- @m0_75273286
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
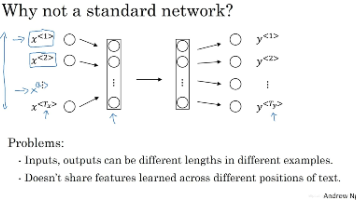
本文介绍了人脸识别技术中的关键方法与应用。首先区分了人脸验证(一对一比对)和人脸识别(一对多匹配)的不同需求,指出后者对准确率要求更高。针对数据量少的问题,提出了一次学习方案,通过Similarity函数比较图像差异。重点阐述了Siamese网络架构,它使用相同参数的CNN处理两张输入图像,计算编码距离。为优化特征提取,详细说明三元组损失函数的设计原理,通过anchor-positive-nega

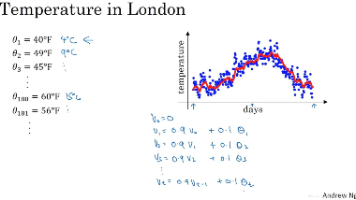
本文介绍了指数加权平均的原理与应用。首先通过伦敦气温数据示例展示了不同β值(0.9、0.98、0.5)对移动平均曲线的影响,β值越大曲线越平滑但延迟越明显。其次解析了指数加权平均的计算公式特点,指出其内存占用少、计算效率高的优势。最后说明了偏差修正的必要性,通过vt/(1-β^t)公式可有效修正初期计算偏差,随着天数增加修正效果逐渐减弱。该方法在数据处理中具有存储高效、计算简便的特点,特别适合需要
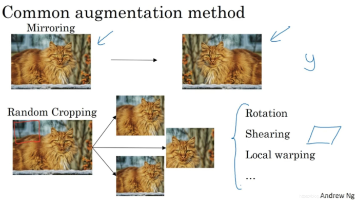
摘要:本文介绍了计算机视觉中迁移学习和数据增强的应用方法。在迁移学习部分,以猫检测器为例,展示了如何利用预训练网络权重进行模型初始化,并根据数据量大小选择冻结不同层数进行训练的策略。数据增强部分则讨论了镜像对称、随机裁剪、旋转和颜色转换等方法来扩充有限数据集,提高模型训练效果。文章强调应根据实际数据量灵活调整训练策略,在数据不足时充分利用预训练模型和数据增强技术来提升模型性能。
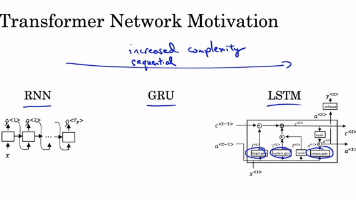
本文摘要:Transformer网络通过自注意力和多头注意力机制实现并行序列处理,突破了RNN的顺序计算限制。自注意力通过查询、键、值三向量计算上下文相关表示,多头注意力则并行执行多组自注意力运算。完整Transformer包含编码器(特征提取)和解码器(序列生成)模块,采用残差连接和层归一化解决深层网络训练难题。这种架构结合了注意力机制的上下文建模能力和前馈神经网络的非线性特征变换,在NLP领域
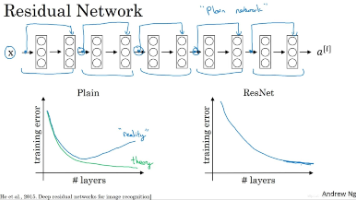
残差网络(ResNet)通过引入残差块和跳跃连接解决了深度神经网络的退化问题。其核心结构让网络可以直接学习输入输出间的残差,而非直接拟合目标映射。跳跃连接将浅层信息传递至深层,形成恒等映射关系,既保持了网络表达能力,又缓解了梯度消失/爆炸问题。实验证明,这种结构使极深网络(如100层)仍能有效训练并保持良好性能。残差网络的反向传播机制中,梯度通过主路径和跳跃连接同时传递,确保浅层能稳定接收深层梯度
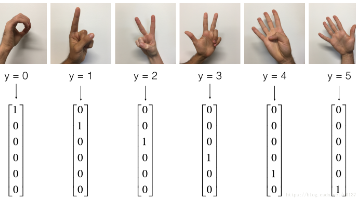
本文介绍了TensorFlow深度学习框架的基本使用方法。主要内容包括:(1)TensorFlow框架概述,说明其可简化神经网络实现过程;(2)基础示例展示如何定义变量、损失函数及训练过程;(3)语法要点如占位符和独热编码的使用;(4)详细的手势图片分类训练示例,涵盖参数初始化、正向传播、成本计算等完整流程,并给出了训练集和测试集的准确率评估方法。通过具体代码示例演示了TensorFlow实现深度
【代码】二层神经网络 (笔记) (吴恩达深度学习)
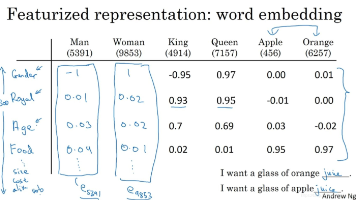
本文介绍了词表示与词嵌入的核心概念。首先指出one-hot向量无法表达词间相似性,提出采用特征化表示方法(如300维词向量)来捕捉词语的性别、高贵程度等语义特征。重点阐述了词嵌入的应用:通过t-SNE算法实现高维词向量的可视化呈现;支持迁移学习,可将预训练词向量应用于新任务;特别展示了词嵌入实现类比推理的原理,即通过向量减法(如e_man-e_woman≈e_king-e_queen)和余弦相似度
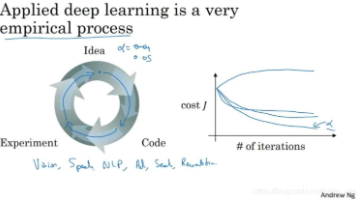
本文概述了深度学习中参数与超参数的区别,列举了常见的超参数类型,包括学习率、网络结构、优化算法等配置参数。指出深度学习是一个高度实验驱动的迭代过程,需要不断调整参数优化模型性能。由于不同领域问题特性差异以及硬件技术持续进步,最优参数配置会随时间和应用场景而变化,无法一劳永逸地确定。这种实验性特征要求开发者保持持续的调参和优化工作。
介绍循环神经网络RNN,包括基础的符号表示,正向传播与反向传播过程。RNN中的梯度消失导致的长期记忆效果不佳。门控循环单元(GRU)和LSTM的使用