- @m0_53227534
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码
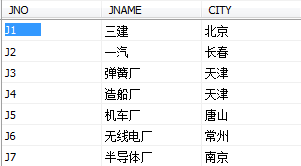
2、供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目
实验环境:windows11 matlab2018b实验有借鉴成分,注意!!!一、实验目的:1.了解图像降质/复原处理的模型。2.了解估计降质函数的基本原理。3.掌握降质图像中常见噪声模型及参数估计方法、基本原理、实现步骤。4.加深对几种常用的图像复原方法的理解。二、实验原理:图像复原的前提是图像退化,图像退化是指图像在形成、记录、处理、传输过程中由于成像系统、记录设备、处理方法和传输介质的不完善

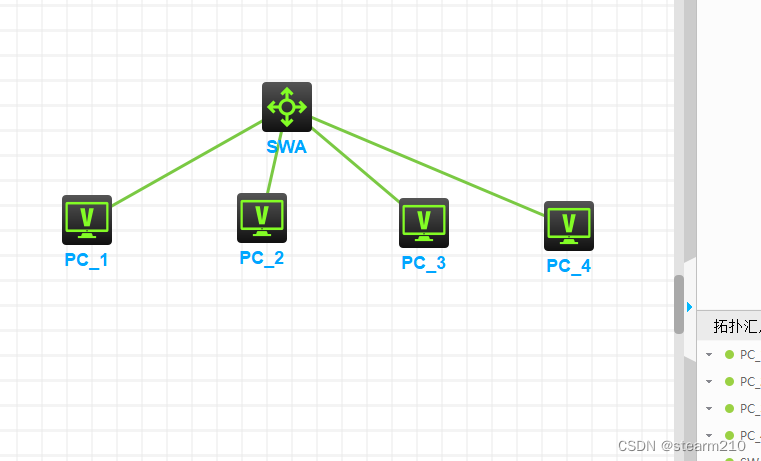
而VLAN能限制个别用户的访问,控制广播组的大小和位置,甚至能锁定某台设备的MAC地址,因此VLAN能确保网络的安全性。由于设置了vlan100,1和2,3和4之间还是可以连接,但是由于vlan100删除,1和2默认会去到vlan1(默认局域网)中,这个时候3和4还在一个局域网中,暂时无法连接其它主机。端口可以属于多个VLAN,可以接收和发送多个VLAN的报文,可以用于交换机之间连接,也可以用于连
第8关:建立2020级做了1001号题且result为6的选手视图v_user2020_1001_6,包括user_id、name、result、problem_id,且按user_id升序排序,注意user_id、name、result、problem_id构成的记录去重。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供
环境:windows 11编译器:devc++ 5.11注意,实验有借鉴部分!!!!一.实验目的与要求1.使用C、C++完成任务的程序编写;2.使用实验所提供的模板撰写实验报告,要求内容详实,有具体的设计描述、关键的 代码片段、及实验结果屏幕截图;二.实验内容与方法文法(Grammar)是描述高级语言语法结构的重要工具。定义任意的文法G,需要完成 对其四元组(V,T,P,S)的定义(课本P33)。

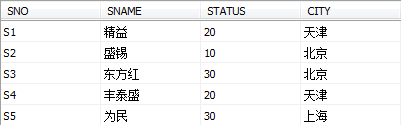
2、供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目代码(JNO)、供应数量(QTY)组成,标识某供应商 供应某种零件 给某工程项目的数量为QTY。供应情况表SPJ由供应商代码(SNO)、零件代码(PNO)、工程项目
实验目的:通过实验掌握下列知识:① 了解常用网络命令的工作原理,并掌握常用网络命令的使用。② 了解双绞线的布线标准,掌握测线器的使用方法。③ 掌握直通式双绞线和交叉式双绞线的制作方法。
假设音乐数据库里面现在有几张如下简化的数据表: 关注follow表,第一列是关注人的id,第二列是被关注人的id,这2列的id组成主键 +---------+-------------+ | user_id | follower_id | +---------+-------------+ | 1 | 2 | | 1 | 4 | | 2 | 3 | +---------+-------------

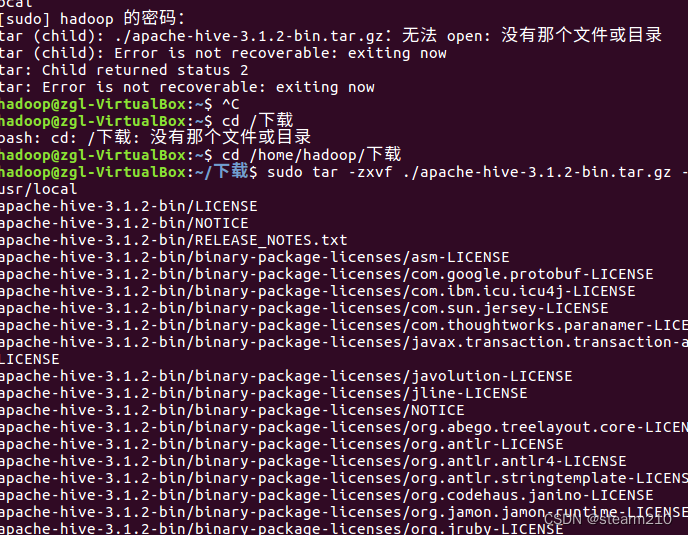
但是使用java编写的时候,将会调用各种包,之前还需要进行各种包的导入以及代码的编写,远远没有wordcount便利简洁。1.在使用hive的时候,可以比mapreduce使用更少的代码量,在mapreduce中需要实现产生jar包,但是在使用hive的时候不需要使用jar包。进行删除数据库的时候,需要匹配对应的路径才可以。一组无序的键值对,键的类型必须是原子的,值可以是任何数据类型,同一个映射的