- @m0_72829651
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
在典型的配置下(),运行一批数据时 BERT-Base 模型的显存占用大约为 3.2 GB。减小批量大小;使用混合精度训练(FP16);使用梯度累积;选择更小的模型;进行分布式训练。混合精度训练是一种简单而高效的显存优化方法,推荐在实际项目中使用。希望本文能帮助你更好地理解和优化 BERT-Base 模型的显存占用,提升模型训练的效率!Hugging Face Transformers 文档PyT

是两种最常用的抗过拟合技术,通过限制模型复杂度或引入随机性,显著提升模型的泛化能力。本文将详解它们的原理、实现方法及实战技巧。:在损失函数中添加权重绝对值之和(L1范数),迫使模型学习稀疏权重(部分权重为0),实现特征选择。:在损失函数中添加权重平方和(L2范数),使权重均匀小化,避免单个特征对预测过度影响。随机“关闭”神经元,迫使网络学习冗余特征,测试时恢复所有神经元并缩放输出。:结合L1的稀疏

的数量,使不同类别的样本分布更加均衡,从而提高模型对少数类的识别能力。是一个常见问题,即某些类别的样本数量远多于其他类别。:适用于文本数据,通过替换句子中的词语为同义词来生成新样本。:可能导致过拟合(模型记住重复样本,泛化能力下降)。:可能生成噪声样本(尤其在类别边界模糊时)。:数据分布复杂,少数类样本差异较大时。:简单复制少数类样本,直到类别平衡。:减少过拟合风险,生成多样化样本。:避免过拟合,

集成学习是机器学习中通过组合多个基学习器(弱学习器)来提升模型性能的核心思想。本文将系统梳理集成学习的核心算法,包括Bagging、Boosting、随机森林、AdaBoost、GBDT和XGBoost,结合数学公式与示例,帮助读者深入理解其原理与应用。

在人工智能领域,神经网络(Neural Networks, NN)是模仿人脑信息处理方式的核心技术。随着任务复杂度的提升,逐渐衍生出**循环神经网络(RNN)**神经网络(NN)**是一种由多层神经元组成的计算模型,通过非线性激活函数和权重调整实现复杂映射。卷积神经网络(CNN)**等变体。本文将从基础概念、架构设计到代码实现,深入解析这三种经典模型。为激活函数(如ReLU、Sigmoid)。:降

创建只是第一步,关键在于赋予灵魂。我们需要编辑每个智能体的(或agent.json中的字段),明确其职责。通过以上步骤,您成功构建了一个具备分工明确、自动协作、层级管理PM是大脑,负责统筹。是手脚,负责执行。Router是神经,负责传递信号。

OpenClaw(昵称“小龙虾”)是一款强大的本地优先 AI 智能体框架,能让 AI 真正操作您的电脑、文件和工具。本指南将带您通过两种主流方式完成部署,并配置核心功能。

数据集自定义类型二分类(正面/负面)样本量训练集 + 验证集 + 测试集文本长度平均x字(最大x字)领域商品评论、影视评论# 加载数据集# 输出:{'text': '这个手机性价比超高,拍照效果惊艳!

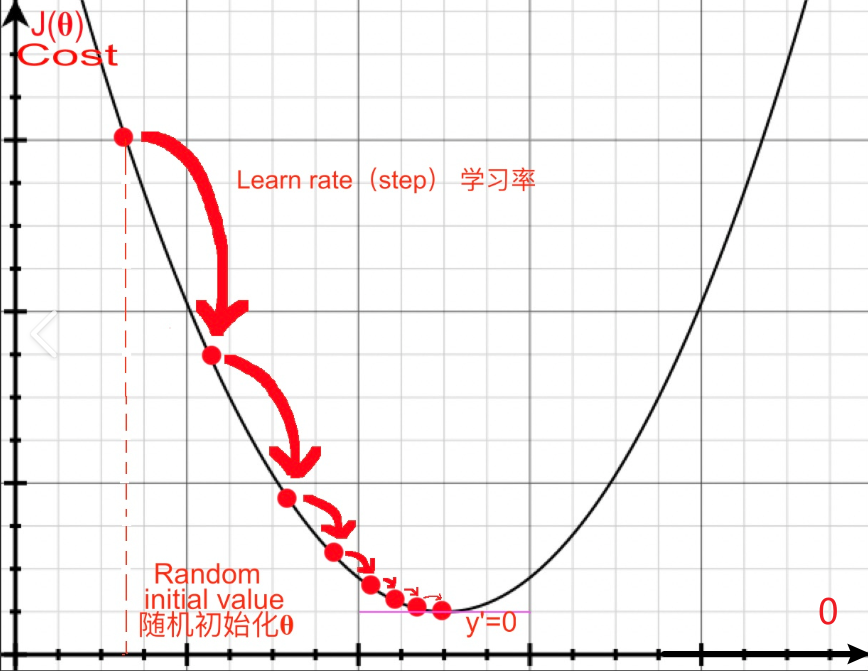
优化算法是深度学习的核心组成部分,用于最小化损失函数以更新神经网络的参数。本文将详细介绍深度学习中常用的优化算法,包括其概念、数学公式、代码示例、实际案例以及图解,帮助读者全面理解优化算法的原理与应用。优化算法是深度学习训练的基石,从简单的梯度下降到自适应的 Adam,每种算法都有其适用场景。Adam 通常比 SGD 收敛更快,损失下降更平稳,但在某些任务中 SGD 配合动量可能获得更好的泛化性能