




- @neve_give_up_dan
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
匹配开头,替换一整行change = [1.0, 2.0, 3.0]# 替换后的字符串change_str = "objectStorage_fileStorage_coefficient = {}".format(change[0])# sed -i 插入修改, /^匹配头, 然后 /c替换后的串cmd = r"sed -i '/^objectStorage_fileStorage_coeffi
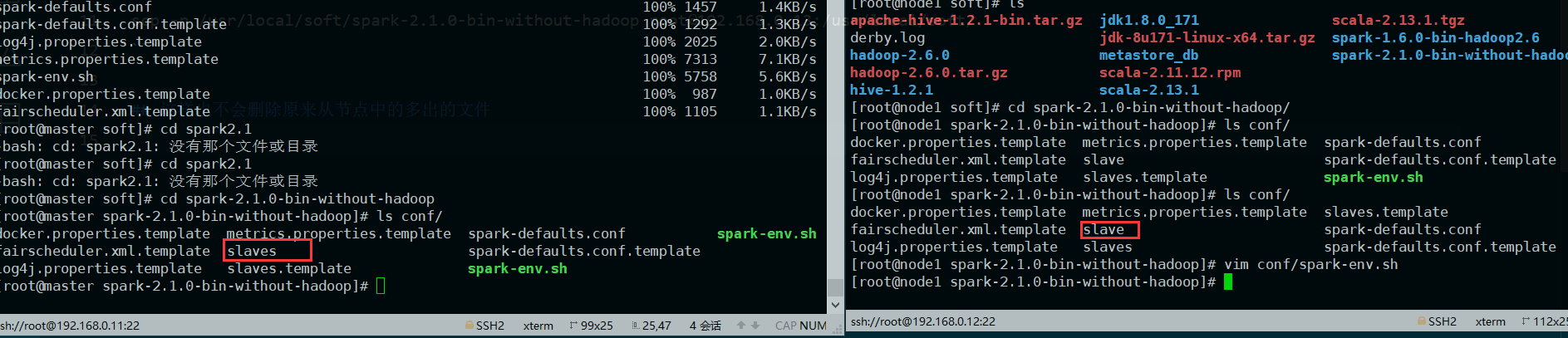
失败源Spark的版本名称中的“without Hadoop”具有误导性:这意味着该版本不与特定的Hadoop发行版绑定,并不意味着没有hadoop即可运行:用户应指出在哪里可以找到Hadoop我看到的教程中都是在$SPARK_HOME/conf/spark-env.sh,添加下列行(这下面更具有误导性,也可能是我太笨了,2020春节期间困扰了我好几天)# 编辑spark-env.sh文件(...
枚举类如果是枚举类型,那很简单#!/bin/python3# coding: utf-8from enum import Enumclass Color(Enum):# 为序列值指定value值red = 1green = 2blue = 3red = 1print(red in Color)# Falsetest_color = Color.redprint(test_color in Colo
最近发现自己一段时间提交的代码,都没有归类到github activity上,也没有在contribute图上显示,所以想搞清楚。自己是以前用的qq号的邮箱,后面用的qq邮箱的全英文的邮箱,所以把github主邮箱改了一下。
学习此资料指南不用看各种头文件先从test::run2()极其前后注释看起然后如果想要深入学习,可以看test::run()中的Variadic_template实现递归复合的sizeof()求解,太细的东西暂时看不懂没关系,其实只用看数据,他就相当于run2()中的struct嵌套struct#include<bits/stdc++.h>using namespace ...
# scp错误方式一(会导致src的opt复制到dst的/opt下,变成/opt/opt): scp -r /opt root@du22:/opt# scp错误方式二(scp不会覆盖子文件): scp -r /opt/bin /opt/include /opt/lib root@du22:/opt# 正确方式如下(覆盖子文件,但是文件夹日期不变):scp -r /opt/bin /opt/incl
测试环境说明MacBook Pro 2020,512G版雷电三转接USB3.0接三星SSD evo860, sata版接到硬盘盒AmorphousDiskMark测试工具465G的evo860,有250G是NTFS,使用量75%,通过NTFStool挂载剩下的215G格式化成exfat和HFS+分别测试,使用量0%由于无法格式化成APFS,所以显示一下MBP主机的APFS测试,仅供参考测试开始NT
Go 语言自带套件为我们提供了静态代码分析工具 vet,它能用于检查 go 项目中可以通过编译但仍可能存在错误的代码。在维基百科是如下定义 lint 的:但是如果想要更多,就可以用golangci-lint。golangci-lint 是一个 linter 的集成框架。它集成了非常多的 linter,包括了上文提到的vet,合理使用它可以帮助我们更全面地分析与检查 Go 代码VScode配置gol
VM虚拟机大家都用,我在用完后,经常使用“挂起客户机”,但是这样一来,系统恢复启动很快,但是少了正常的系统自检,包括和网络同步时间。今天在虚拟机上测试“find /root/Text -mtime +3 -name “Service.log.*” -exec rm -f {} ;”,总是不成功,反复看了几遍,也对照网上格式,命令没写错,结果无意中发现系统时间是上次“挂起”的时间。为了时间准确,..
确保VMware_tools安装在了虚拟机中重启一遍虚拟机