- @m0_46677695
简介
该用户还未填写简介
擅长的技术栈
可提供的服务
暂无可提供的服务
(建议看我的,因为我都整理好了,而且代码注释的很详细。想看源码的话可以去官网)传统的图像处理都是用的卷积,直到多头注意力机制横空出世,NLP取得飞跃发展。有机智的学者发现,将其应用到图片处理…Vision Transformer (ViT) 是一种基于 Transformer 的图像分类模型,其核心思想是将图像切分成小的 patch(图像块),然后将每个 patch 当作序列输入 Transfor
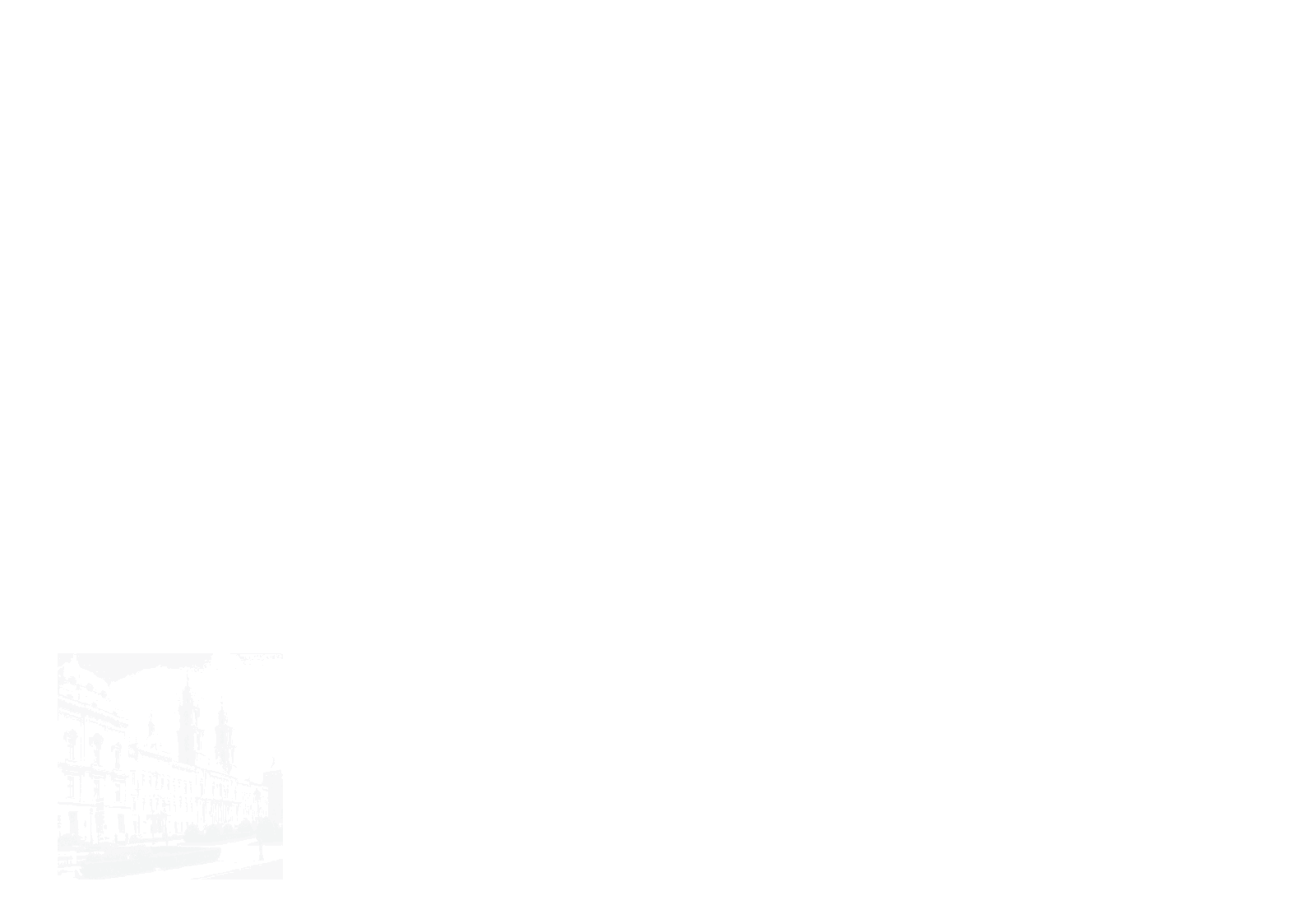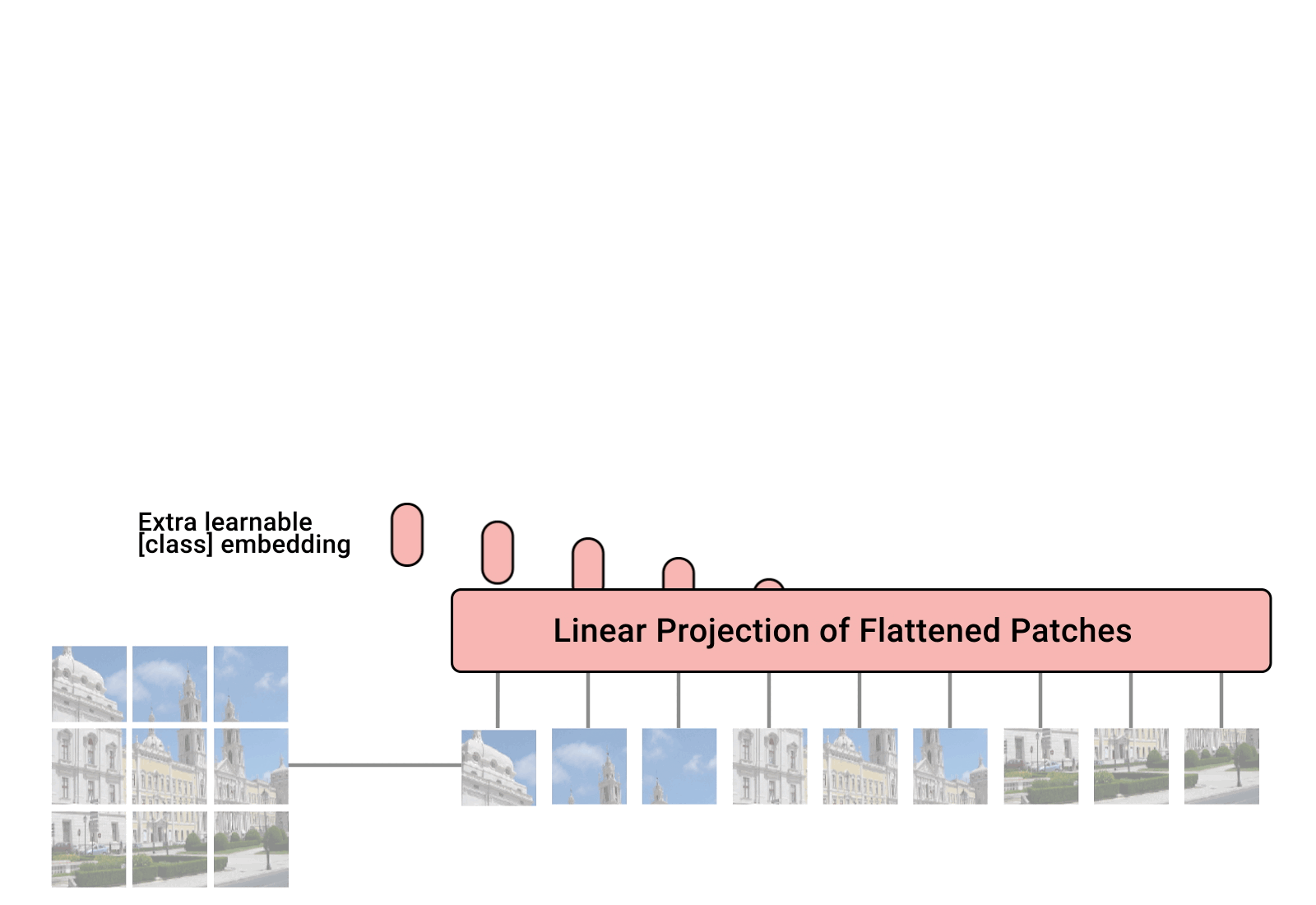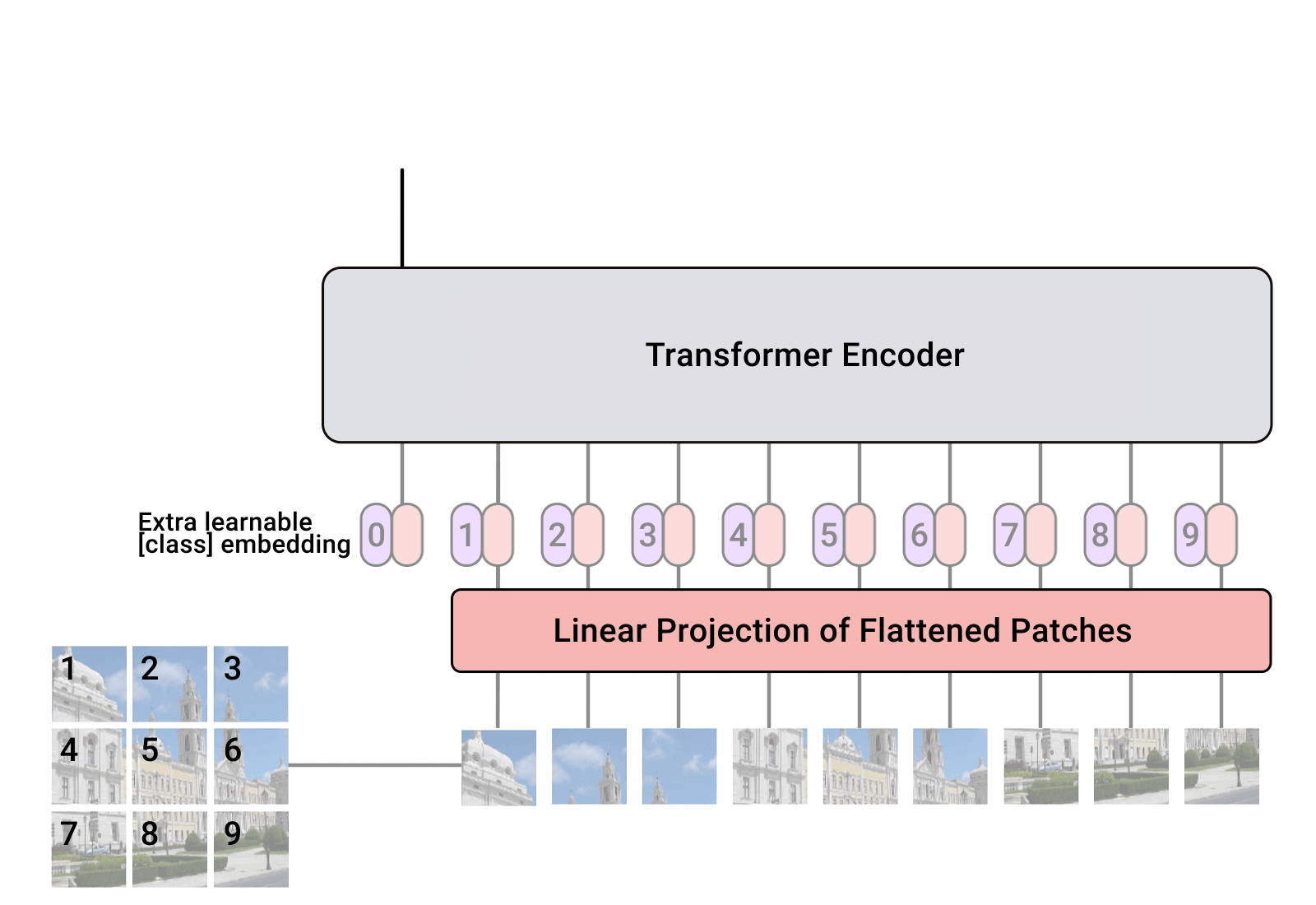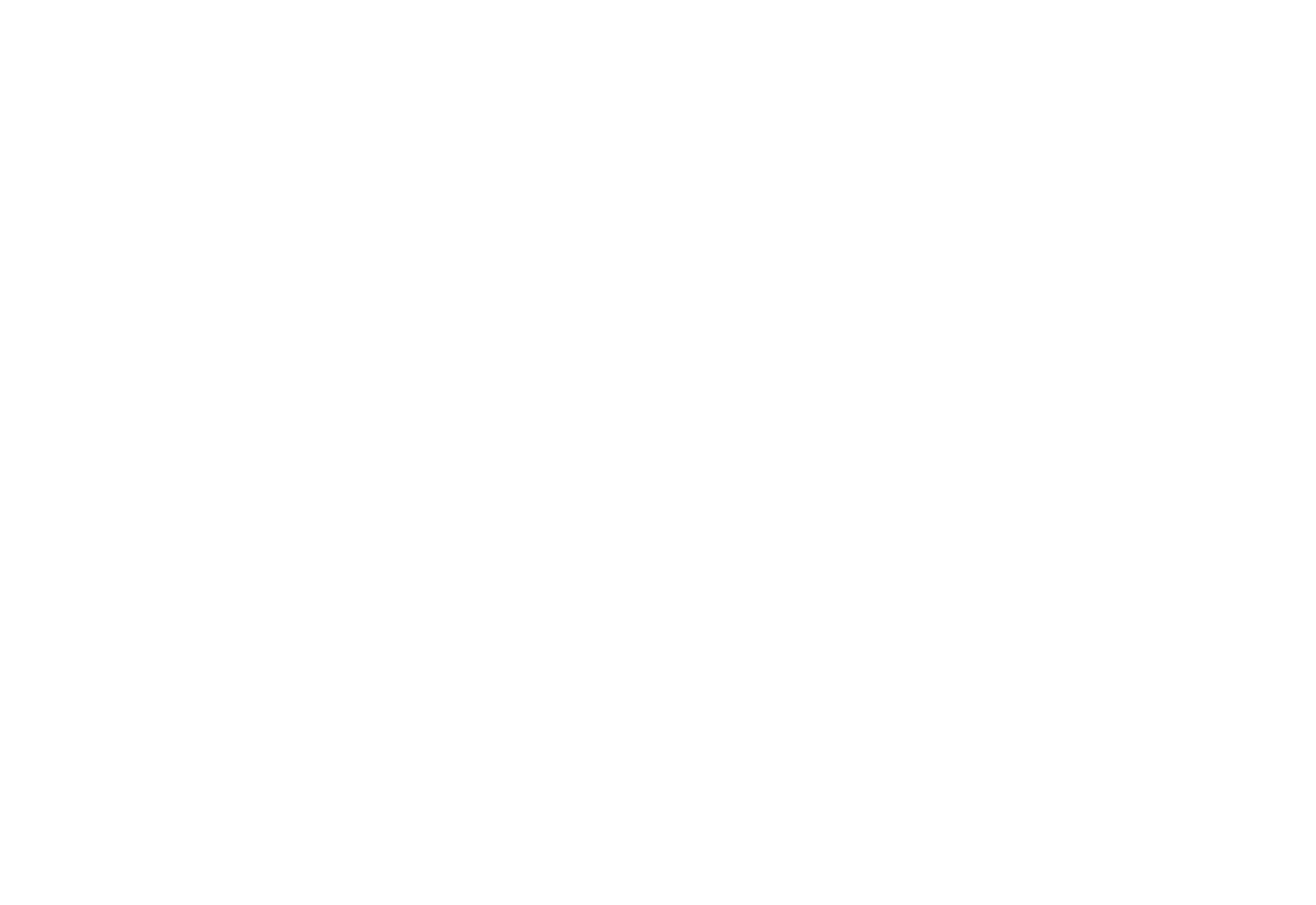
(建议看我的,因为我都整理好了,而且代码注释的很详细。想看源码的话可以去官网)传统的图像处理都是用的卷积,直到多头注意力机制横空出世,NLP取得飞跃发展。有机智的学者发现,将其应用到图片处理…Vision Transformer (ViT) 是一种基于 Transformer 的图像分类模型,其核心思想是将图像切分成小的 patch(图像块),然后将每个 patch 当作序列输入 Transfor
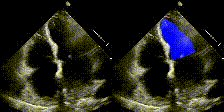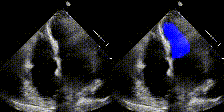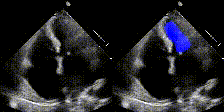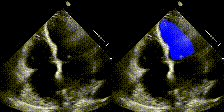
所以对于模型的话没有什么可以学的点,不过很适合初学者学会如何把现有的模型应用到自己数据集,做自己的项目。代码链接:https://github.com/xiaoxijio/deeplabv3_resnet50-Echocardiographic-image-segmentation(自己复现的代码,注释非常详细,如果要看源码可以去官网查看)数据集夸克链接:https://pan.quark.cn/
Deformable DETR目标检测模型
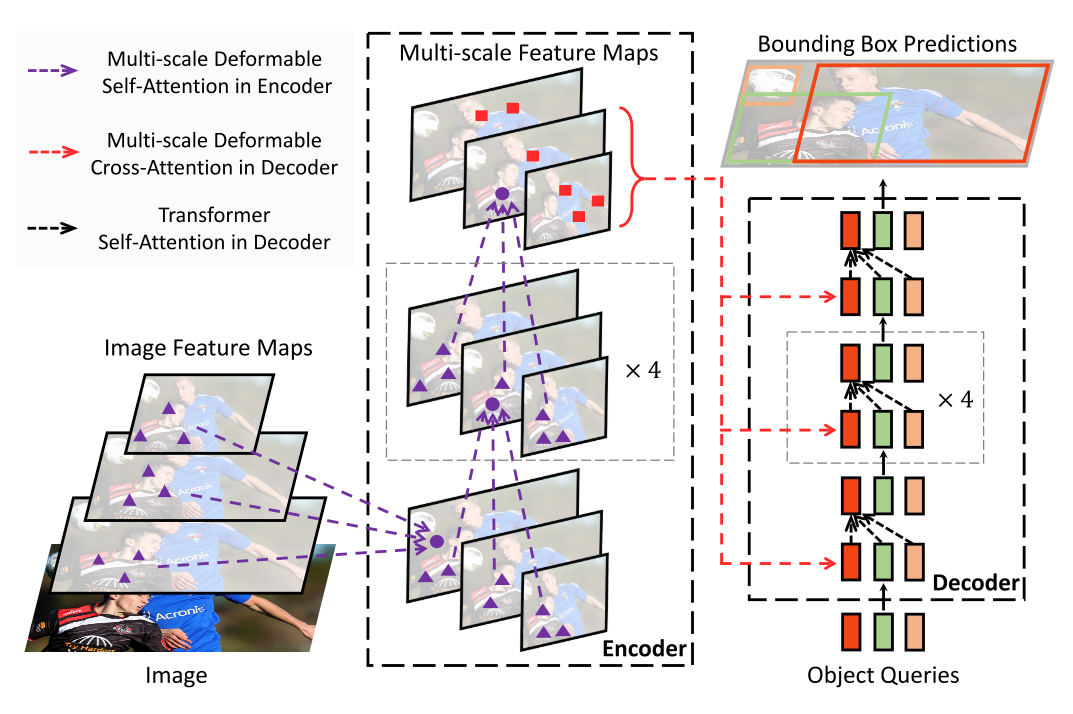

DETR(DEtection TRansformer)是一种基于Transformer的目标检测模型,它抛弃了传统目标检测中的手工设计流程(如候选框生成和NMS),实现了端到端的检测框架。

这次用的数据集是market1501,这是一个清华校园的数据集,比较小,我们来看一下这个数据集。这个数据集前面的内容截取的不是很好,得往后拖拖,我们来看这个绿色衣服的。首先前面的00000202代表ta的行人ID,一共有1500个ID。后面的0001-0006都是摄像头的编号,一共有6个摄像头。接着摄像头后的编号为当前摄像头下的图像编号。比如00000202_0004_00000003.jpg表示
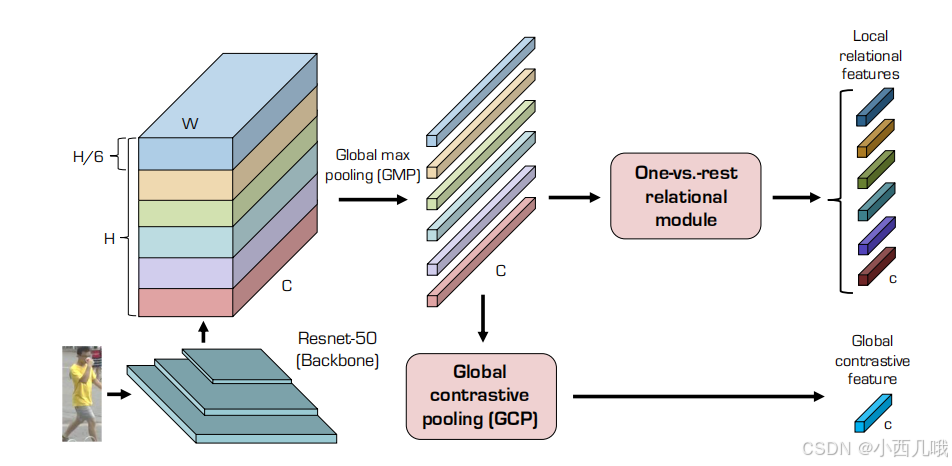
老规矩,先看一下效果。

看一下效果。

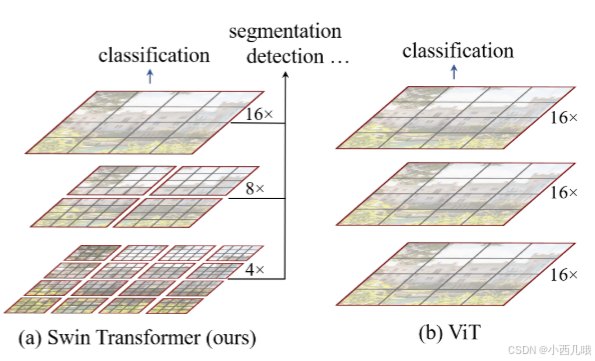
Swin Transformer