- @m0_75011295
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
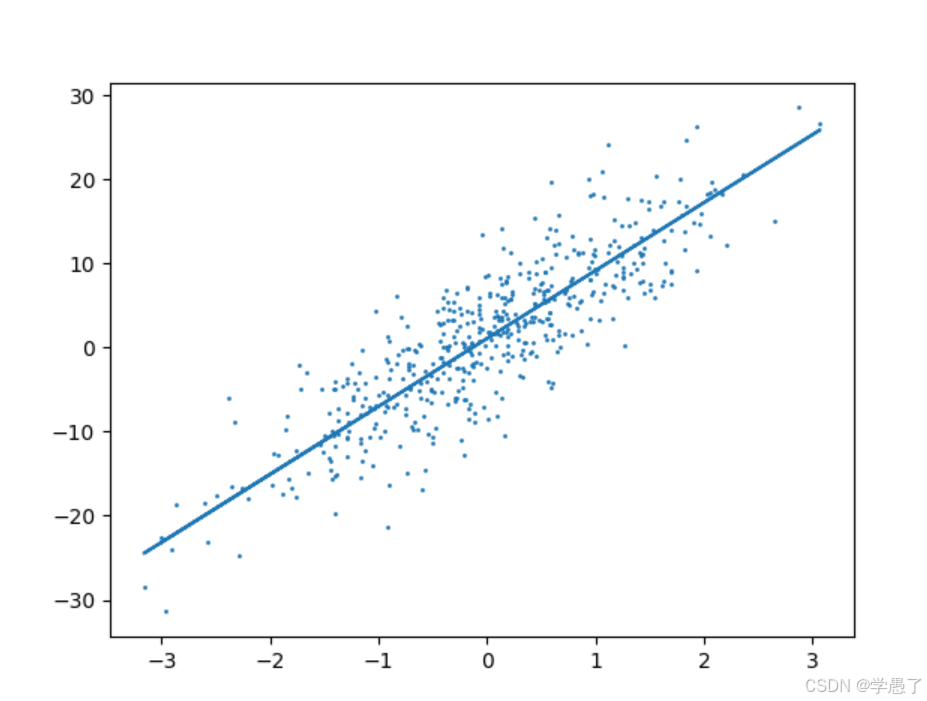
通过sklearn中的波士顿房价数据,实现对于数据读取、数据处理、模型训练,从而加强对于线性回归的认识。通过波士顿房价预测案例,学习了线性回归相关API的调用,加强了对于线性回归的认识。
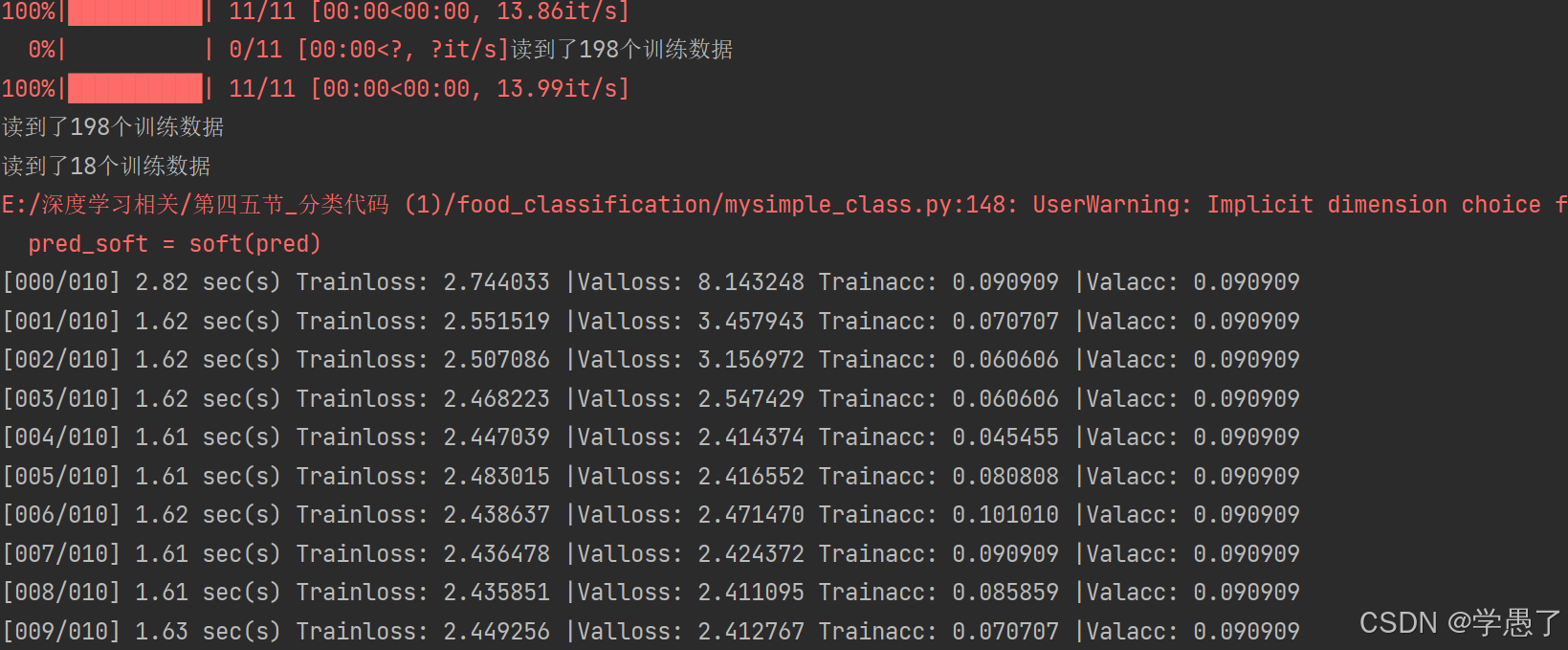
有11类食物,其中带标签的有28011张,无标签输出有6786张,验证集3011张,测试集有3347张。带标签的数据训练为监督学习,不带标签的数据训练为半监督学习。由上文可以训练出一个模型,用于食物分类。对于无标签的数据,可以待模型输入数据X,得到输出值predY概率超过0.99时,就将此数据打上此时的标签Y,并用作训练集。
加强了对于对于聚类算法评价指标的练习。
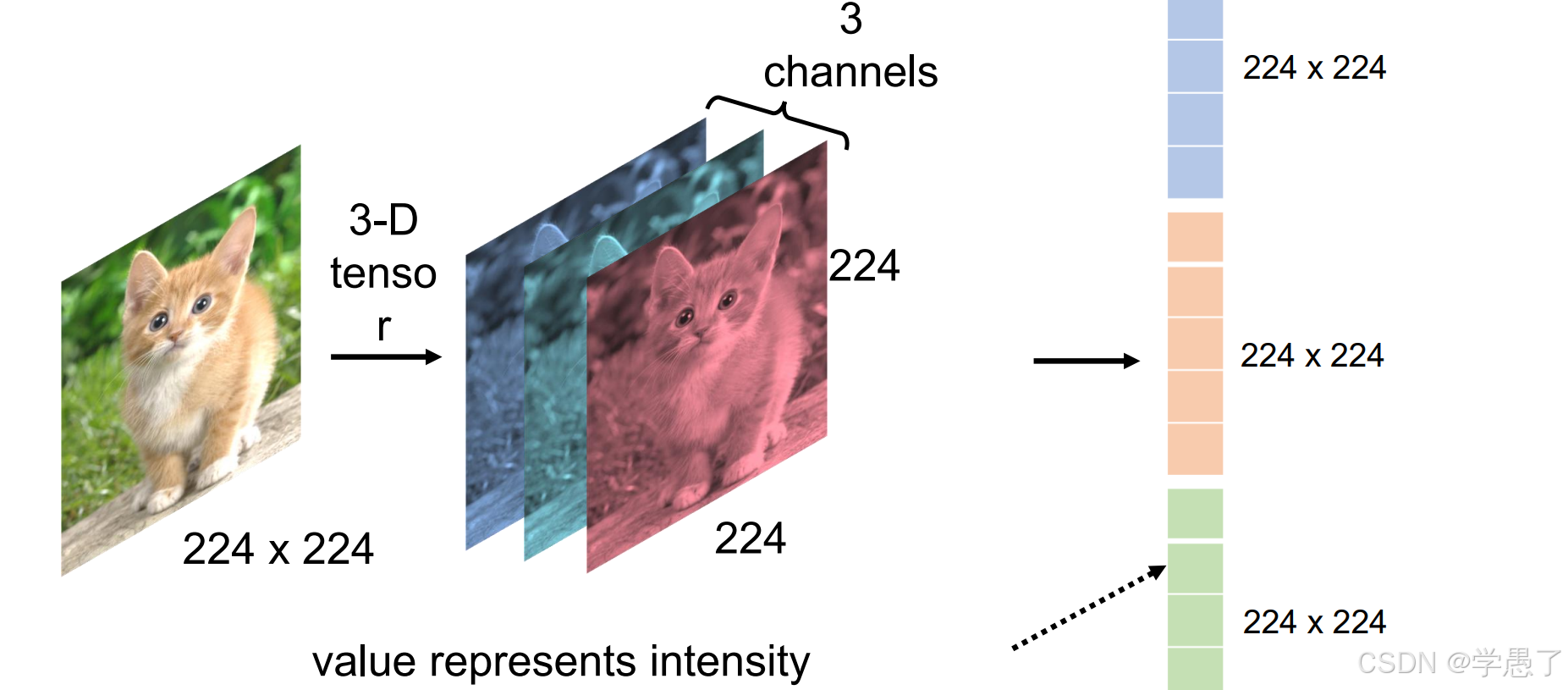
【前向过程】首先输入图片,然后经过若干次卷积得到特征,最后拉直,经过全连接求出预测值,有了预测值与真实值就可以算出loss。【反向过程】梯度回传,得到每一个卷积核上每一个权重的梯度,更新模型。
美国有40个州, 这四十个州呢 ,统计了连续三天的新冠阳性人数,和每天的一些社会特征,比如带口罩情况, 居家办公情况等等。现在有一群人比较坏,把第三天的数据遮住了,我们就要用前两天的情况以及第三天的特征,来预测第三天的阳性人数。但幸好的是,我们还是有一些数据可以作为参考的,就是我们的训练集。用训练集训练模型并且由训练的模型预测第三天阳性人数。本项目在最基础的回归模型上,增加了正则化和相关系数两种优

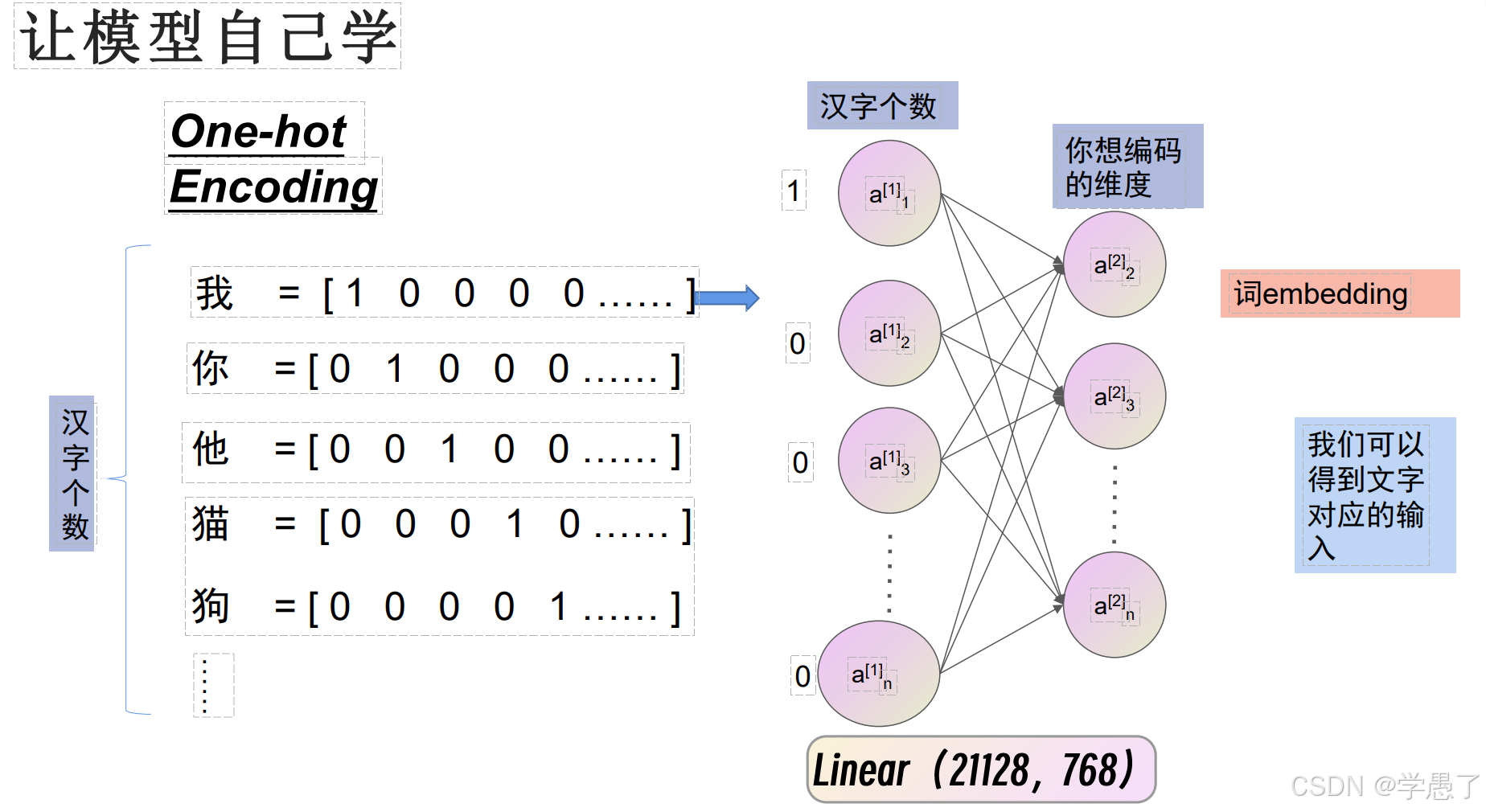
bert就是一个特征提取器,他就是预训练模型,我们可以通过迁移学习,将bert拿来训练自己想要的模型。
【前向过程】首先输入图片,然后经过若干次卷积得到特征,最后拉直,经过全连接求出预测值,有了预测值与真实值就可以算出loss。【反向过程】梯度回传,得到每一个卷积核上每一个权重的梯度,更新模型。
【前向过程】首先输入图片,然后经过若干次卷积得到特征,最后拉直,经过全连接求出预测值,有了预测值与真实值就可以算出loss。【反向过程】梯度回传,得到每一个卷积核上每一个权重的梯度,更新模型。
假设影响一个人恋爱次数的因素有:X1外貌,X2性格,X3财富,X4内涵其中每个因素所占权值不同,分别为:W1, W2,W3 ,W4偏差为b模型可以看作是y = wi * xi + b (i = 1、2、3、4)也就是现给出一批输出X1,X2,X3,X4和y1,y2,y3,y4推测出真实的权值w1,w2,w3,w4以及偏差b。