




- @m0_62645012
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
如果你这部分有路径的报错,直接将这个war删除,重新引入。
导致这种现象的原因是因为web.xml的版本不对,比如Tomcat6是对应Serlvet2.5,而Tomcat5是对应Servlet2.4,而我项目是使用Tomcat6,打开web.xml后,发现使用的是2.4的版本信息。估计是我拷贝以前的web.xml,覆盖了新建项目时生成的web.xml,才导致这种现象。换成
1. **参数规模:** GPT-4o在参数规模上有所优化,尽管具体的参数数量可能不如GPT-4庞大,但它通过更高效的训练和模型架构优化,达到了与GPT-4相似甚至更好的性能。在讨论GPT-4o时,我们首先需要了解其前身,即GPT-4,以及其之前的版本。3. **训练数据:** GPT-4o可能利用了更新、更大规模的训练数据集,涵盖了更多的领域和语言,提高了模型的广泛性和准确性。1. 模型压缩和优

随着AI系统在日常生活中的广泛应用,人们对于这些系统的决策过程提出了更多的疑问。为了增强对AI系统的信任,科学家们努力推动可解释性AI(XAI)的研究,使人工智能的决策变得更为透明和可理解。在信用评分、投资决策等方面,可解释性AI能够提供清晰的决策过程,增加金融机构和用户之间的信任。在疾病诊断和治疗方面,可解释性AI可以帮助医生理解模型的决策,提高临床应用的可行性。可解释性AI在自动驾驶汽车中扮演


1. **参数规模:** GPT-4o在参数规模上有所优化,尽管具体的参数数量可能不如GPT-4庞大,但它通过更高效的训练和模型架构优化,达到了与GPT-4相似甚至更好的性能。在讨论GPT-4o时,我们首先需要了解其前身,即GPT-4,以及其之前的版本。3. **训练数据:** GPT-4o可能利用了更新、更大规模的训练数据集,涵盖了更多的领域和语言,提高了模型的广泛性和准确性。1. 模型压缩和优
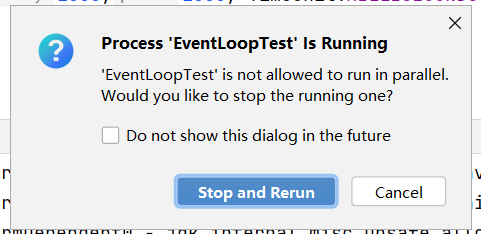
在学习Netty使用IDEA时会遇到需要启动2次及以上相同的java程序,但是当我直接在IDEA中运行的时候他会提示我已经运行了,是否停止并重新运行(下图的状况)第一步:右键你要重复运行的类(前提已经在运行一个,不然是没有Edit的),然后找到Edit....第一个选型,allow multpile instances。
正则化、数据平衡、合适的训练目标、模型解释性、集成方法和迭代优化等方法可以帮助我们克服大模型幻觉问题,提高模型的性能和可靠性。在未来的研究和应用中,我们需要继续关注大模型幻觉问题,并不断探索更好的解决方法,以推动人工智能领域的进一步发展。然而,随着模型规模的增大,我们也逐渐发现了一个问题,即大模型的幻觉。不适当的训练目标:如果模型的训练目标与其实际任务不匹配,可能会导致幻觉的出现。合适的训练目标:

1. **参数规模:** GPT-4o在参数规模上有所优化,尽管具体的参数数量可能不如GPT-4庞大,但它通过更高效的训练和模型架构优化,达到了与GPT-4相似甚至更好的性能。在讨论GPT-4o时,我们首先需要了解其前身,即GPT-4,以及其之前的版本。3. **训练数据:** GPT-4o可能利用了更新、更大规模的训练数据集,涵盖了更多的领域和语言,提高了模型的广泛性和准确性。1. 模型压缩和优
正则化、数据平衡、合适的训练目标、模型解释性、集成方法和迭代优化等方法可以帮助我们克服大模型幻觉问题,提高模型的性能和可靠性。在未来的研究和应用中,我们需要继续关注大模型幻觉问题,并不断探索更好的解决方法,以推动人工智能领域的进一步发展。然而,随着模型规模的增大,我们也逐渐发现了一个问题,即大模型的幻觉。不适当的训练目标:如果模型的训练目标与其实际任务不匹配,可能会导致幻觉的出现。合适的训练目标: