




- @m0_52695557
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
联邦学习(FL)在保护数据隐私和减轻移动边缘计算(MEC)网络中的网络负担方面具有巨大潜力。然而,由于移动客户端(MC)的系统和数据异质性,在带宽有限的 MEC 网络中实现成本高效的 FL,客户端选择和带宽分配是关键。为应对这些挑战,我们研究了联合客户端选择和带宽分配问题,以降低 FL 训练的成本(即延迟和能耗)。我们提出了该问题,并将其分解为一个整体子问题以减少轮次数量,以及一个部分子问题以减少
环境:Linux, Python=3.6.8, CUDA = 11.1, pytorch = 1.9.0, mmdet3d = 0.17.1。下载nuScenes数据集:需注册并下载nuScenes数据集,放置到data/nuscenes目录,我用的是mini进行测试。修改config文件的data路径,例如:·data_root = ‘xxxx/PETR/data/nuscenes/’·可以下载

在你的git init的本地仓库目录,执行命令。输入git.acwing的账号名和密码就能成功。使用https协议,不要使用ssh协议。然后把里面的url配置项从git格式。修改为https格式。

sigmod的函数是一个在生物学中常见的S型函数,也称为S型生长曲线。在信息科学中,由于其单增以及反函数单增等性质,常被用作神经网络的激活函数,将变量映射到0,1之间。-------------摘自《百度百科》sigmod函数也叫作Logistic函数,用于隐层神经单元输出,取值范围为(0,1),它可以将一个实数映射到(0,1)的区间,可以用来做二分类。在特征相差比较复杂或者相差不是特别大的时候效

用ASCII表作为词典,长度为128,每一个值对应一个独热向量,比如77对应128维向量中第77个位置为1其他位置为0,但是对于embed层只要告诉它哪个是1就行,这些序列长短不一,需要padding到统一长度。它会将填充后的嵌入和实际序列长度作为输入,并返回一个打包后的序列,便于 RNN 处理。,判断句子是哪类(0-negative,1-somewhat negative,2-neutral,3

嵌入层的主要作用是将离散的词汇映射到连续的向量空间中,从而为RNN提供密集的、低维的输入表示,这比直接使用稀疏的one-hot编码更为高效。,但是这个线性层是共享的,如下图,每次把hi和xi+1计算得到的hi+1传送到下一层进行计算,同时xi+1还需要通过某种运算融合xi的信息(比如求和、求乘积等)h0是先验知识,比如对于图像生成文本,可以先通过cnn+fc生成h0,也可以把h0设成和h1等统一维

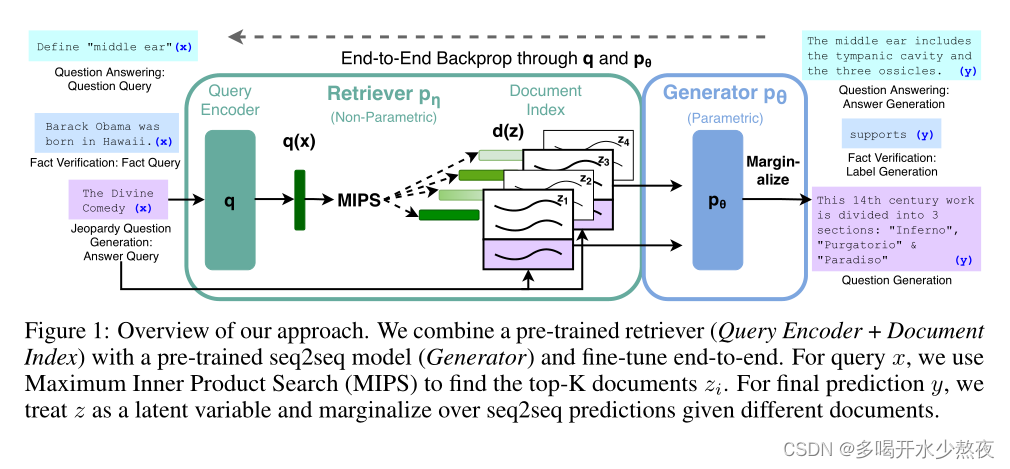
大型预训练语言模型已被证明可以在其参数中存储事实知识,并在对下游NLP任务进行微调时获得最先进的结果。然而,他们访问和精确操作知识的能力仍然有限,因此在知识密集型任务中,他们的性能落后于特定任务的体系结构。此外,为他们的决定提供出处和更新他们的世界知识仍然是悬而未决的研究问题。具有对显式非参数记忆的可微访问机制的预训练模型可以克服这个问题,但迄今为止只针对提取下游任务进行了研究。微调方法——该模型
安卓Button处于colorPrimary颜色,无法修改颜色的解决方案
前言之前下载node.js后在VScode上跟着视频敲代码的时候一直出现Cannot find module ‘express’,在网上找了半天,之后又问了学长才解决,所以还是打算记录一下吧。之前在网上看了很多全局的方法,但是还是没有解决,所以最后还是用局部方法来解决。问题在VScode终端输入的时候出现之后对比了学长的项目发现是因为我没有在项目中引入node_module这个文件(这个是在下载了