




- @m0_49651195
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
近年来,NLP从业者集中于以下实践:(i)导入现成的预训练(掩码)语言模型;(ii)在CLS令牌的隐藏表示(随机初始化权重)上附加多层感知器;(iii)在下游任务(MLP-FT)上微调整个模型。这一过程在标准的NLP基准上产生了巨大的收益,但这些模型仍然很脆弱,即使是轻微的对抗性扰动。在这项工作中,我们展示了通过提示进行模型调优(MVP)在对抗鲁棒性方面的惊人收获,这是一种适应下游任务的替代方法。

传统的通过语义相似性搜索将大型语言模型( Large Language Models,LLMs )与知识库链接的方法往往无法捕获复杂的关系动态。为了解决这些局限性,我们引入了AutoKG,一种轻量且高效的自动知识图谱( KG )构建方法。**对于给定的由文本块组成的知识库,AutoKG首先使用LLM提取关键词,然后使用图拉普拉斯学习评估每对关键词之间的关系权重。**我们采用了一种结合向量相似度和基

这一策略的独特之处在于,通过减少每个文档的内容量和筛选掉不相关的文档,它能更加集中地展示检索结果中的关键信息。为了确保模型能够理解用户查询与内容的相关性,对嵌入模型进行任务特定的微调至关重要,否则未经微调的模型可能无法满足特定任务的需求。在 Liu 于 2023 年提出的 LlamaIndex 中,研究者们通过在查询编码器后加入一个特殊的适配器,并对其进行微调,从而优化查询的嵌入表示,使之更适合特

为了测试指导模型增加对不同搜索结果片段注意力的有效性,我们设计了一系列在多文档问答(MDQA)任务(Singh等人,2021)下的实验,在该设置中,只有一个文档包含正确答案,即金文档。考虑到金文档可以出现在任何位置并可能因为位置偏差而被忽视,我们设计了注意力指令,这是一个由两个句子组成的指令,指导LLMs关注选定的片段,从而防止信息的忽视。输入提示和一些示例可以在图2中看到。

题目描述:给你一个链表的头节点head和一个整数val,请你删除链表中所有满足的节点,并返回。示例1:示例2:遍历整个链表,找到数据域等于题目给出数据的节点,直接删除。由于我使用的是Python所以不用额外free节点,如果使用别的语言要注意一下free操作。本题的大体思路较为简单。但还是有个难点,如果要删除的节点是头结点要怎么办?这里我们可以采用设置一个虚拟头节点的方式。也就是说,我们可以先设置
本研究的核心目的是在信息检索任务中提出一种新的检索范式,即在有限的示例支持下实现有效的信息检索。研究者们提出通过“Promptagator”方法来放大少量示例的能力,帮助模型在多样化的检索任务中进行有效的学习和推理。实验结果显示,使用“Promptagator”方法的模型在多项检索任务中均取得了优于其他方法的效果,尤其是在数据稀缺的场景下,其优势更为明显。通过以上各方面的详细分析,可以看出“Pro

这篇论文提出了“从简单到复杂提示”(Least-to-Most Prompting)这一新的提示策略,旨在解决大语言模型在解决比提示示例更复杂的问题时表现不佳的难题。从简单到复杂提示 结合了这两种提示方法的优点,通过分解提示将复杂问题分解成子问题,再通过思维链提示引导模型逐步解决这些子问题,最终得到问题的答案。的核心思想是将复杂问题分解成一系列更简单的子问题,每个子问题都比前一个子问题更容易解决。

现代生成模型的优势在于它们能够通过基于文本的提示进行控制。典型的“硬”提示由可解释的单词和标记组成,必须由人类手工制作。还有“软”提示,它由连续的特征向量组成。这些可以使用强大的优化方法发现,但是它们不能很容易地解释、跨模型重用或插入到基于文本的界面中。我们描述了一种通过有效的基于梯度的优化来稳健地优化硬文本提示的方法。我们的方法自动为文本到图像和文本到文本应用程序生成基于硬文本的提示。

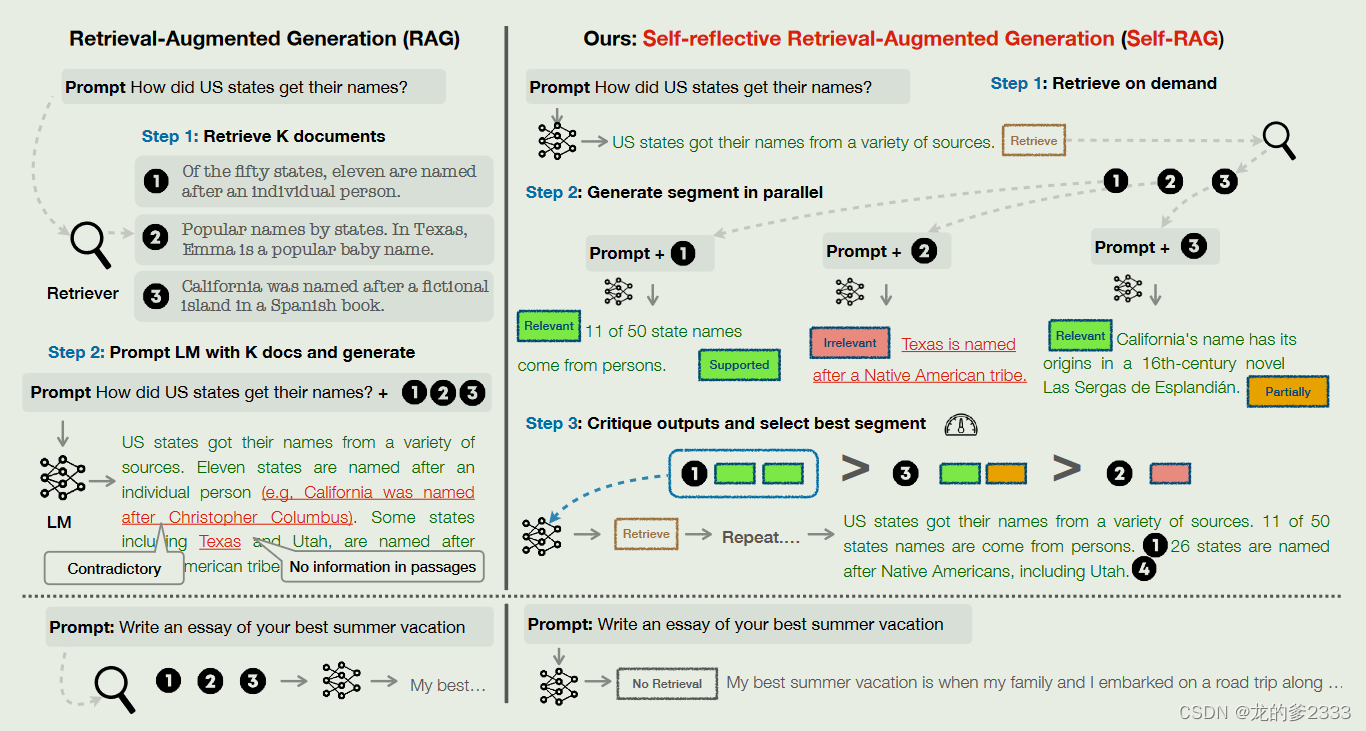
因此,在评估这次输出的IsSup(响应支持度)的分数时,就可以基于logprobs中这些tokens的概率来计算(上面例子中,显然[Fully supported]这个token的概率越高,说明支持度越高)。(就是假设LLM是一个优秀的学生,那么RAG就是一本参考书,这个问题就是LLM在考试的时候可以翻阅参考书,但是选取的知识点用来解答问题不是考题所涉及的知识点,所以最终会导致回答错误)比如提供的
ReAct是一种将推理和行动与LLM相结合的通用范式。ReAct 是一个很有潜力的方法,它将推理和行动结合起来,为解决各种语言推理和决策任务提供了新的思路。本文首先认为,到目前为止,LLM 在语言理解方面令人印象深刻,它们已被用来生成 CoT(思想链)来解决一些问题,它们也被用于执行和计划生成。引入一个名为ReAct的框架,在这个框架中,LLM被用来以交互的方式生成“合理的推理轨迹”以及“特定于任
