




- @m0_73553411
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
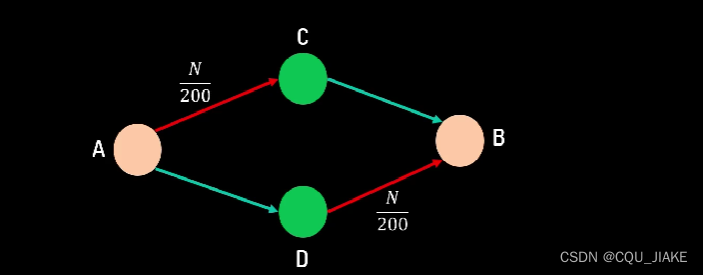
红色的是普通道路,车越多通行时间越长假定条件是均衡状态就是两条路的通行时间相同纳什均衡并不一定是全局最优纳什均衡的关键就是单个个体做出改变时,只会使自己的利益受到损失,而不会使其他人发生改变在达到纳什平衡时,是每个个体都遵循使自己利益最大化的方式。
首先在vscode上是需要的,Pycharm的终端也是,不过Pycharm已经把导包这种做了更方便的处理,所以转到VSCode上后容易被遗漏先运行如下python代码,查找当前vscode检测到的解释器路径,如果发现有虚拟venv的就继续下一步另:这一步可以导入sys包是因为这个sys是py解释器自带的,不需要任何第三方库运行Activate脚本,发现出现如下信息。
红色的是普通道路,车越多通行时间越长假定条件是均衡状态就是两条路的通行时间相同纳什均衡并不一定是全局最优纳什均衡的关键就是单个个体做出改变时,只会使自己的利益受到损失,而不会使其他人发生改变在达到纳什平衡时,是每个个体都遵循使自己利益最大化的方式。
首先在vscode上是需要的,Pycharm的终端也是,不过Pycharm已经把导包这种做了更方便的处理,所以转到VSCode上后容易被遗漏先运行如下python代码,查找当前vscode检测到的解释器路径,如果发现有虚拟venv的就继续下一步另:这一步可以导入sys包是因为这个sys是py解释器自带的,不需要任何第三方库运行Activate脚本,发现出现如下信息。
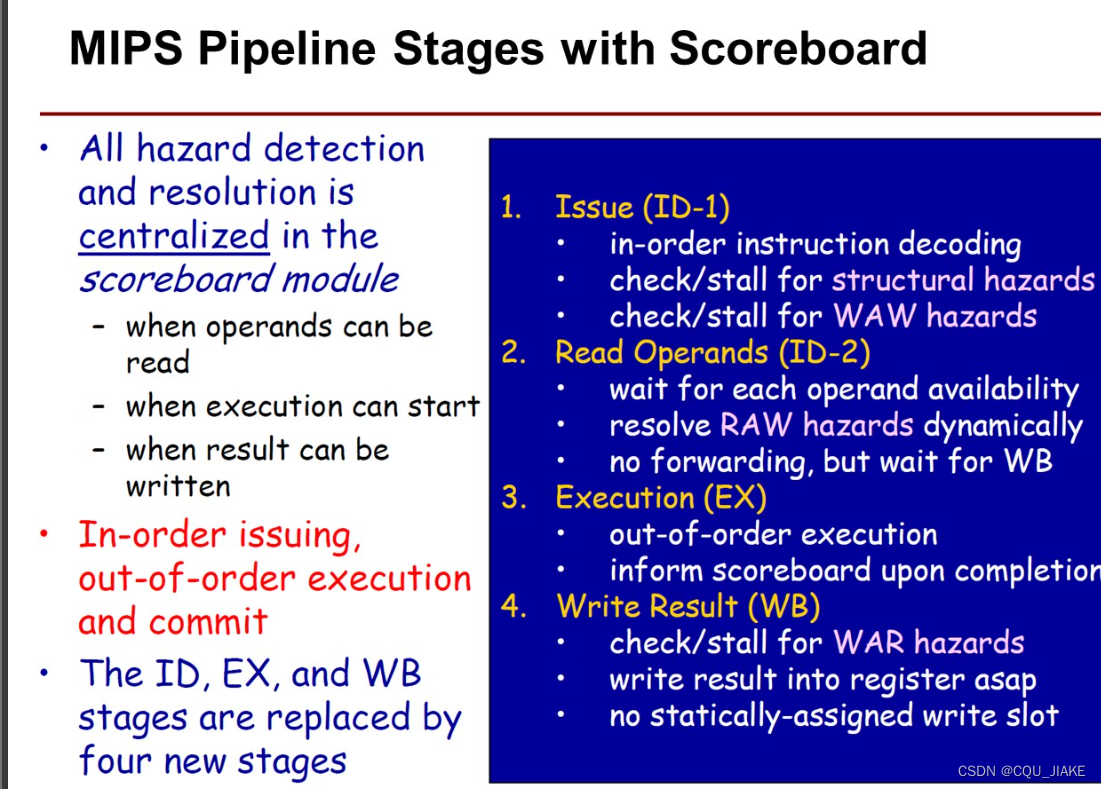
(在乱序执行过程中,记分牌规定每一条配置路线都只能同时存在一条指令),即图中所列的“ Limited waiting space at functional units ”,如果后续相同类型的指令没法发射,那么更后面的也许可以立马执行的指令也会被阻塞到,这对性能有很大的影响。第一个周期,记分牌是空的,功能部件也都是空闲的,度过发射阶段,,在周期结束是更新记分牌。指令寄存器只有一个,所以发射阶段因为
【计算机体系结构问题摘要】 CPU类型:TIMING是基础时序模型,O3(Out-of-Order)支持乱序执行,通过重排序缓冲区提升IPC,但硬件开销大。 NUMA系统:非统一内存访问架构,节点本地/远程内存延迟差异显著,需软件优化数据局部性。 内存异构性:同构内存(如DDR)限制能效比,异构(HBM+DRAM)可匹配不同带宽/容量需求,但管理复杂度高。 CXL技术:通过PCIe协议实现内存池化
对于选择连接顺序的优化,目的就是让中间结果的元组数最少在连接课程的时候,先对课程在所需要的属性上进行了一次投影,就是投影下移连接时可以系和老师连,但是不能系和课程连,因为连接必须要有相同属性2009有课,音乐系,名字,教授课程名涉及三个表的连接,即系表,老师表,课程表投影到名字,课程名称范围为2009有课,音乐系左树是三个表先进行自然连接,然后做选择,再投影右数是在连接前先选择,在老师表里是200

通过分析和比较这些超效率决策单元,可以了解到他们在哪些方面取得了卓越绩效,并通过学习他们的最佳实践来提高其他决策单元的效率。4. 分析相对效率的差异:对于相对效率较低的决策单元,分析其差异,并确定改进的潜力和策略。数据包络分析法可以用于评估各种类型的组织,如企业、学校、医院等,以及评估各种决策单元的效率,如生产单位、投资组合等。2. 识别超效率决策单元:检查相对效率值为1的决策单元,即超效率决策单

CQID : 命令队列ID, 这部分包含与请求相关的跟踪者ID, 当请求的响应和数据返回的时候,其中的 CQID 向设备表明哪一个请求的跟踪索引。(缓存一致性协议):使CPU与加速器(如GPU/FPGA)共享缓存行级数据,支持原子操作和细粒度同步,消除传统PCIe架构中数据复制的开销”详细解释一下PCle架构中数据复制的开销?NT :对于可缓存的读,这个区域被作为一个提示,用来向主机表示它应该如
透视投影是中心投影,模拟人眼或相机的成像原理,投影线从视点(相机位置)发散,物体投影后呈现近大远小效果,平行线可能交汇于消失点。
