
大模型工程师面试攻略:12个核心问题详解,助你拿下高薪offer!
本文详细解答了NLP算法工程师岗位面试中的12个核心问题,涵盖Word2Vec与BERT的区别、注意力机制、Transformer架构、BERT与GPT的差异、大模型预训练资源需求、参数高效微调技术(如LoRA)、推理优化方法以及多模态模型实现等。:在Decoder的自注意力层中,通过一个掩码矩阵,将当前位置之后的所有位置都遮盖掉(设置为负无穷,经Softmax后变为0)。:使用各自的编码器处理不
本文详细解答了NLP算法工程师岗位面试中的12个核心问题,涵盖Word2Vec与BERT的区别、注意力机制、Transformer架构、BERT与GPT的差异、大模型预训练资源需求、参数高效微调技术(如LoRA)、推理优化方法以及多模态模型实现等。内容从基础概念到高级技术,全面覆盖了大模型领域的关键知识点,为求职者提供系统性的面试准备指南,助力候选人获得高薪职位。
对标岗位
NLP算法工程师
薪资 30-60K 16薪
1. 问:解释一下Word2Vec和BERT在词表示上的根本区别。
答:
Word2Vec(如Skip-gram, CBOW) 生成的是静态词嵌入。每个词都有一个固定的向量表示,无论上下文如何。例如,“苹果”在“吃苹果”和“苹果手机”中拥有相同的向量。它无法解决一词多义问题。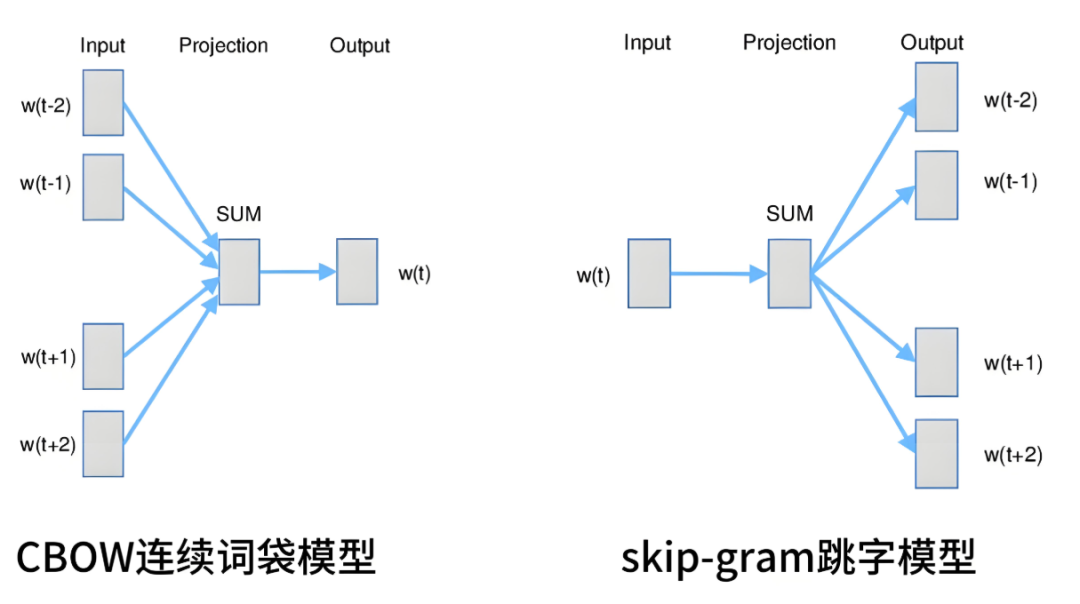
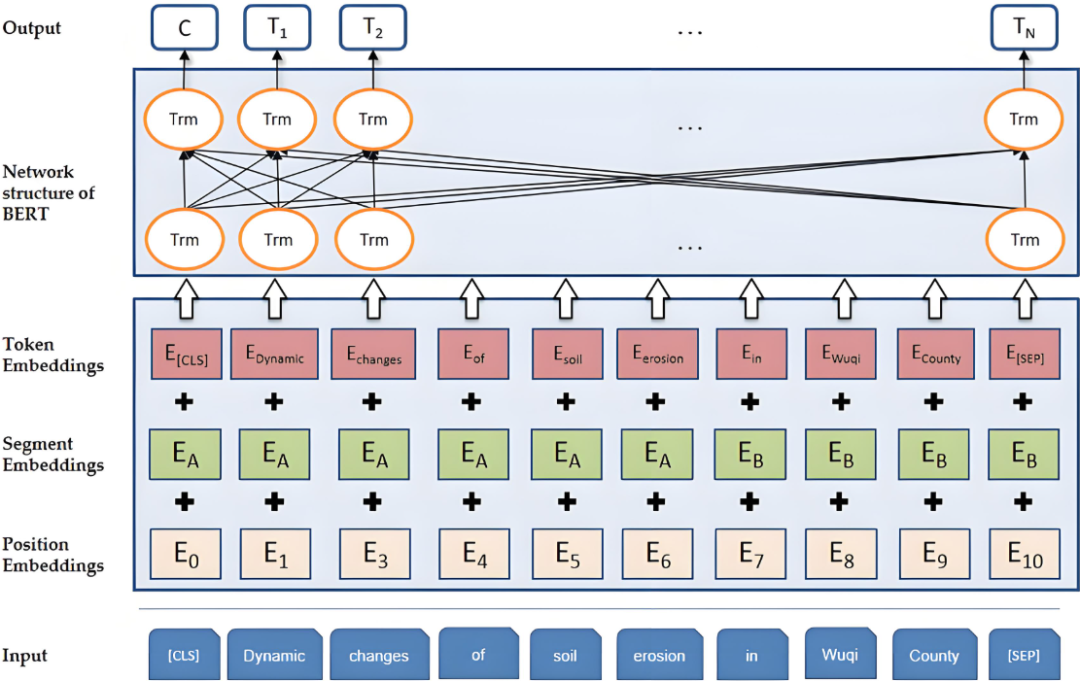
BERT 生成的是动态词嵌入。每个词的向量表示依赖于其所在的完整上下文。通过Transformer的双向编码,BERT能够为同一词在不同句子中生成不同的向量。例如,“苹果”在“吃苹果”和“苹果手机”中的向量是不同的。
2. 问:什么是注意力机制?它的核心优势是什么?
答:
核心思想:让模型在处理序列数据时,能够“关注”到与当前输出最相关的输入部分。它是一种加权求和机制,权重由模型自动学习。
核心优势:
-
解决长程依赖问题:相比RNN,注意力机制可以直接捕获序列中任意两个位置之间的关系,不受距离限制。
-
可解释性:通过观察注意力权重的分布,可以直观地看到模型在做决策时关注了哪些输入信息。
-
并行化计算:不像RNN那样必须串行计算,效率更高。
3. 问:为什么Transformer模型抛弃了RNN/CNN而选择自注意力(Self-Attention)?
答:
RNN的缺陷:难以并行化(依赖上一时刻的输出),存在梯度消失/爆炸问题,处理长序列时容易遗忘早期信息。
CNN的缺陷:捕获远距离依赖需要堆叠很多层,计算效率不高,且感受野受限
- 自注意力的优势:
-
极强的并行能力:序列中所有元素对的注意力分数可以同时计算。
-
全局视野:一层自注意力层理论上就可以捕获序列中所有元素之间的依赖关系,无论距离多远。
-
计算效率高:虽然理论复杂度是O(n²),但在实际硬件加速下,其对长序列的处理效率往往优于RNN。
4. 问:请详细解释Transformer中Encoder的结构。
答:
Transformer的Encoder由N个相同的层堆叠而成,每一层包含两个核心子层:
-
多头自注意力层:对输入序列进行自注意力运算,捕获序列内部的关系。
-
前馈神经网络层:一个简单的全连接网络,对每个位置的表示进行非线性变换。
每个子层都遵循以下设计:
-
•
残差连接:子层的输出是
LayerNorm(x + Sublayer(x))。这有助于缓解深层网络的梯度消失问题。 -
•
层归一化:对每个样本的特征维度进行归一化,稳定训练过程。
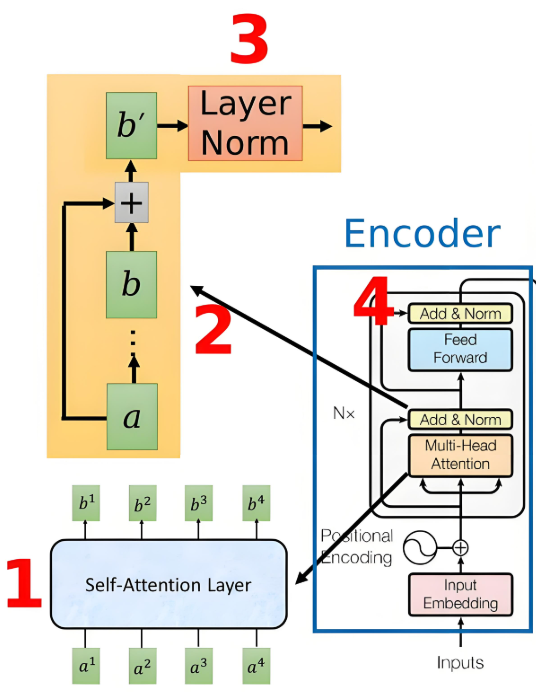
1、首先将带有位置信息的Embedding形式的输入sequence a经过Multi-Head Attention处理成sequence b;
2、Add:将Multi-Head Attention的input a和output b相加得到b’;
3、Norm:将b’进行Layer Norm规范化处理;
4、为了增强模型表示能力,将上一步产生的结果递交给两层全连接的FFN,第一层ReLU激活,第二层线性激活,然后继续Add&Norm处理;
5. 问:Decoder中的“掩码自注意力”是什么?为什么需要它?
答:
是什么:在Decoder的自注意力层中,通过一个掩码矩阵,将当前位置之后的所有位置都遮盖掉(设置为负无穷,经Softmax后变为0)。
为什么:为了确保在训练或推理时,模型在预测第t个词时,只能“看到”第1到t-1个词的信息,而不能“偷看”未来的答案。这是为了模拟自回归生成的过程,保证训练和推理的一致性。
6. 问:BERT和GPT在模型架构和目标上有何本质区别?
| 特性 | BERT | GPT |
| 模型架构 | 双向 Transformer Encoder | 自回归 Transformer Decoder |
| 预训练目标 | 遮蔽语言模型,下一句预测 | 自回归语言模型(给定上文,预测下一个词) |
| 代表 | BERT, RoBERTa | GPT系列, LLaMA, Bloom |
| 特点 | 更适合理解类任务(如文本分类、NER) | 更适合生成类任务(如文本生成、对话) |
7. 问:大模型预训练通常需要多大的数据量和计算资源?
答:
数据量:通常是TB级别的文本数据,例如GPT-3是在高达45TB的文本数据上训练的。
计算资源:需要成千上万颗高端GPU(如A100/H100)或TPU,训练时间可能长达数周甚至数月。例如,GPT-3的175B模型训练一次的成本高达数百万美元。
8. 问:全量微调(Full Fine-tuning)和参数高效微调(PEFT,如LoRA)有什么区别?
答:
全量微调:更新预训练模型的所有参数。优点:性能潜力最大。缺点:计算和存储成本极高,每个任务都需要保存一份完整的模型副本,易发生“灾难性遗忘”。
参数高效微调:只更新一小部分新增的参数,冻结原始预训练模型。以LoRA为例,它在原始线性层旁注入一个低秩矩阵(B*A),只训练这些小的矩阵,训练后将它们合并回原模型。
优点:极大降低计算和存储需求(可减少90%以上),训练速度快,多个任务适配器可以共享一个基座模型,避免遗忘。
缺点:性能可能略低于全量微调。
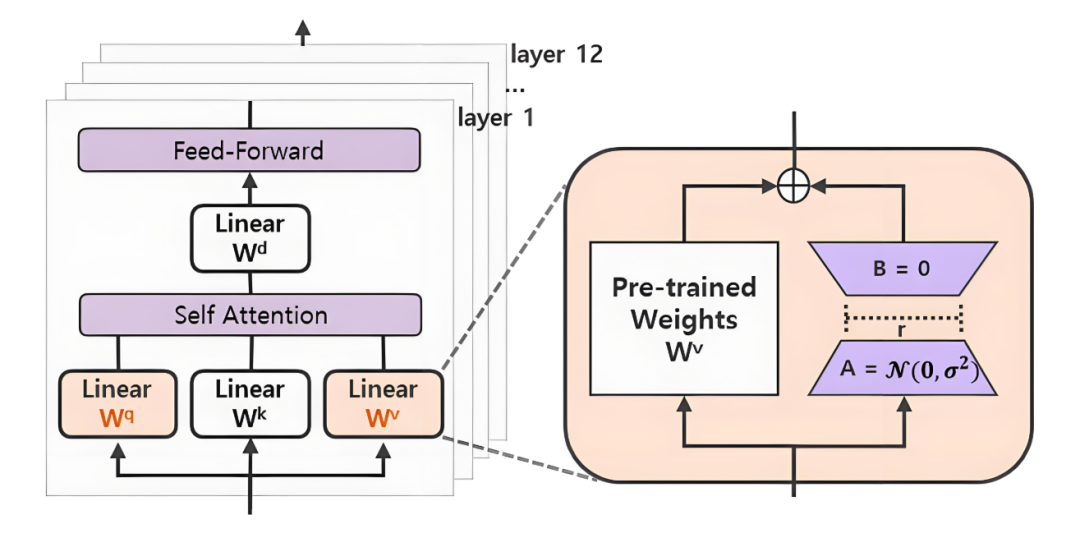
9. 问:除了LoRA,你还了解哪些PEFT技术?
答:
Adapter:在Transformer的FFN层后插入一个小型神经网络模块。
Prompt Tuning:只在输入侧添加一些可学习的“软提示”向量,通过调整提示来激发模型的能力。
QLoRA:LoRA的量化版本,将预训练模型量化为4-bit,进一步降低显存需求。
10. 问:如何优化一个大模型的推理速度?有哪些常用技术?
答:
模型层面:
量化:将FP32的模型权重转换为INT8/INT4等低精度格式,大幅减少显存占用和加速计算。
剪枝:移除模型中不重要的权重或连接。
知识蒸馏:用一个大模型(Teacher)来训练一个小模型(Student),让小模型学习大模型的行为。
推理引擎/框架:
使用专用推理框架:如TensorRT, ONNX Runtime, DeepSpeed等。它们会对计算图进行优化、算子融合(如将GEMM和激活函数融合)等。
硬件:使用高性能GPU、AI加速卡(如NPU)或专门优化的CPU。
11. 问:解释一下KV Cache的原理及其作用。
答:
问题:在自回归生成中(如GPT),生成第t个token时需要计算注意力,其中Key和Value矩阵是之前所有t-1个token的计算结果。如果不缓存,每次生成都需要为所有历史token重新计算K和V,计算浪费严重。
解决方案:KV Cache。将之前所有时间步计算出的Key和Value存储下来。生成第t个token时,只需计算当前新token的K和V,并与缓存的历史KV拼接,然后计算注意力。
作用:极大减少了重复计算,显著提升推理速度。代价是需要额外的显存来存储这些KV Cache。
12. 问:多模态大模型(如GPT-4V)在技术上是如何实现的?
答:
核心思想是将不同模态的信息映射到同一个表示空间。
-
编码:使用各自的编码器处理不同模态的输入(如ViT处理图像,BERT处理文本),将它们转换为同一空间的特征向量。
-
融合:通过一个融合模块(如Cross-Attention)让不同模态的特征进行充分交互。
-
解码:根据任务需求,使用解码器生成文本或其它输出。
整个过程通常在一个庞大的Transformer架构中进行端到端的预训练。
面试不仅是技术的较量,更需要充分的准备。我们精心整理l大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

大模型面试题解析文档+全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以
微信扫描下方CSDN官方认证二维码,免费领取【保证100%免费】

更多推荐

 4
4 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)