小白系列之一:调入数据
实证分析中经常遇到样本缺失值处理疑虑,一旦处理不当会导致分析结果不显著,你真的操作对了吗?
我在数据清理与探索性分析中遇到的最常见问题之一就是处理缺失数据。首先我们需要明白的是,没有任何方法能够完美解决这个问题。不同问题有不同的数据插补方法——时间序列分析,机器学习,回归模型等等,很难提供通用解决方案。在这篇文章中,我将试着总结最常用的方法,并寻找一个结构化的解决方法。
Stata小白系列之一:调入数据
Stata小白系列之一:调入数据
到底了