- @m0_71417856
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
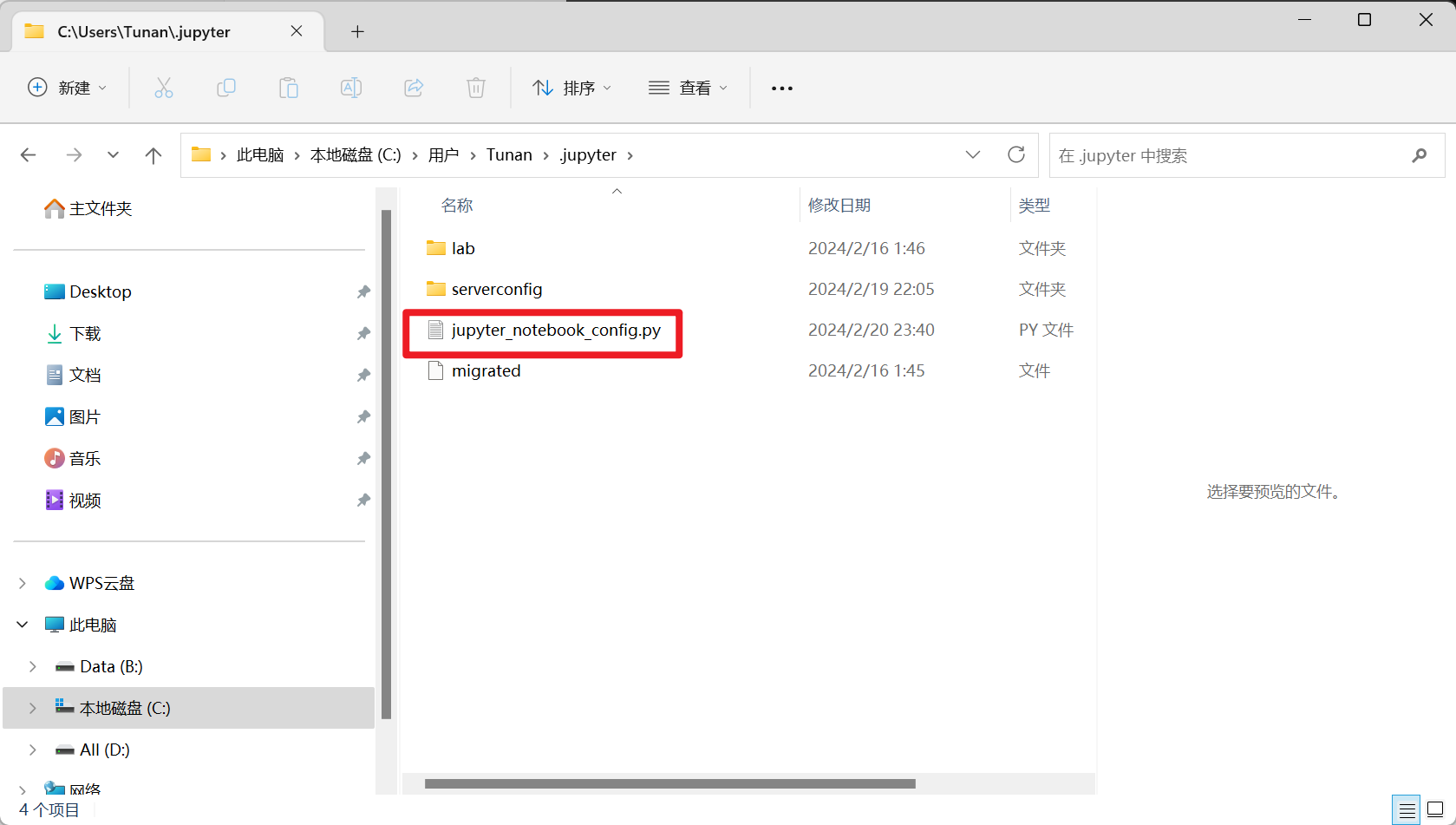
在使用 JupyterLab 或 Jupyter Notebook 进行数据分析、机器学习项目时,经常会遇到需要修改默认工作目录的需求。默认情况下,JupyterLab 和 Jupyter Notebook 会在启动时打开你的用户目录(例如,在Windows上是`C:\Users\用户名`,在Linux和macOS上是`/home/用户名`),但有时候我们希望能直接**在特定的项目目录下工作**,
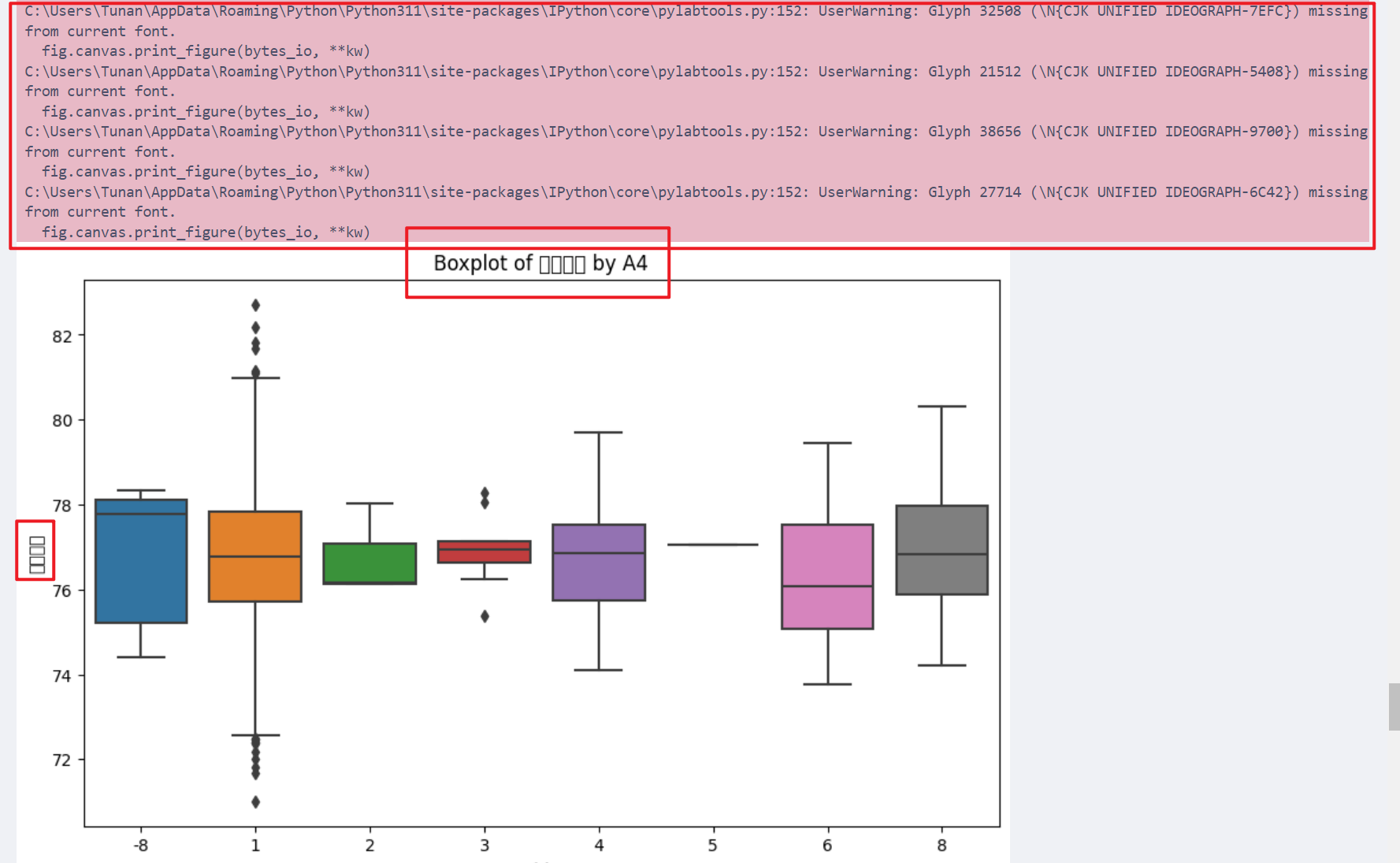
这个错误消息来自于使用 Python 的 IPython 环境,特别是在尝试输出图形时。能搜索的到,说明是有中文字体的,那只需要设置中文字体就好了,如果搜索不到,请到。到你的Pycharm或者Jupyter当中运行下面的代码。非常简单,但每次都需要这样做,适合紧急情况下来用。删除这里的注释,并且将true改为false。查看Matplotlib是否存在中文字体。去掉圈出来这两行的注释,并且修改第二
ACM 竞赛注意事项

Hash,一般翻译做散列、杂凑,或音译为哈希,是把任意长度的 输入 (又叫做预映射pre-image)通过散列算法变换成固定长度的 输出 ,该输出就是散列值。这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来确定唯一的输入值。(逆推是不行的啦就是说)
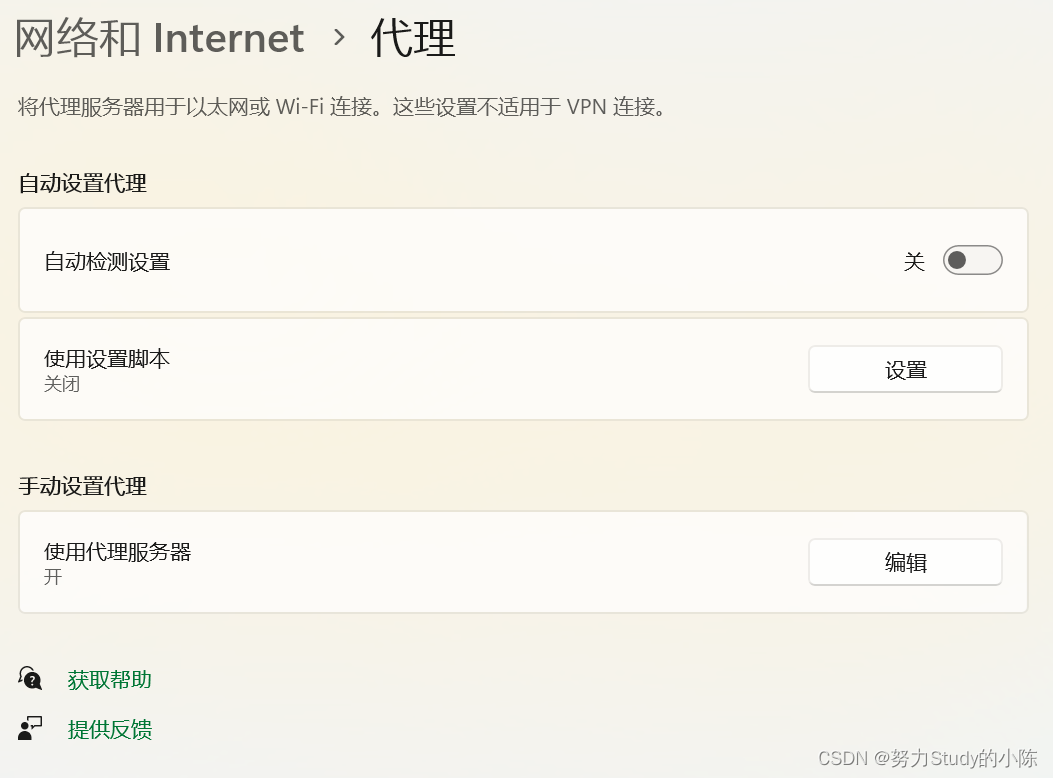
最近因为开了代理就会导致有些网站进不去,开了VPN之后代理又会莫名其妙打开这些问题很困惑,所以潜心研究了一下这些名词是什么意思,又有什么作用,该如何使用等等
本教程将指导您如何在GPU上运行TensorFlow模型,以加速您的机器学习或深度学习项目。我们将涵盖为什么使用GPU、必要的前置知识(如TensorFlow、CUDA、cuDNN等)、环境准备和安装步骤,以及如何在PyCharm和Jupyter等IDE中配置和使用TensorFlow。
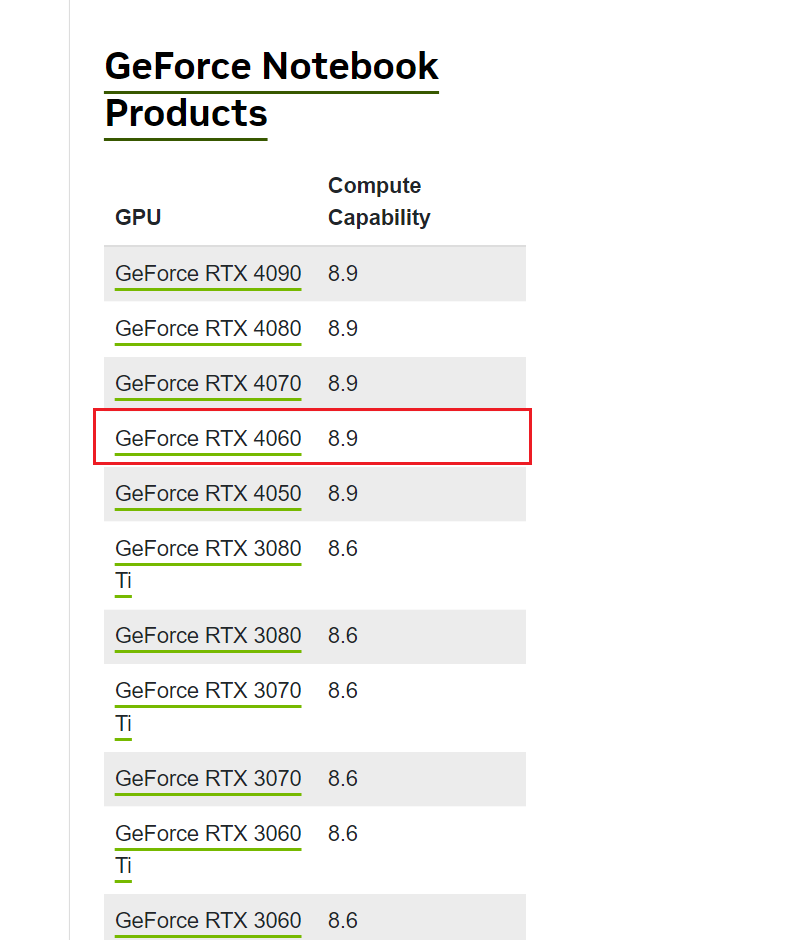
本教程将指导您如何在GPU上运行TensorFlow模型,以加速您的机器学习或深度学习项目。我们将涵盖为什么使用GPU、必要的前置知识(如TensorFlow、CUDA、cuDNN等)、环境准备和安装步骤,以及如何在PyCharm和Jupyter等IDE中配置和使用TensorFlow。
大数据(Big Data)是指规模巨大、类型多样、处理复杂的数据集合。这些数据集合通常包含了传统数据处理工具难以处理的数据类型,如非结构化数据、半结构化数据和结构化数据等。大数据的特点主要包括以下几个方面:大数据的出现主要是由于以下几个方面的原因:大数据技术主要包括数据采集、数据存储、数据处理和数据分析等方面。大数据技术的应用范围非常广泛,包括金融、医疗、电商、物流等多个领域。通过对大数据的处理和