- @m0_74462934
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
本文介绍了一种基于NLP技术的MedSEBA系统,旨在解决医学信息检索中的立场识别问题。该系统通过PubMed检索相关文献,利用大型语言模型(GPT-4o)生成结构化答案,包括核心论据、立场标签和时间轴可视化。相比传统检索工具,MedSEBA能评估研究对特定医学问题的支持程度,并整合分歧结论。系统采用向量相似度重排序文献,并通过元数据分析提高结果可靠性。尽管存在摘要完整性等局限,但该系统为医学研究

本文介绍了一种分步式医学事实核查系统,该系统通过大型语言模型(LLM)迭代生成问题、收集证据并验证医学主张的真实性。研究比较了传统三阶段流程(文档检索、证据提取、判决预测)与新型分步式方法在三个医学数据集(SCIFACT、HEALTHFC、COVERT)上的表现。结果显示,分步式系统显著提升了F1分数(最高提升5.2),特别是在处理复杂医学概念时优势明显。研究还探讨了内部/外部知识源、谓词逻辑推理

本文探讨了检索增强生成(RAG)系统中上下文规模、模型选择和检索策略对性能的影响。研究发现:1)随着上下文片段数量增加(1-15个),系统性能稳步提升,但超过20-30个时会出现饱和或下降;2)不同LLM在不同领域表现各异,Mistral和Qwen在生物医学任务表现突出,GPT和Llama在百科全书任务更优;3)开放检索场景极具挑战性,BM25检索器表现优于语义检索。实验采用BioASQ-QA和Q

本文介绍了强化学习中的核心概念——贝尔曼方程(Bellman Equation),它通过递归方式将当前状态的价值表示为即时奖励与未来折扣回报之和。文章首先阐述了从回报到价值的思考过程,引出状态值函数V(s)和状态-动作值函数Q(s,a),进而详细解释了贝尔曼方程的数学形式及其含义。通过火星探测车的具体实例,展示了如何利用折扣因子γ计算Q值,验证了贝尔曼方程的递归本质。文章强调贝尔曼方程是强化学习的
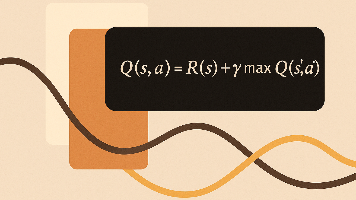
本文介绍了深度学习中的计算图概念及其在反向传播中的应用。计算图通过节点和边将数学运算可视化,其中前向传播计算输出结果,反向传播则通过局部梯度和链式法则传递梯度。文章通过具体数值案例展示了梯度计算过程,并强调统一反向传播的高效性。最后指出现代深度学习框架通过自动微分简化了开发,同时建议使用数值梯度检查验证自定义算子实现。更多计算机知识可访问博客网站rn.berlinlian.cn。
本文介绍了自然语言处理中两种主流句法分析方法:成分句法分析和依存句法分析。成分句法分析通过嵌套结构组织词语,而依存句法分析则直接描述词间二元关系。文章详细阐述了依存句法的形式化定义、约束条件和关系类型标注,并探讨了如何利用依存结构消除句法歧义(如介词短语附件歧义和协调范围歧义)以及提取语义信息。最后介绍了从传统转移算法到神经网络解析器的技术演进,以及评价解析器的UAS和LAS指标。文章来自作者博客
本文探讨了NLP分类任务的核心挑战与解决方案。文章首先分析语言的离散符号特性与连续语义之间的矛盾,介绍了从独热编码到分布式表示的演进过程。针对多义词处理难题,提出了线性叠加假说和多原型模型两种解决方案。随后详细阐述了从逻辑回归到深层感知器的分类器演进,包括神经单元、多层架构和目标函数的设计原理。最后以命名实体识别(NER)任务为例,展示了深度神经网络如何通过上下文窗口和特征拼接解决多义性问题。文章

本文介绍了双向循环神经网络(Bi-RNN)在自然语言处理中的应用。文章通过情感分析案例展示了单向RNN的局限性,即无法利用右侧上下文信息准确理解词义。Bi-RNN通过前向和后向两个独立的RNN层,分别捕获历史信息和未来信息,并通过拼接隐状态实现上下文感知。这种架构显著提升了模型对长难句和复杂语义的理解能力,但不适用于需要预测未来的任务如语言模型。文章还指出Bi-RNN的思想为后来的BERT等模型奠
本文介绍了强化学习中的核心概念——贝尔曼方程(Bellman Equation),它通过递归方式将当前状态的价值表示为即时奖励与未来折扣回报之和。文章首先阐述了从回报到价值的思考过程,引出状态值函数V(s)和状态-动作值函数Q(s,a),进而详细解释了贝尔曼方程的数学形式及其含义。通过火星探测车的具体实例,展示了如何利用折扣因子γ计算Q值,验证了贝尔曼方程的递归本质。文章强调贝尔曼方程是强化学习的
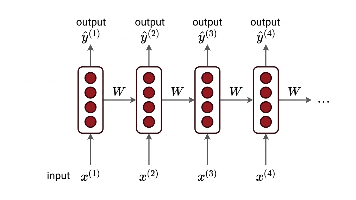
本文介绍了循环神经网络(RNN)的核心架构及其在自然语言处理中的应用。首先分析了传统神经网络在处理序列数据时的局限性,然后详细阐述了RNN的权值共享机制和隐藏状态的核心计算公式。文章重点讲解了如何构建RNN语言模型,包括词嵌入、隐藏状态更新和预测输出分布等关键环节。同时介绍了训练RNN时使用的交叉熵损失函数和Teacher Forcing策略,以及随时间反向传播(BPTT)算法的实现原理和优化技巧