- @m0_73716246
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
因为 matplotlib 的功能实在过于强大,甚至可以自定义一套属于自己的绘图风格,所以在了解其一些基本概念后决定从实际需求出发来熟悉这个库。
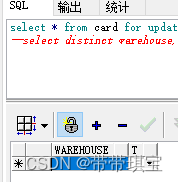
点击表头全选(导入某列),或者前面的*号(导入所有),CTRL+C、CTRL+V即可将表格的数据粘贴过来,:这种方法简单粗暴,数据量不大的时候非常方便,但是速度似乎不是很快,这词只是导了数千条数据,在数据量巨大的时候可能比较慢。今天需要进行一个数据处理,用 excel 不太方便,就顺便记录了将表导入 oracle 的方法。
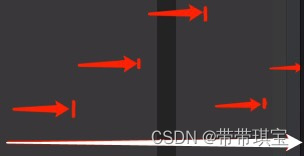
如 time.sleep() 时,操作如 input() 用户输入前,requests.get()等待请求返回数据前,程序也会处于阻塞状态,一般情况下,当程序处于IO操作时,线程都会处于阻塞状态,CPU是不在此工作的。协程:如上图,白色为时间轴,当程序遇见IO操作的时候,可以选择性地切换到其他任务上(类似if-else),以这种形式提高CPU利用率,宏观上看就是多个任务一起执行(多任务异步操作)先
线性说白了就是初中的一次函数的一种应用,根据不同的(x,y)拟合出一条直线以预测,从而解决各种分类或回归问题,假设有 n 个属性(自变量),xi 为 x 在第 i 个属性上的取值,则其形式为:模型有系数、、...以及误差项 ,可写为:线性回归拟合有一些重要的假设,包括:拿一元线性回归举例(一个自变量一个因变量):机器学习过程中我们的目标是最小化残差平方和来估计模型系数的值,均方误差对应了常用的“欧
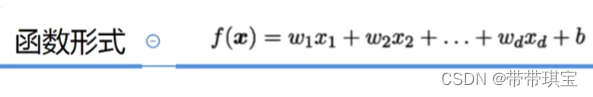
若检测到载体身份标识为某款浏览器,说明该请求是个正常请求。若不是,则表示该请求为不正常的请求(即爬虫,请求载体要么是基于浏览器要么是基于爬虫),服务器可能会拒绝该次请求。正因为服务器可能会拒绝请求,所以在第2步发起请求时,将请求头信息伪装为 header,再进行 get() 请求。打开网页按F12,Ctrl+R,点击网络,请求标头中有个User-Agent,表示请求载体的身份标识。打开一个网页,利

如前面的示例所示。选取某一区域时,先行后列,以下有几种访问方法。

在学习 UA 伪装过后,我仍只知道如何通过 Python 爬虫访问某个网页,但如果我想获取百度翻译网站上某些具体内容又该如何操作呢?先打开百度翻译页面,只有某一块这才是我想要的内容,我想通过输入单词获得对应的翻译结果,该怎么做呢观察发现,在输入cat之后,URL 最后结尾会多一个 cat 单词,而当前页面会进行一个局部的刷新:打开抓包工具定位 Network 中的 XHR选项卡当中,这里有 Aja
A B v1 v2# 内连接print(df3)解析:on=['A','B'] 即将 A、B 列作为连接键,当这个组合键相同时,进行连接,上面的 df1 和 df2 只有索引为2的一行数据是相同的,为 [B,b],因此,在有多列时,需要满足这几列都相同的数据才会进行连接此外,由于merge需指定连接的列,在两个 df没有相同列需要用到索引时(见下方基于索引),应指定left_on、right_on

格式化的符号>