写文章
登录
写文章
开直播
登录社区云
登录社区云,与社区用户共同成长
CSDN账号登录
邀请您加入社区
立即加入
欢迎加入社区
@ouyang111222
Kevin.Yang
关注
2023-01-10 17:39:28 加入 DevPress
抖音号:
简介
该用户还未填写简介
擅长的技术栈
未填写擅长的技术栈
可提供的服务
暂无可提供的服务
文章列表
讨论/问答
关注
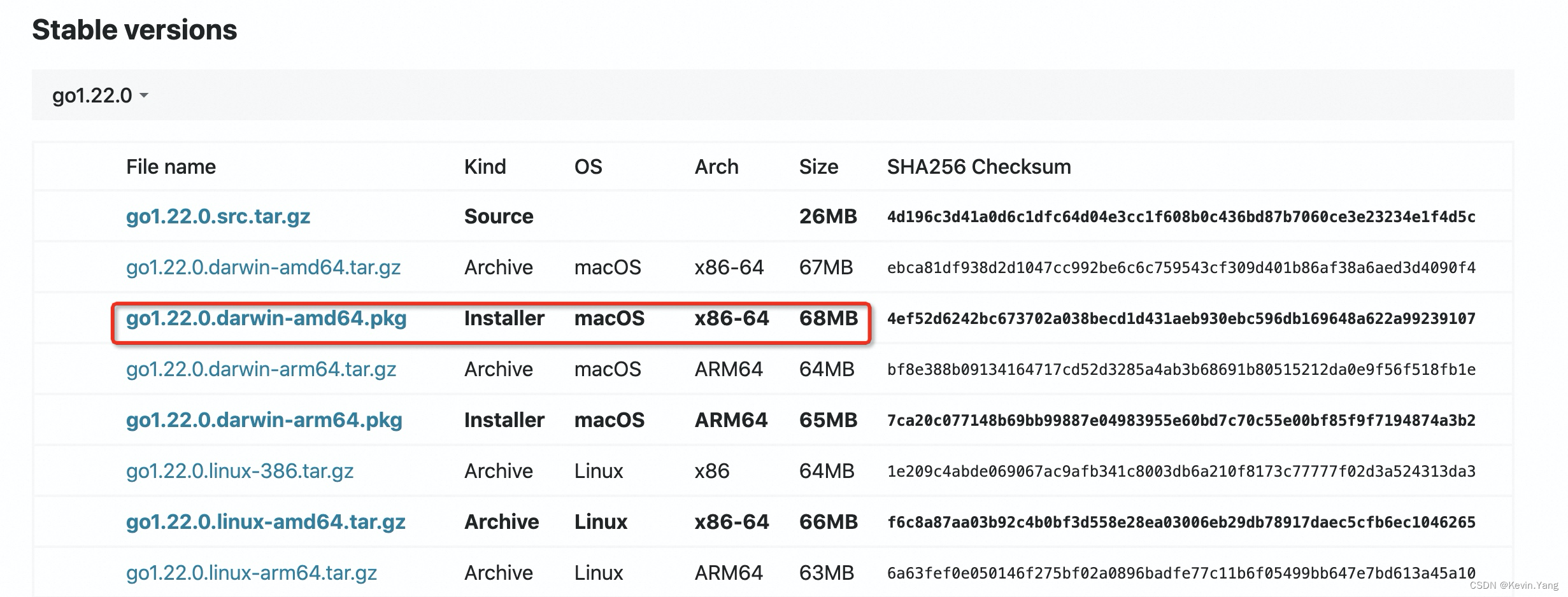
使用IDEA配置GO的开发环境备忘录
IDEA配置GO的开发环境
#golang
#开发语言
#后端
+1
使用IDEA配置GO的开发环境备忘录
IDEA配置GO的开发环境
#golang
#开发语言
#后端
+1
到底了