- @m0_67549907
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
其原因是:带momentum的方法训练,可看作在参数值和momentum组成的二元组上,每步乘一个矩阵,然后加一个噪音。不发散,要求这个矩阵的特征值范数小于1.但是,可能有复特征值和复特征向量。所以,虽然系数在衰减,但复的部分可能被变换到实的部分来,就出现初期loss上升的情况,直到模最大的系数被衰减到1以下。综上,初期loss上升,不一定发散,是正常的。在不带momentum的情况下,一般不应该

其原因是:带momentum的方法训练,可看作在参数值和momentum组成的二元组上,每步乘一个矩阵,然后加一个噪音。不发散,要求这个矩阵的特征值范数小于1.但是,可能有复特征值和复特征向量。所以,虽然系数在衰减,但复的部分可能被变换到实的部分来,就出现初期loss上升的情况,直到模最大的系数被衰减到1以下。综上,初期loss上升,不一定发散,是正常的。在不带momentum的情况下,一般不应该
其原因是:带momentum的方法训练,可看作在参数值和momentum组成的二元组上,每步乘一个矩阵,然后加一个噪音。不发散,要求这个矩阵的特征值范数小于1.但是,可能有复特征值和复特征向量。所以,虽然系数在衰减,但复的部分可能被变换到实的部分来,就出现初期loss上升的情况,直到模最大的系数被衰减到1以下。综上,初期loss上升,不一定发散,是正常的。在不带momentum的情况下,一般不应该
输出当前的隐藏状态。通过一个全连接层和激活函数将隐藏状态转换为情感标签(积极)。具有循环连接,使得网络能够在处理当前输入时考虑先前的输入,从而捕捉序列中的时序信息。最终隐藏状态包含整个句子的综合信息,通过全连接层和激活函数判断情感。逐步读取每个单词向量,通过一个激活函数计算新的隐藏状态。词向量表示:每个单词通过词嵌入转换为向量表示,作为。词向量表示:每个单词通过词嵌入转换为向量表示,作为。输入门:

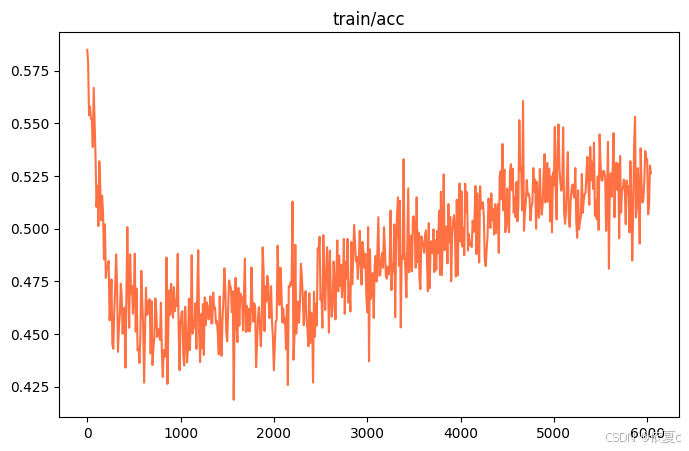
如图,在训练集上,train_acc出现剧烈抖动,原因是训练的batch_size太小。我这里的batch_size为1,如果调高一些,acc曲线图震荡的情况将会得到改善。
摘要:ChatDoctor是一款基于LLaMA-7B模型微调的医疗对话AI,通过整合10万条真实医患对话和外部医疗知识库,显著提升了医疗问答的准确性。实验显示,在精确率、召回率和F1分数上均优于ChatGPT,能有效处理新医疗主题并生成更接近医生回答的内容。该研究为医疗AI提供了新思路,但临床应用仍需进一步验证安全性。

本文提出Ask Patients with Patience(APP)医疗助手模型,旨在解决现有大语言模型在医疗对话中缺乏以患者为中心的交互和透明诊断依据的问题。APP基于权威医学指南和贝叶斯主动学习,通过多轮共情对话引导患者清晰表达症状,动态更新疾病概率分布以提升诊断准确性。实验表明,APP在诊断准确率、不确定性降低和人文关怀维度上显著优于现有模型,为AI医疗对话与临床应用搭建了桥梁。

本文提出FACT-AUDIT框架,通过多智能体协作动态评估大语言模型(LLMs)的事实核查能力。该框架采用原型模拟、事实验证与自适应更新三阶段流程,覆盖复杂声明、假新闻等场景,并引入IMR、JFR等指标。实验评估13个主流LLMs,结果显示GPT-4o和Qwen2-72B表现最优,但LLMs在复杂声明场景仍有明显不足。该框架突破了传统静态评估的局限,实现了对LLMs事实核查能力的全面审计。

本文提出Ask Patients with Patience(APP)医疗助手模型,旨在解决现有大语言模型在医疗对话中缺乏以患者为中心的交互和透明诊断依据的问题。APP基于权威医学指南和贝叶斯主动学习,通过多轮共情对话引导患者清晰表达症状,动态更新疾病概率分布以提升诊断准确性。实验表明,APP在诊断准确率、不确定性降低和人文关怀维度上显著优于现有模型,为AI医疗对话与临床应用搭建了桥梁。
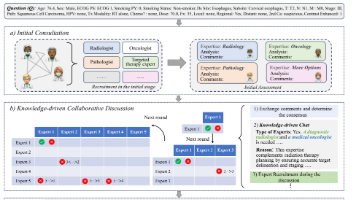
本文提出KAMAC(知识驱动的自适应多智能体协作框架),旨在解决现有大语言模型(LLMs)多智能体协作在医疗决策中存在的静态预分配角色局限,通过初始咨询、知识驱动协作讨论(动态检测知识缺口并招募专家)和最终决策三阶段,实现灵活可扩展的跨专科协作;