




- @m0_64336780
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
ChatGPT,即“Chat Generative Pre-trained Transformer”,是一种基于深度学习的自然语言处理模型,由OpenAI开发。这个模型的独特之处在于它的能力,可以生成自然、流畅的文本,仿佛是来自一个有思维的聊天伙伴。ChatGPT的工作原理基于Transformer架构,这是一种在自然语言处理领域取得巨大成功的架构。

《BrightData AIStudio在企业级金融舆情采集中的应用》摘要 本文介绍了BrightData AIStudio在企业级金融舆情采集中的创新应用。该平台通过AI驱动的爬虫生成、托管式云端运行环境、内置代理与自动解封机制等核心能力,有效解决了传统爬虫方案在金融舆情采集中的痛点。文章以东方财富股吧为例,详细演示了从数据目标设定到采集任务扩展的全流程,展示了AIStudio如何降低开发门槛和

本文介绍了GEO(生成式引擎优化)时代的品牌监测新方法,重点解析了BrightData的ChatGPT抓取工具在工业级稳定性、结构化数据获取、自动解封和批量处理方面的技术优势。通过对比亚迪品牌的实战演示,展示了如何利用Python脚本或无代码方式批量采集ChatGPT回复数据,并从中分析品牌在AI推荐中的定位、技术优势和短板。文章指出,在AI成为新流量入口的背景下,数据驱动的自动化监测将成为品牌优

本文介绍了GEO(生成式引擎优化)时代的品牌监测新方法,重点解析了BrightData的ChatGPT抓取工具在工业级稳定性、结构化数据获取、自动解封和批量处理方面的技术优势。通过对比亚迪品牌的实战演示,展示了如何利用Python脚本或无代码方式批量采集ChatGPT回复数据,并从中分析品牌在AI推荐中的定位、技术优势和短板。文章指出,在AI成为新流量入口的背景下,数据驱动的自动化监测将成为品牌优
本文介绍了GEO(生成式引擎优化)时代的品牌监测新方法,重点解析了BrightData的ChatGPT抓取工具在工业级稳定性、结构化数据获取、自动解封和批量处理方面的技术优势。通过对比亚迪品牌的实战演示,展示了如何利用Python脚本或无代码方式批量采集ChatGPT回复数据,并从中分析品牌在AI推荐中的定位、技术优势和短板。文章指出,在AI成为新流量入口的背景下,数据驱动的自动化监测将成为品牌优
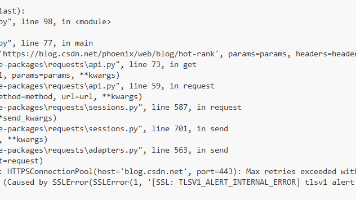
摘要:Python爬虫运行报错,经排查是因requests库版本过高导致不兼容问题。解决方案有两种:1)降级安装2.28版本(pip3 install "requests==2.28"),避免2.32+版本的SSL证书变更问题;2)参考官方文档进行版本迁移。建议开发者根据项目需求选择合适的解决方式。(94字)
Power BI是一款由Microsoft开发的商业智能工具,用于数据分析、数据可视化和数据驱动的决策支持。它可以将来自多个数据源的数据进行整合和转换,然后可视化呈现在交互式的仪表板和报告中,帮助用户深入了解他们的业务和数据趋势,从而做出更明智的决策。Power BI提供了一个强大的图形用户界面,使用户能够通过拖放和点击操作,轻松创建交互式的数据可视化和仪表板。它还提供了一系列先进的数据建模工具,

本书是一本全面介绍在PyTorch环境下学习机器学习和深度学习的综合指南,可以作为初学者的入门教程,也可以作为读者开发机器学习项目时的参考书。本书讲解清晰、示例生动,深入介绍了机器学习方法的基础知识,不仅提供了构建机器学习模型的说明,而且提供了构建机器学习模型和解决实际问题的基本准则。本书添加了基于PyTorch的深度学习内容,介绍了新版Scikit-Learn。本书涵盖了多种用于文本和图像分类的

ChatGPT,即“Chat Generative Pre-trained Transformer”,是一种基于深度学习的自然语言处理模型,由OpenAI开发。这个模型的独特之处在于它的能力,可以生成自然、流畅的文本,仿佛是来自一个有思维的聊天伙伴。ChatGPT的工作原理基于Transformer架构,这是一种在自然语言处理领域取得巨大成功的架构。
ChatGPT,即“Chat Generative Pre-trained Transformer”,是一种基于深度学习的自然语言处理模型,由OpenAI开发。这个模型的独特之处在于它的能力,可以生成自然、流畅的文本,仿佛是来自一个有思维的聊天伙伴。ChatGPT的工作原理基于Transformer架构,这是一种在自然语言处理领域取得巨大成功的架构。